Sesión 1: Planteando y respondiendo preguntas con datos.
Curso: Análisis de datos
El proceso de la ciencia de datos
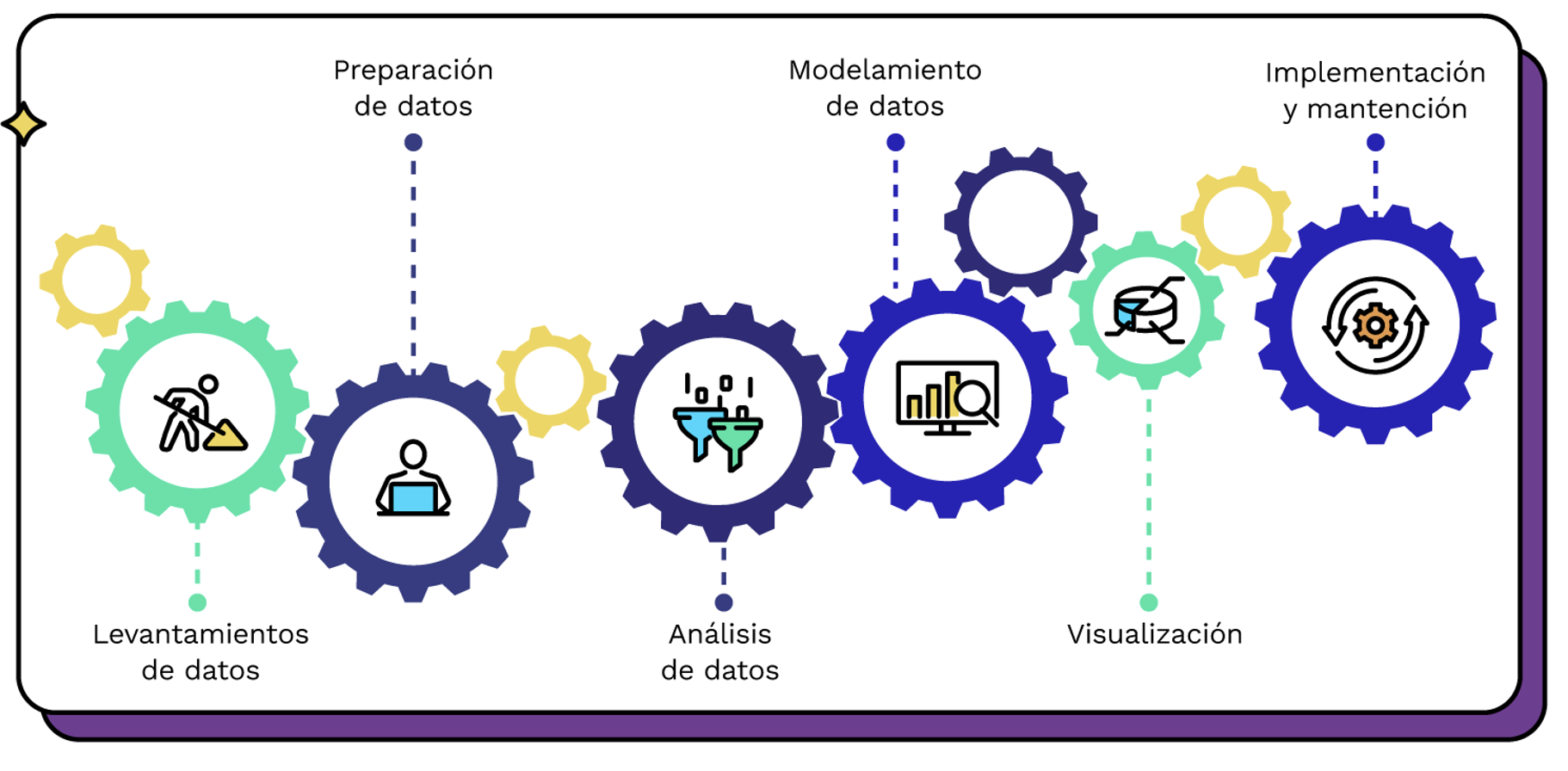
El proceso de la ciencia de datos
En este curso nos enfocaremos en:
- La preparación de los datos
- Análisis mediante modelos de regresión
El objetivo: dar valor
- Esto con el objetivo de responder preguntas desde los datos, que provean información valiosa.
Datos desde la API del banco mundial
Ejemplo
Ahora, realicemos un grafico rápido con nuestros datos:
Abstrayendo la realidad
El proceso de abstraer la realidad
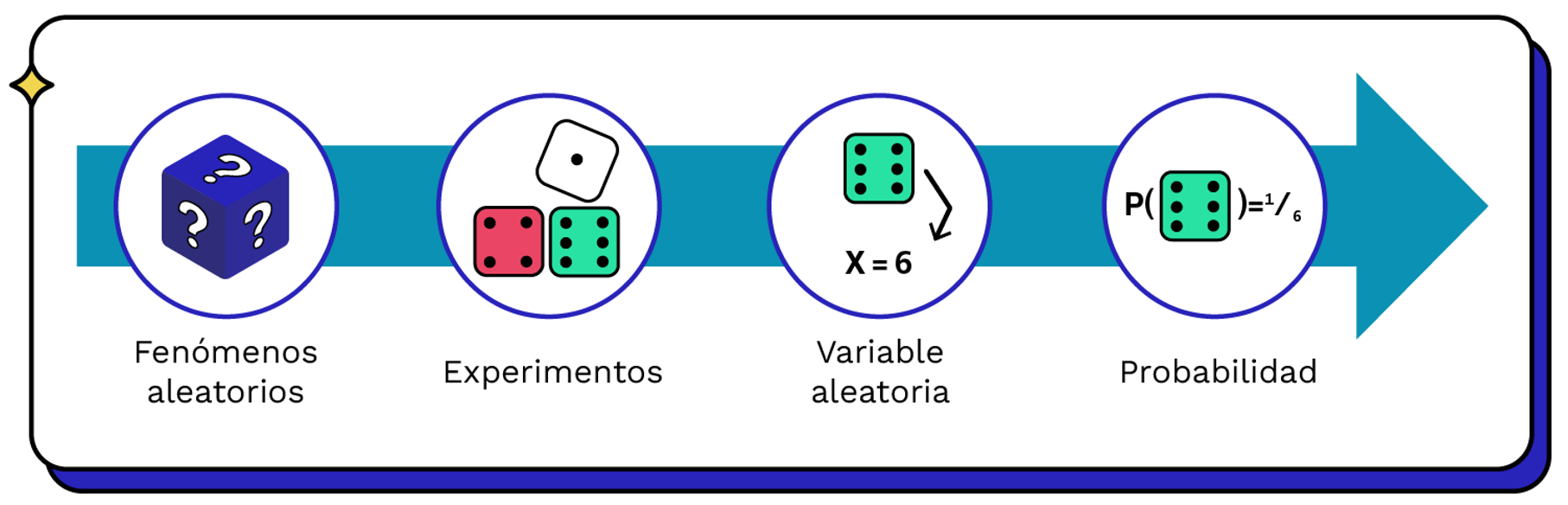
Respondiendo desde los datos
Inferencia estadística
Inferencia se refiere al proceso de hacer generalizaciones de una población a partir de una muestra de esa población.
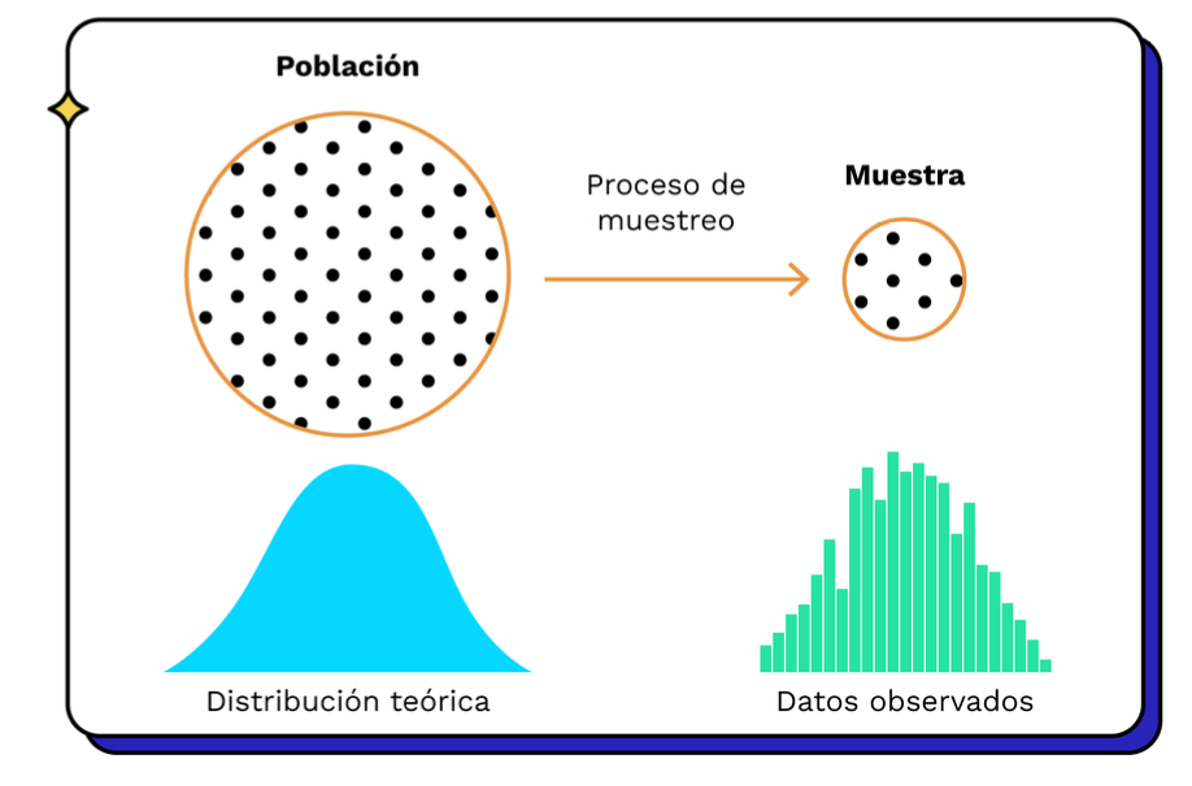
Población y Muestra
Estadígrafos
Funciones que aproximan parámetros
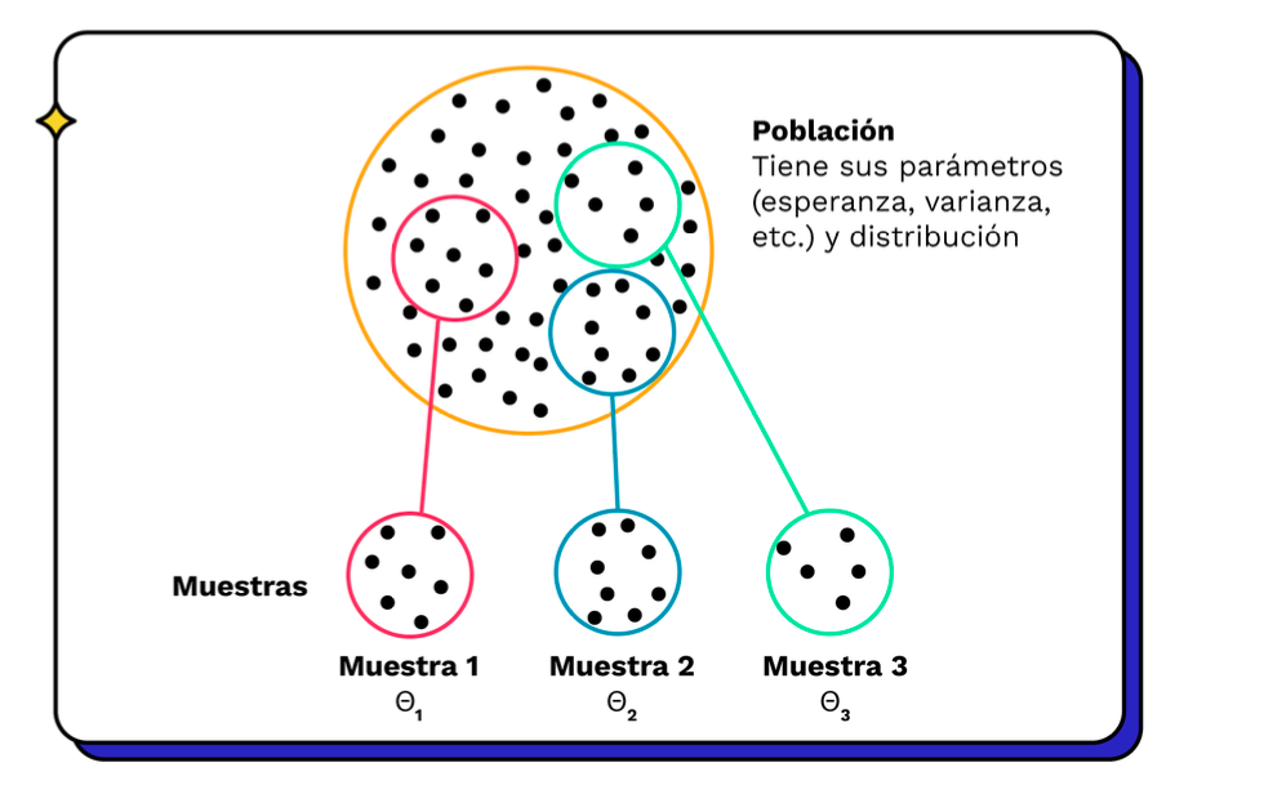
Estadigrafos
Estadígrafos
son variables aleatorias
- Dado que por cada muestra que tenemos, vamos a calcular un estadígrafo este es en si mismo una variable aleatoria.
- Tiene su propia distribución, media y varianza!
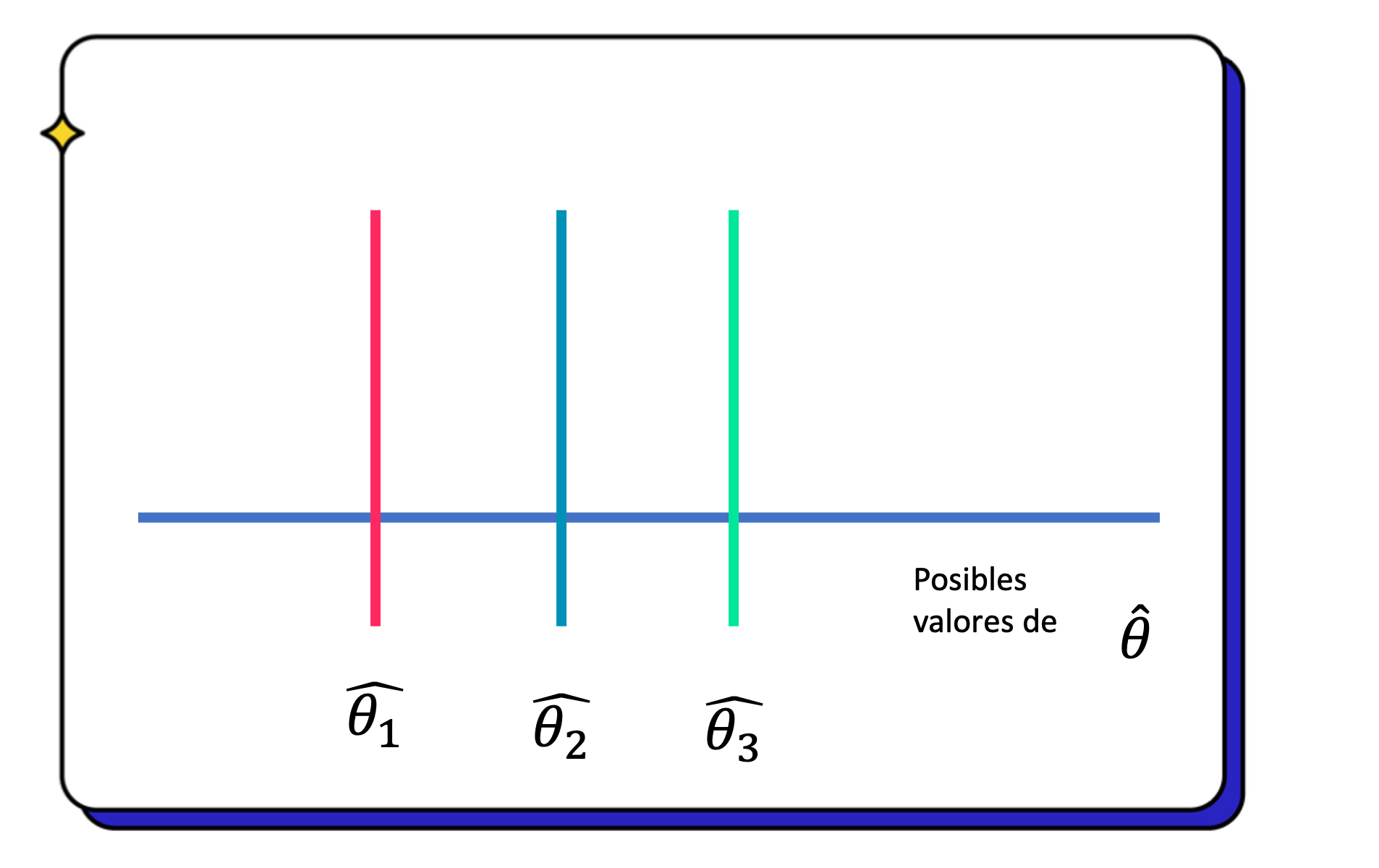
Estadígrafos
los más comunes
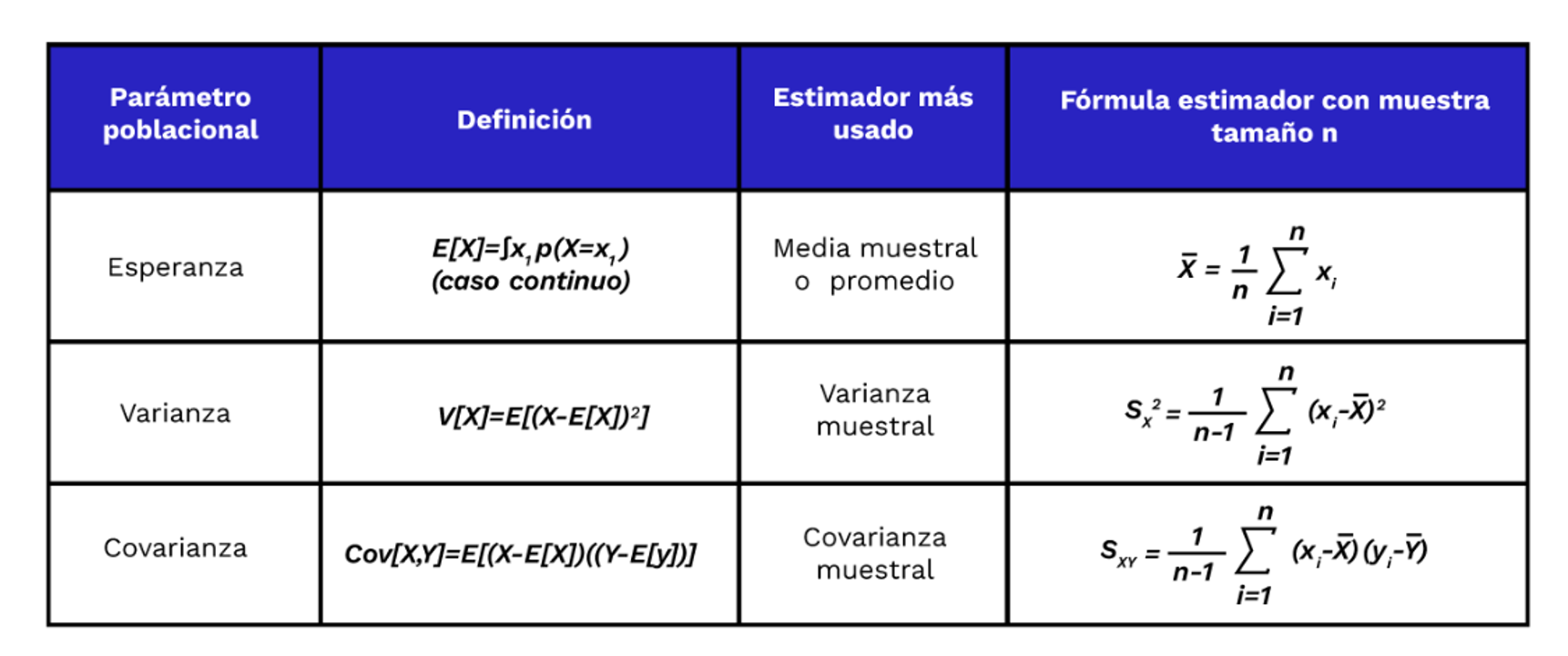
Estadigrafos más comunes
Estadígrafos y parámetros
Conectados por el Teorema del Límite central
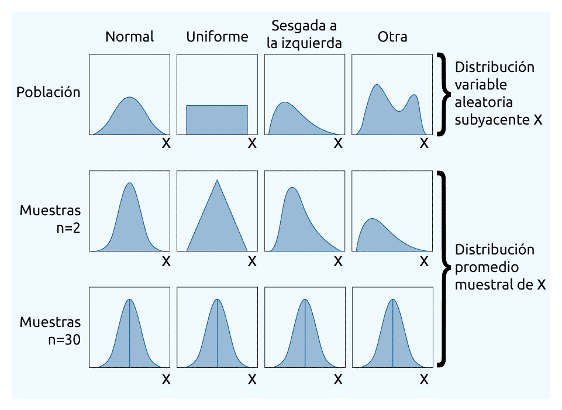
La media muestral se distribuye normal, sin importar la distribución de la variable subyacente
Estadígrafos y parámetros
Intervalos de confianza
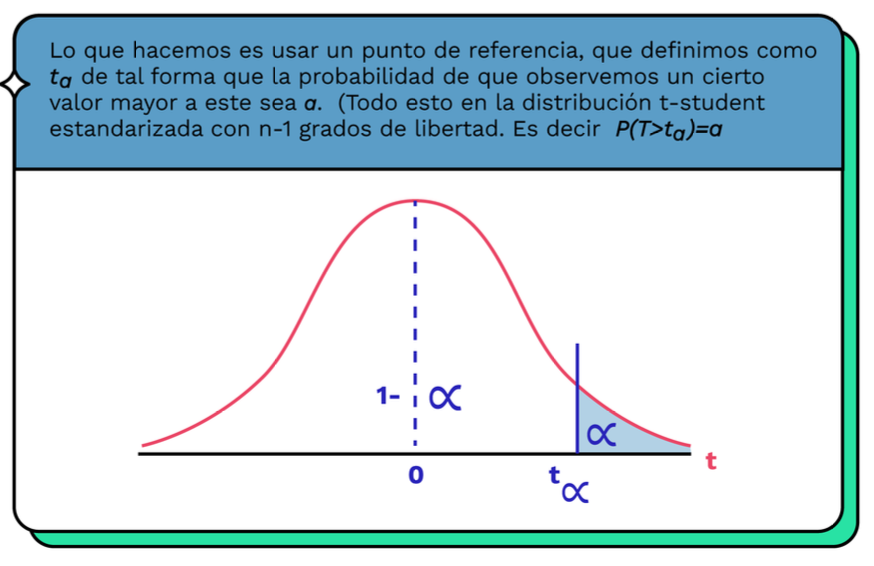
Estadígrafos y parámetros
Intervalos de confianza
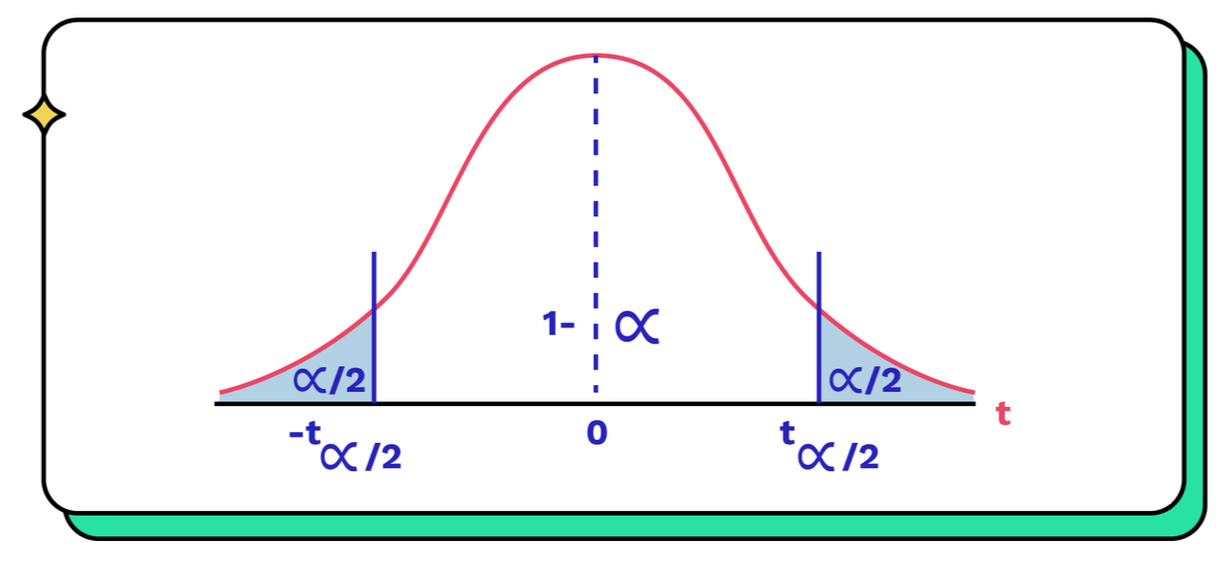
Estadígrafos y parámetros
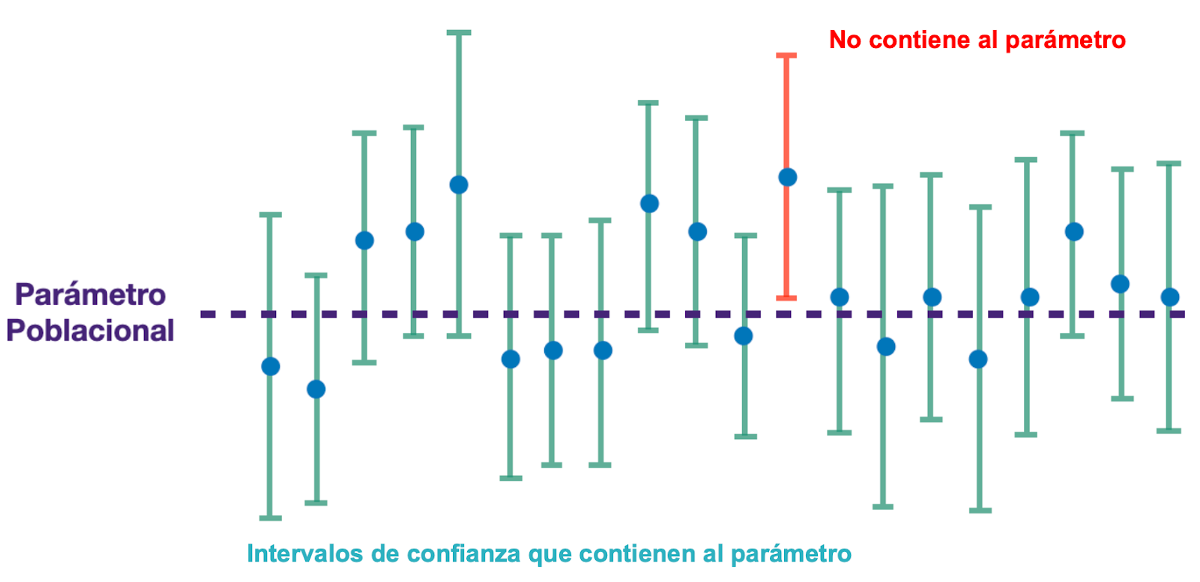
Intervalos de confianza
- Con 20 muestras, tenemos 20 intervalos.
![]()
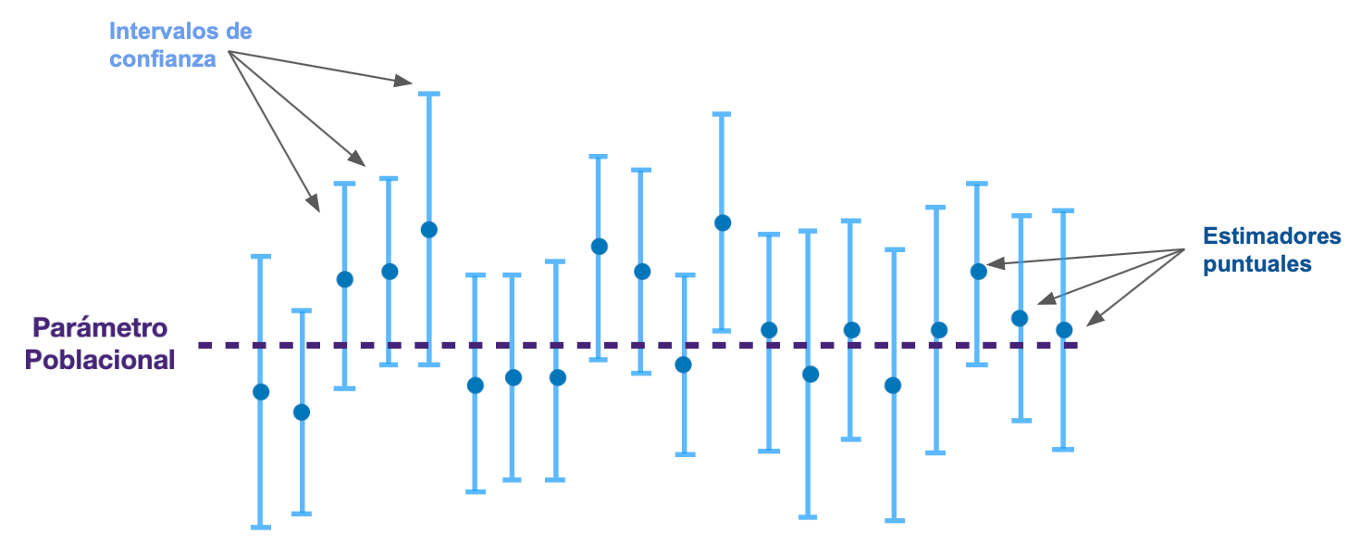
Estadígrafos y parámetros
Intervalos de confianza - Interpretación
- Al 95% de confianza con 20 intervalos 19 contendrán el parámetro.
Estadígrafos y parámetros
Pruebas de hipótesis
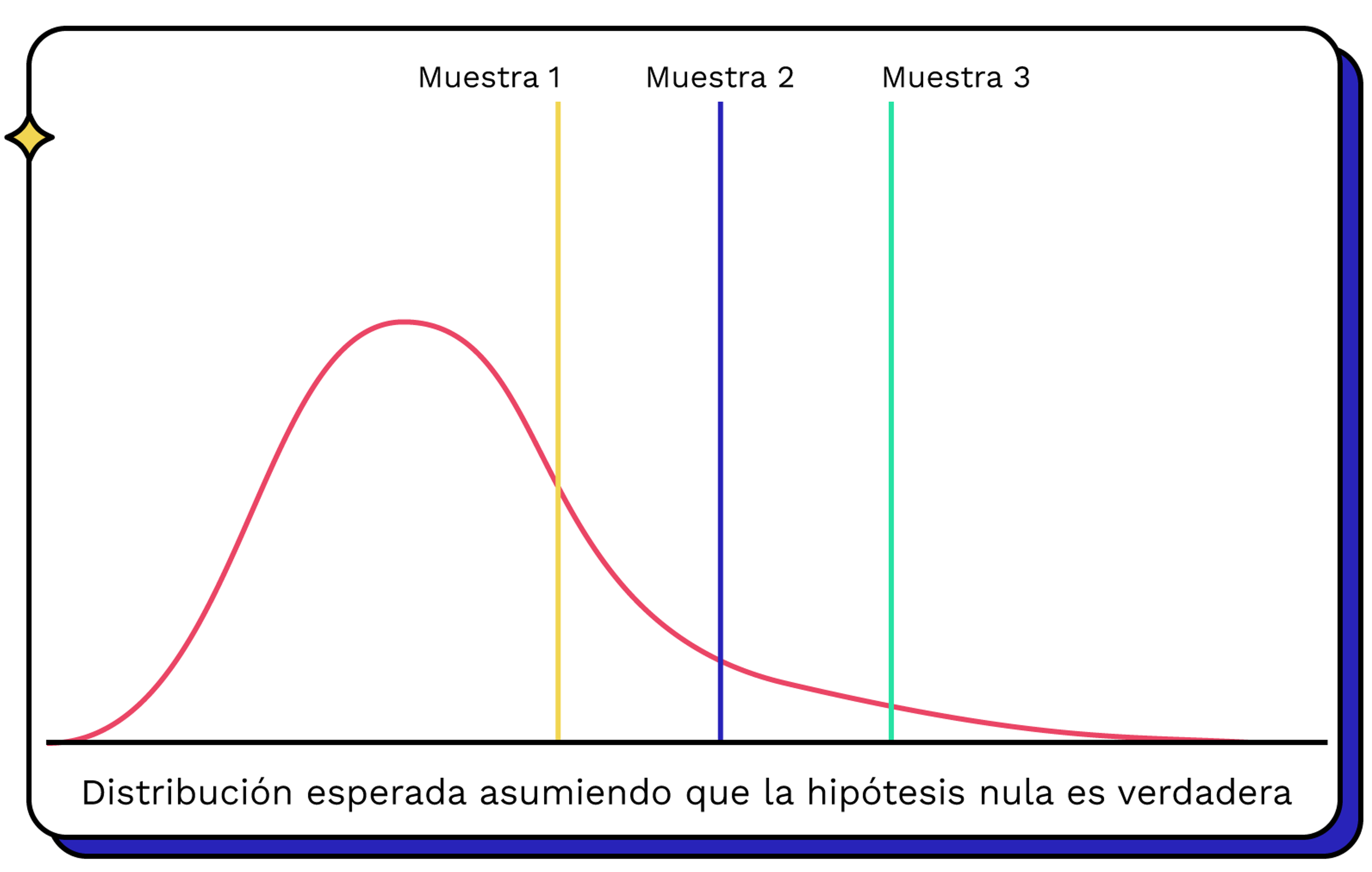
Una forma de verificar hipotesis sobre los parámetros es mediante el contraste de hipótesis.
Estadígrafos y parámetros
Pruebas de hipótesis
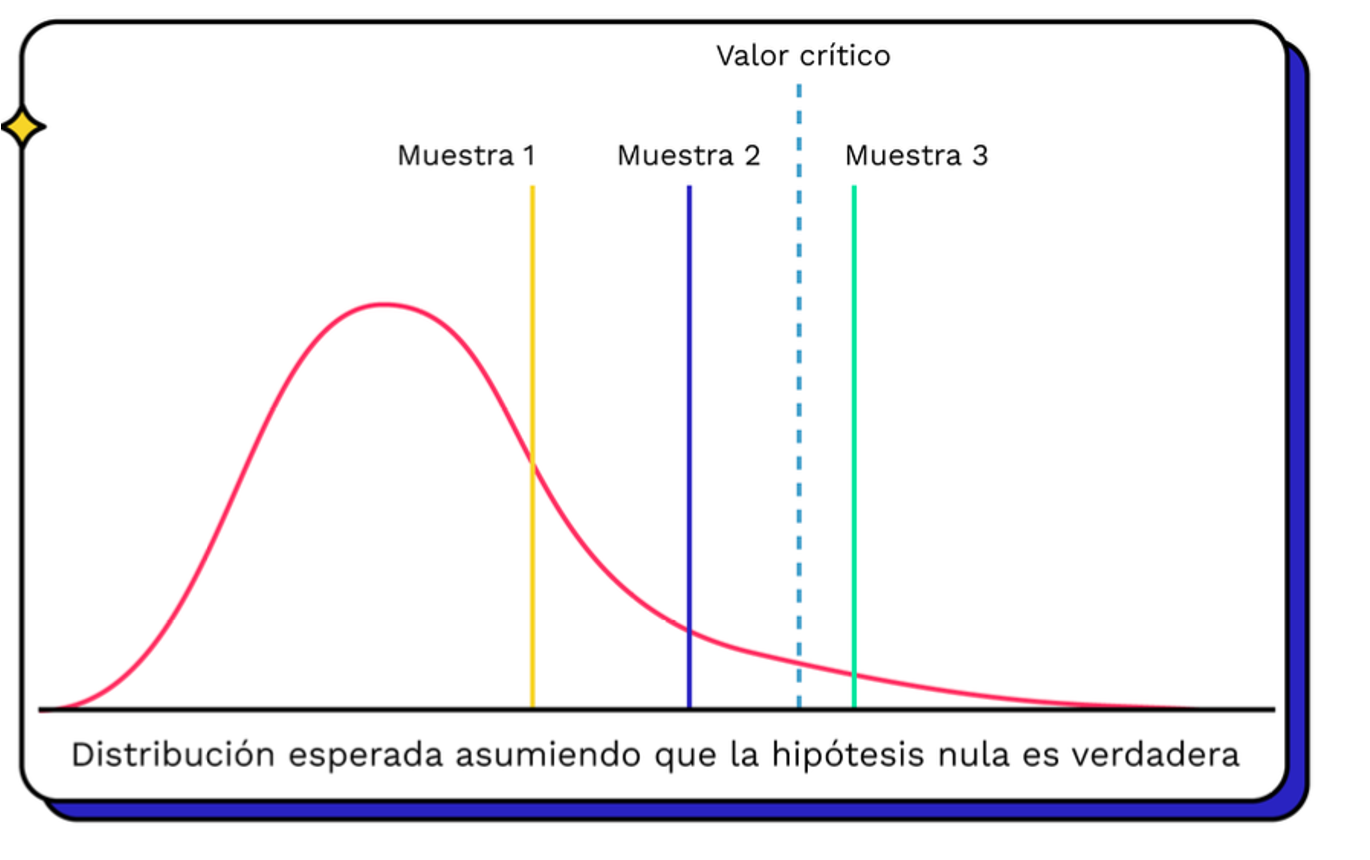
Empezamos suponiendo que hay una distribución conocida para el estadígrafo, centrada en un valor específico.
Estadígrafos y parámetros
Pruebas de hipótesis
Y nos preguntamos, si esto fuea verdad ¿qué tan probable es la muestra que tengo?
Estadígrafos y parámetros
Pruebas de hipótesis
Llamamos la hipótesis a probar Ho, y su alternativa H1.
Estadígrafos y parámetros
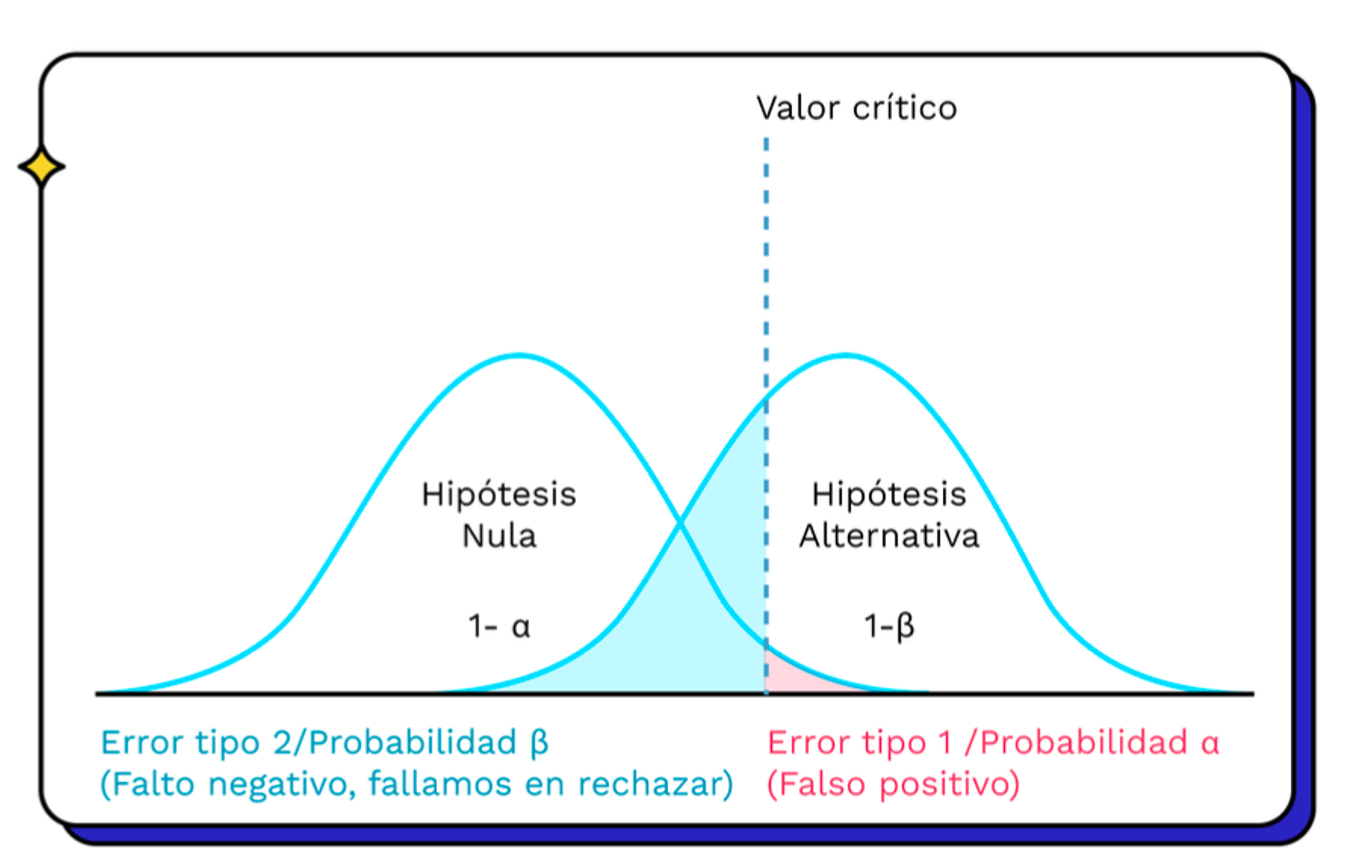
Errores y P-valor
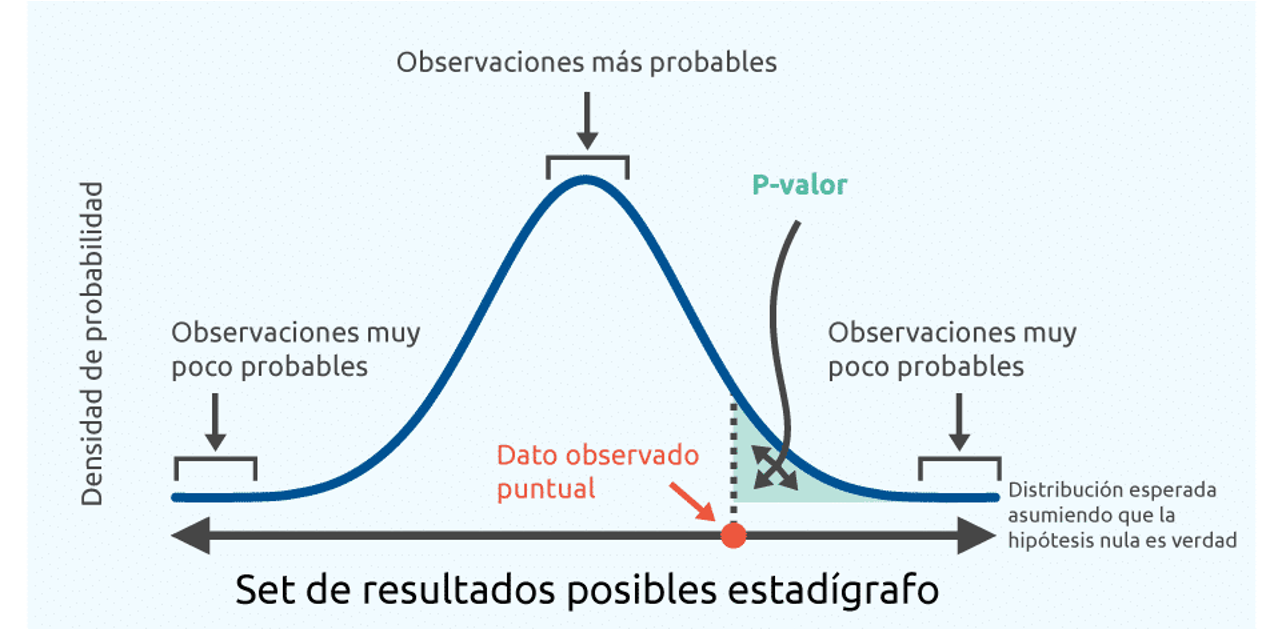
Asociada esta prueba, entonces, hay asociados dos tipos de errores:

Estadígrafos y parámetros
Errores y P-valor
El Valor de probabilidad (ó p-valor) es el nivel probabilidad más alto para el cual no podemos rechazar la hipótesis nula de la prueba de significancia.
Ejemplo: Peso de los Pingüinos Palmer

| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | Male |
Ejemplo: Peso de los Pingüinos Palmer
Calcularemos el promedio muestral y lo veremos en el contexto de los datos observados: . . .
import matplotlib.pyplot as plt
# Calcular el promedio del peso de los pingüinos
promedio_peso = penguins['body_mass_g'].mean()
# Crear un histograma de la distribución del peso con el promedio
plt.figure(figsize=(10, 6))
sns.histplot(data=penguins, x='body_mass_g', bins=20, kde=True)
plt.axvline(x=promedio_peso, color='red', linestyle='dashed', label='Promedio')
plt.title('Distribución de Peso de Pingüinos')
plt.xlabel('Masa Corporal (g)')
plt.ylabel('Frecuencia')
plt.legend()
plt.show()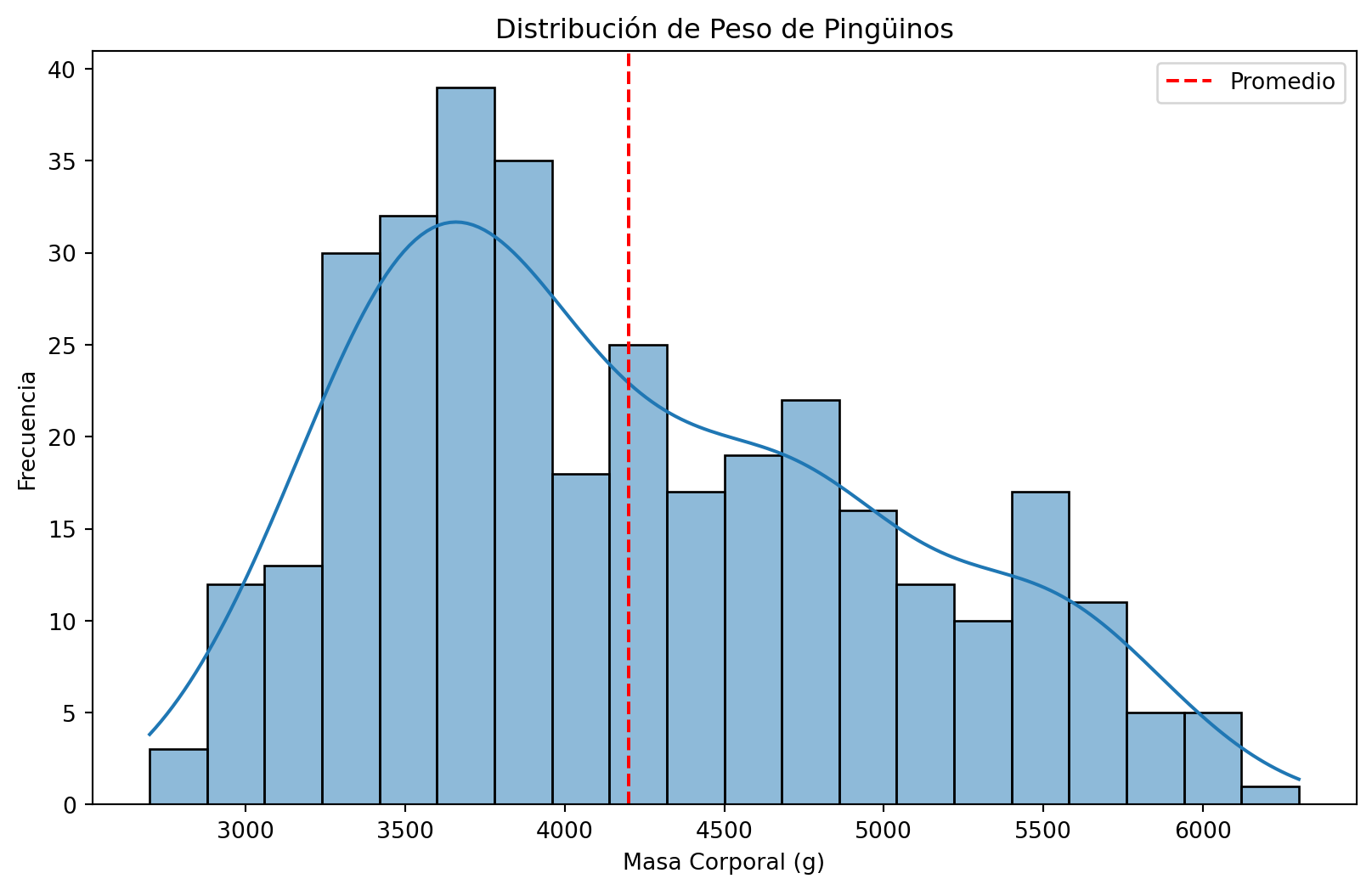
Ejemplo: Peso de los Pingüinos Palmer
import numpy as np
# Definir el tamaño de cada muestra y la cantidad de muestras
tamano_muestra = 50
cantidad_muestras = 10000
# Crear una lista para almacenar las medias de cada muestra
medias_muestras = []
# Realizar el muestreo y cálculo de medias para cada muestra
for _ in range(cantidad_muestras):
muestra = np.random.choice(penguins['body_mass_g'], size=tamano_muestra, replace=False)
media_muestra = np.mean(muestra)
medias_muestras.append(media_muestra)
# Calcular el promedio de los promedios de las muestras
promedio_promedios = np.mean(medias_muestras)
# Crear el gráfico de las medias de las muestras
plt.figure(figsize=(10, 6))
plt.hist(medias_muestras, bins=20, edgecolor='black', alpha=0.7)
plt.axvline(x=promedio_promedios, color='red', linestyle='dashed', label='Promedio de Promedios')
plt.title('Distribución de Medias de Muestras')
plt.xlabel('Media de Muestra de Peso (g)')
plt.ylabel('Frecuencia')
plt.legend()
plt.show()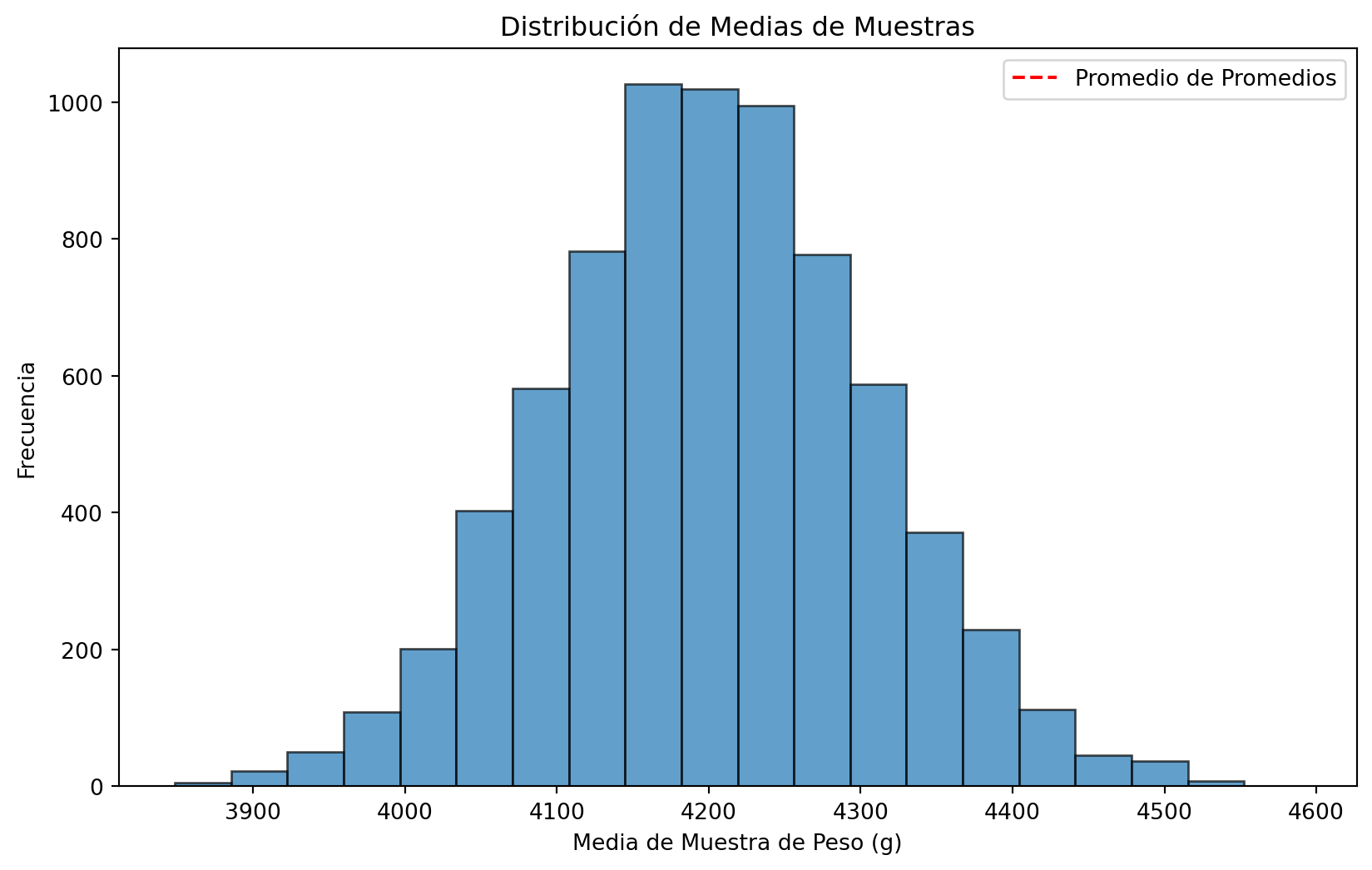
Comparaciones de grupos
- Para probar esta hipótesis, podrías utilizar una prueba de hipótesis para comparar las medias de las muestras de peso de los pingüinos machos y hembras en la especie “Adelie”.
import matplotlib.pyplot as plt
# Cargar el conjunto de datos "Penguins"
penguins = sns.load_dataset("penguins")
# Filtrar los pingüinos de la especie "Adelie"
adelie_penguins = penguins[penguins['species'] == 'Adelie']
# Crear un histograma para la distribución de peso por sexo
plt.figure(figsize=(10, 6))
sns.histplot(data=adelie_penguins, x='body_mass_g', hue='sex', bins=20, kde=True)
plt.title('Distribución de Peso por Sexo para Pingüinos Adelie')
plt.xlabel('Masa Corporal (g)')
plt.ylabel('Frecuencia')
plt.legend(title='Sexo')
plt.show()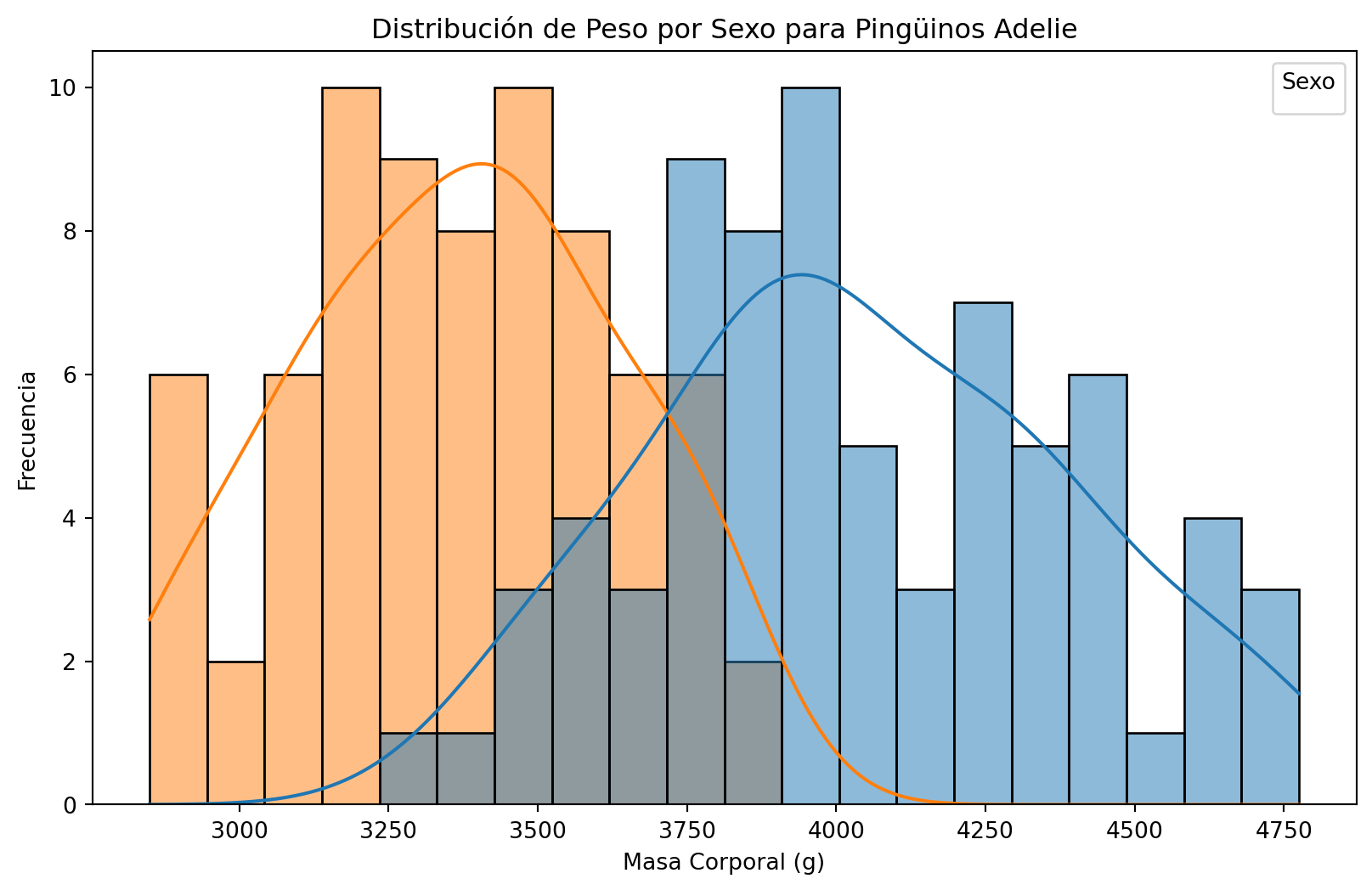
Comparaciones de grupos
- A simple vista podriamos pensar ambos grupos son diferentes.
- Es más claro si dibujamos el promedio muestral observado.
# Crear un gráfico de densidad con líneas de promedio
plt.figure(figsize=(10, 6))
sns.kdeplot(data=adelie_penguins, x='body_mass_g', hue='sex', fill=True, common_norm=False)
plt.axvline(x=adelie_penguins.groupby('sex')['body_mass_g'].mean()['Female'], color='blue', linestyle='dashed', label='Promedio Femenino')
plt.axvline(x=adelie_penguins.groupby('sex')['body_mass_g'].mean()['Male'], color='orange', linestyle='dashed', label='Promedio Masculino')
plt.title('Densidad de Peso por Sexo para Pingüinos Adelie')
plt.xlabel('Masa Corporal (g)')
plt.ylabel('Densidad')
plt.legend()
plt.show()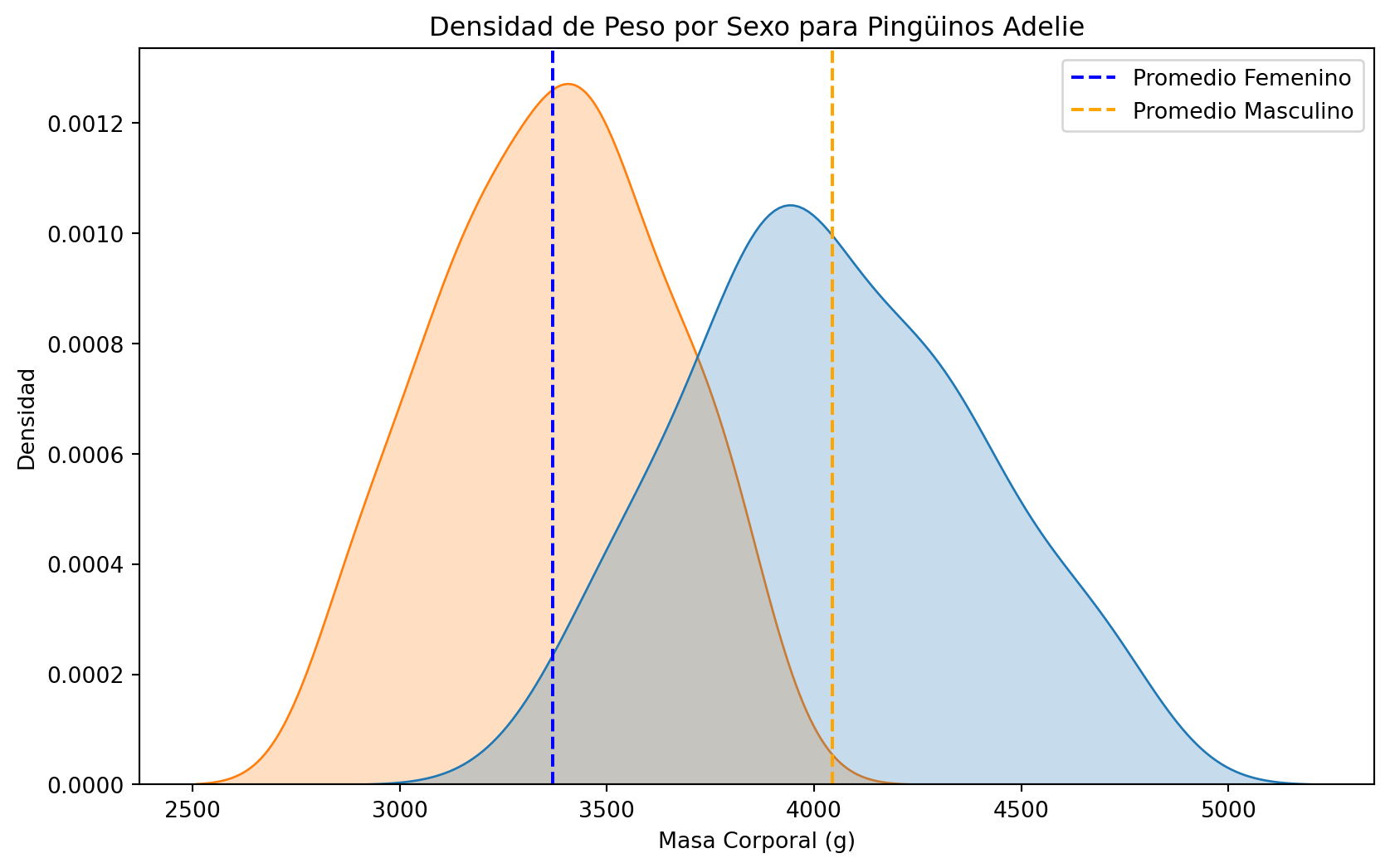
Comparaciones de grupos
# Filtrar los pingüinos de la especie "Adelie"
adelie_penguins = penguins[penguins['species'] == 'Adelie']
# Filtrar machos y hembras
machos = adelie_penguins[adelie_penguins['sex'] == 'Male']
hembras = adelie_penguins[adelie_penguins['sex'] == 'Female']
# Realizar la prueba t independiente
t_statistic, p_value = stats.ttest_ind(machos['body_mass_g'], hembras['body_mass_g'], equal_var=False)
# Imprimir resultados
print("Estadística t:", t_statistic)
print("Valor p:", p_value)
# Crear un gráfico de comparación de peso
plt.figure(figsize=(10, 6))
sns.boxplot(data=[machos['body_mass_g'], hembras['body_mass_g']], palette=['blue', 'pink'])
plt.title('Comparación de Peso entre Machos y Hembras de Pingüinos Adelie')
plt.xticks([0, 1], ['Machos', 'Hembras'])
plt.ylabel('Peso (g)')
plt.show()Estadística t: 13.126285923485874
Valor p: 6.402319748031793e-26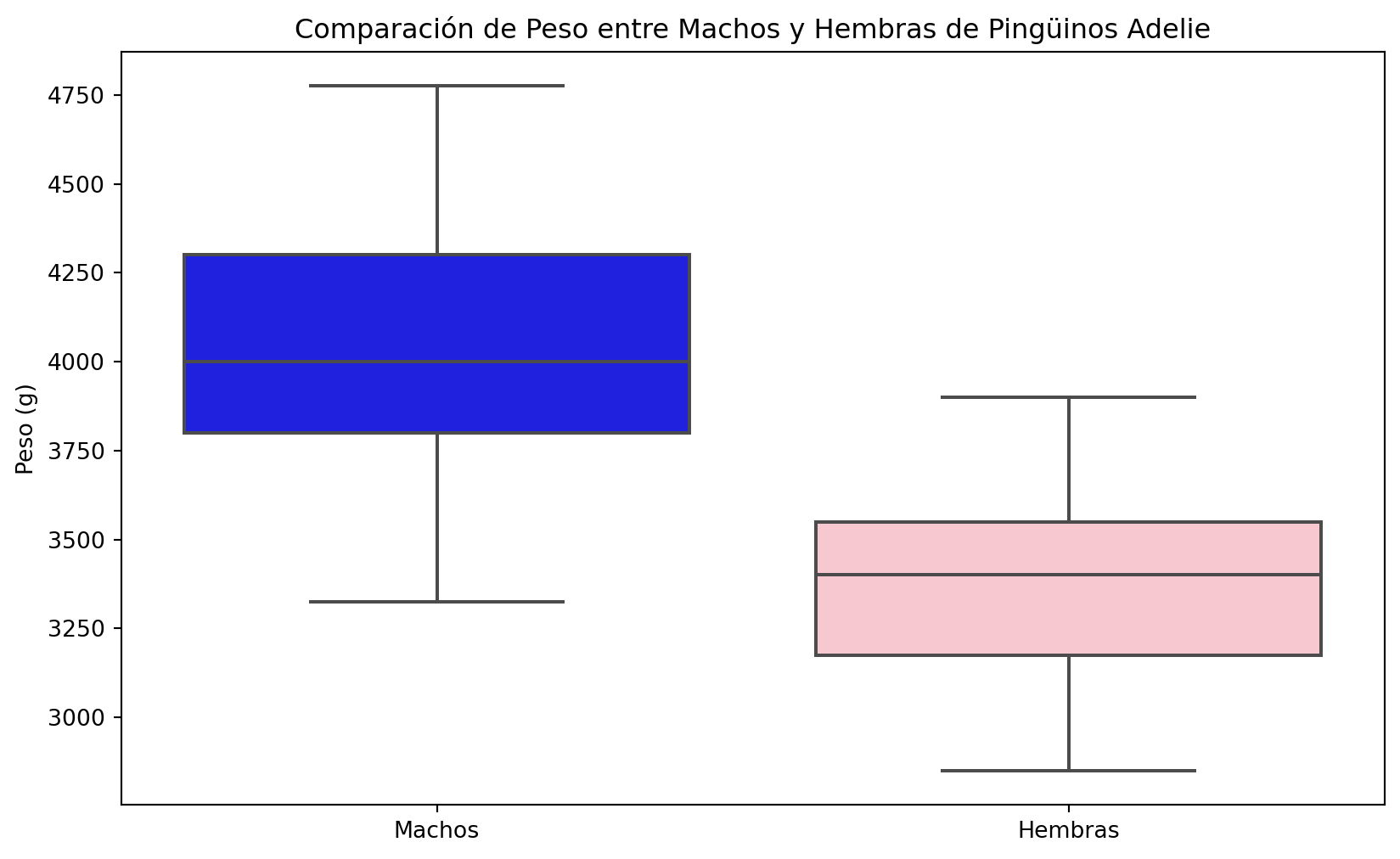
Comparaciones de grupos
- Finalmente, podriamos querer comparar hembras y machos de diferentes Islas.
- Para esto podriamos usar una prueba ANOVA.
import seaborn as sns
import scipy.stats as stats
# Cargar el conjunto de datos "Penguins"
penguins = sns.load_dataset("penguins")
# Filtrar machos y hembras
machos = penguins[penguins['sex'] == 'Male']
hembras = penguins[penguins['sex'] == 'Female']
# Realizar una prueba ANOVA
result = stats.f_oneway(machos['body_mass_g'], hembras['body_mass_g'])
# Imprimir resultados
print("Estadística F:", result.statistic)
print("Valor p:", result.pvalue)Estadística F: 72.96098633250911
Valor p: 4.897246751596325e-16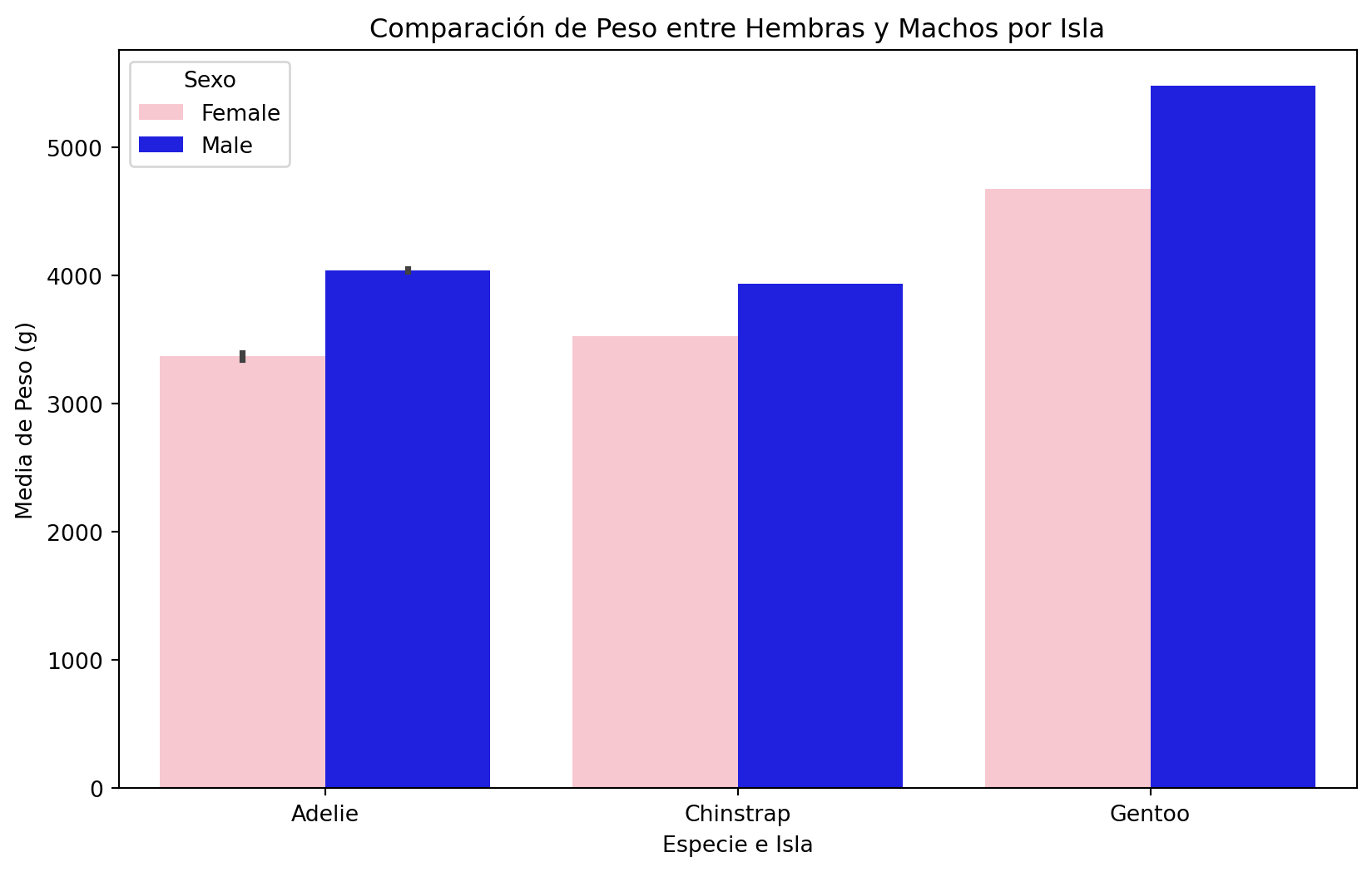
Uso de Sistemas de Control de Versiones como GIT para Rastrear Cambios:
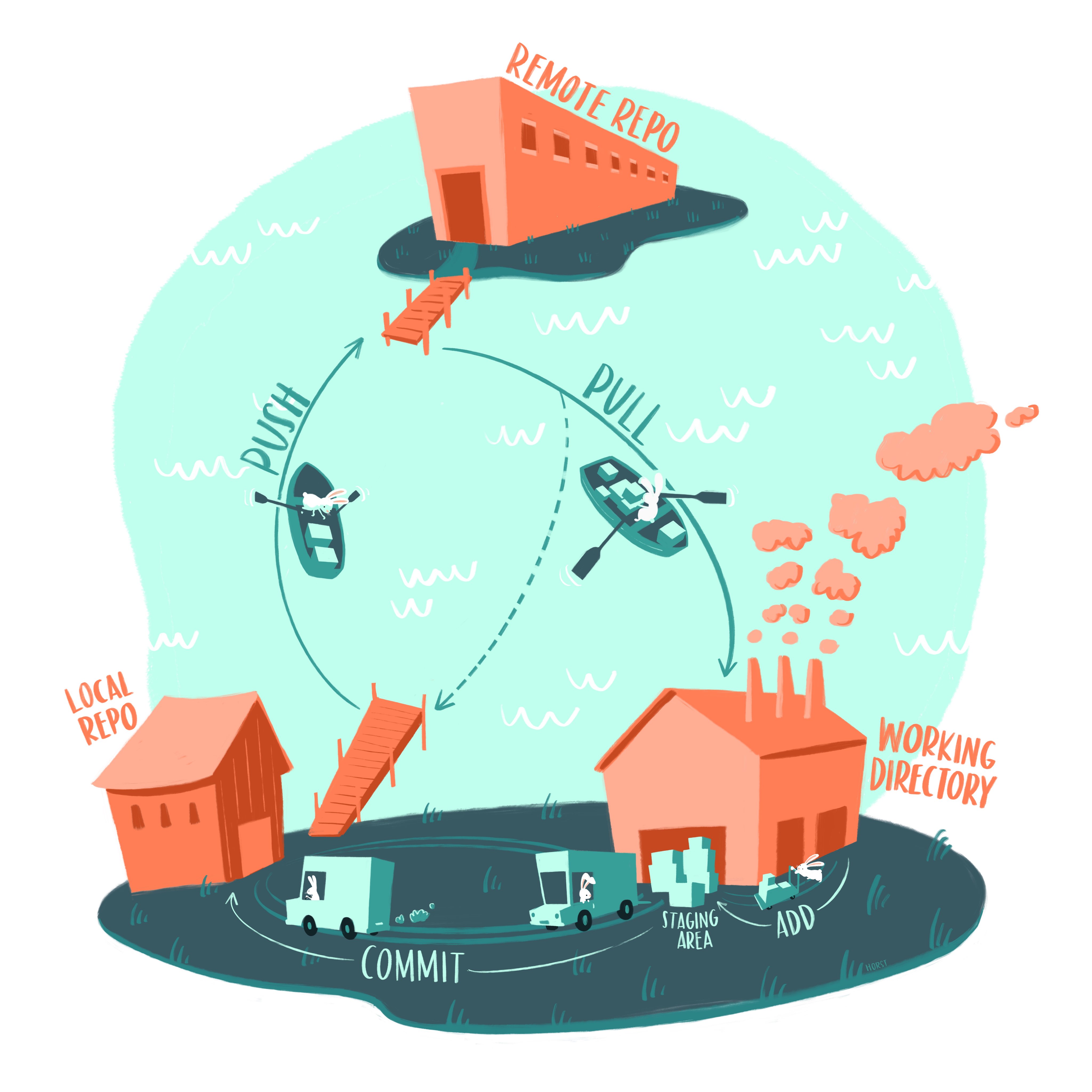
Un esquema de git por Allison Horst @allison_horst
Actividad de proyecto
Inicio reproducible
Vamos a empezar el proyecto, dando los primeros pasos considerando que sea reproducible y transparente.
Uno de los productos del proyecto es un notebook de reporte del análisis. Para esto, iremos avanzando desde hoy.
- Defina a su grupo e inscribase.
- Cree un repositorio de Github en el cual van a trabajar, agregue a todos los integrantes como colaboradores y a la profesora (usuario: melanieoyarzun)
- Cree el readme listando a los integrantes del grupo.
- Definan con que base de datos les gustaría trabajar.
- Propongan una o dos preguntas de investigación y las hipotesis que las responderían.
La siguiente sesión, vamos a explorar los datos y empezar los primeros pasos en su análisis.