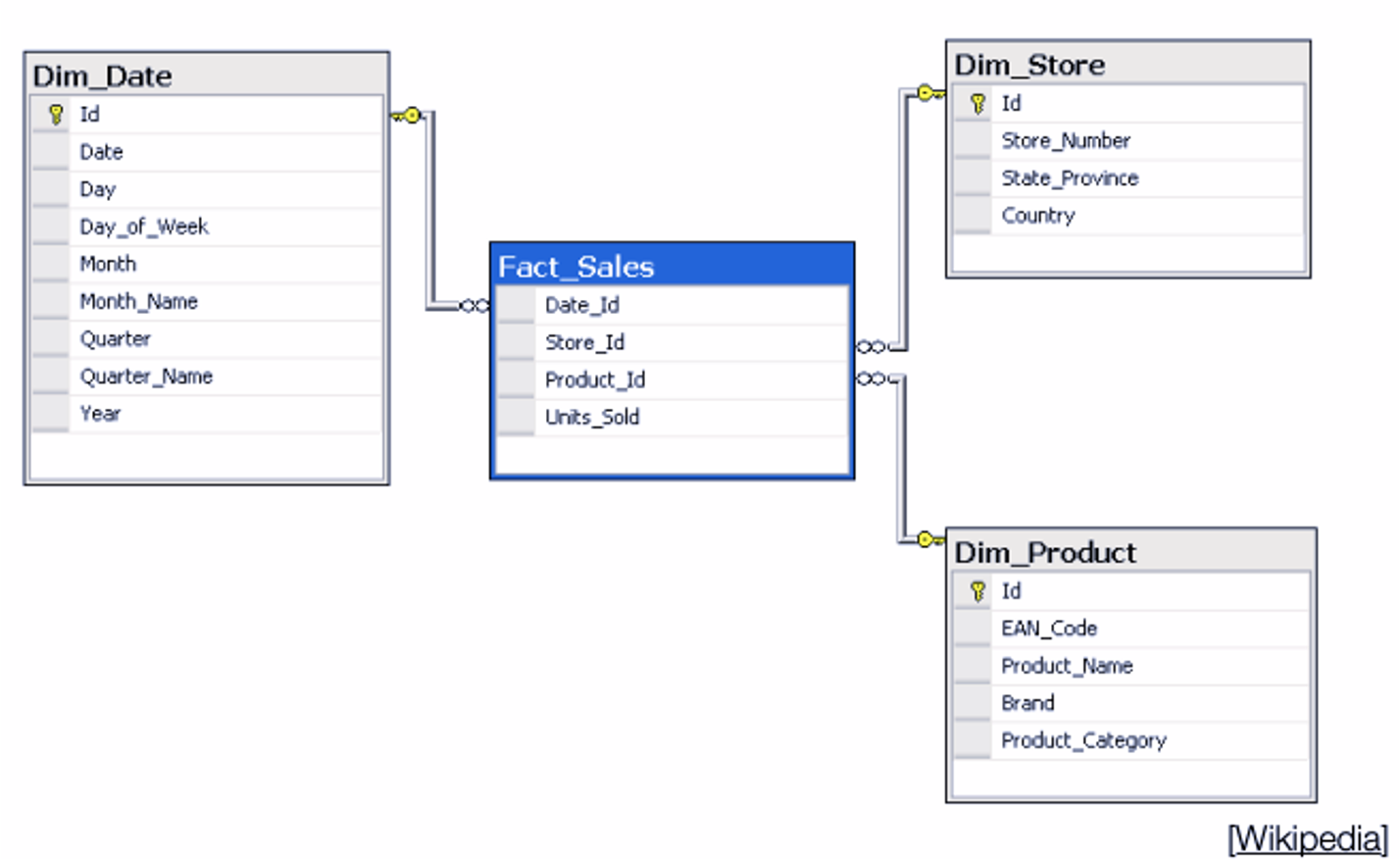
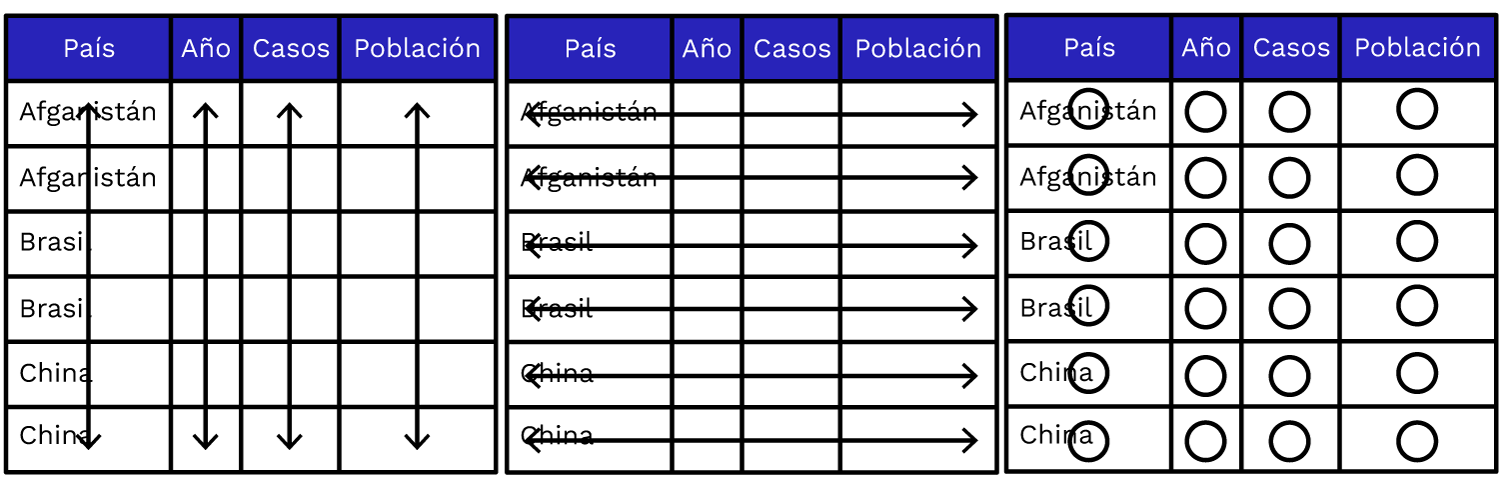
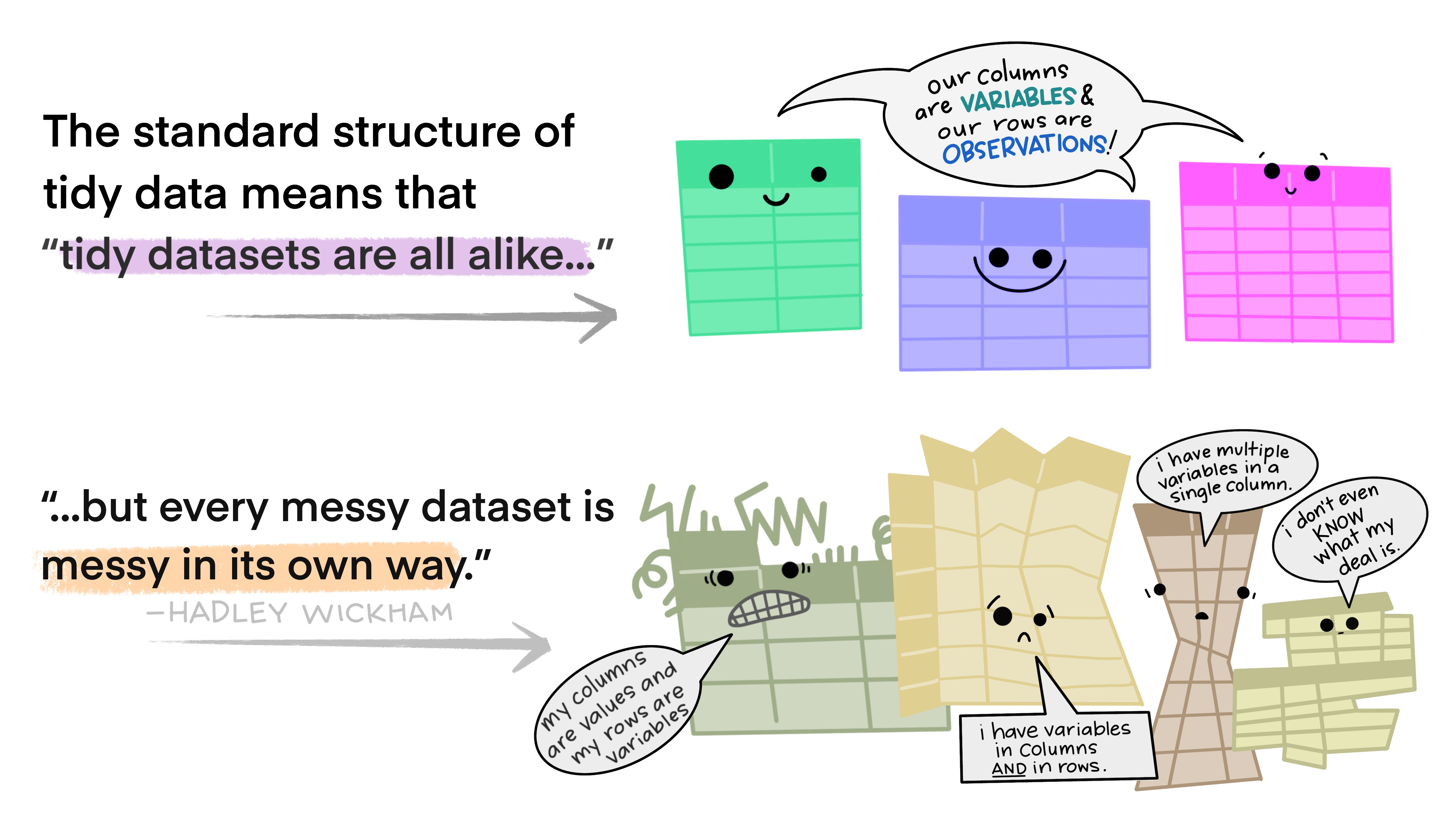
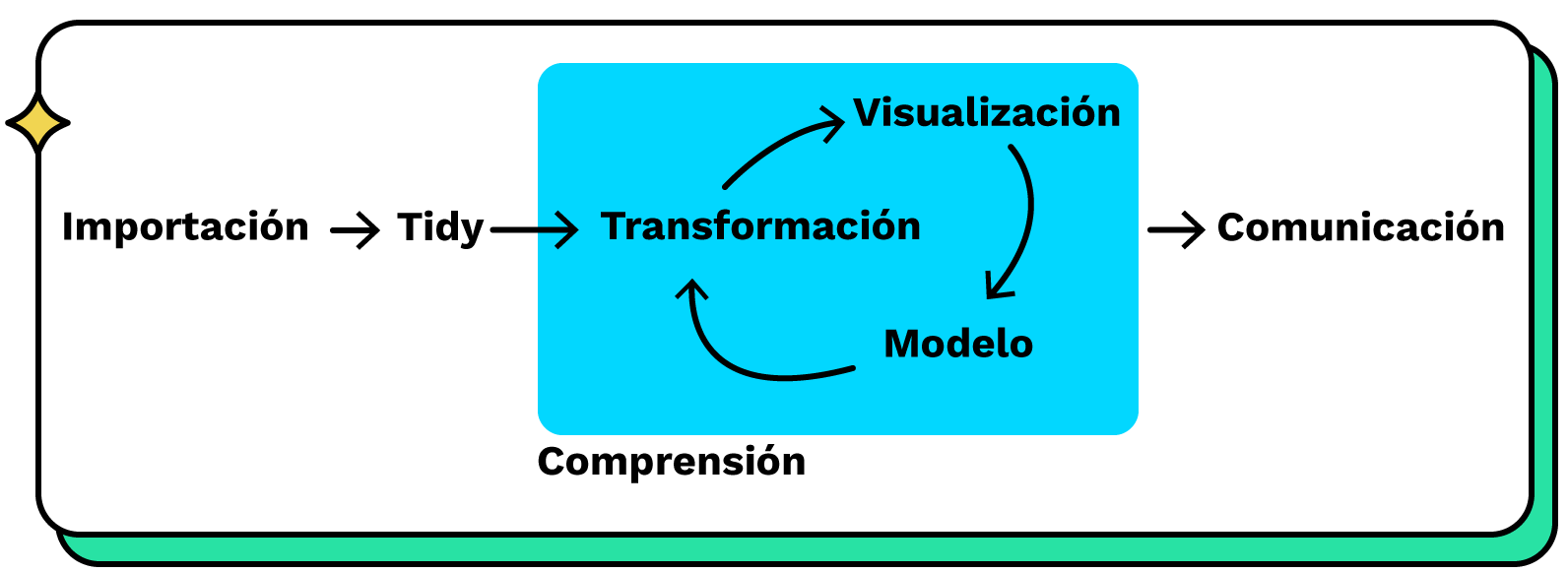
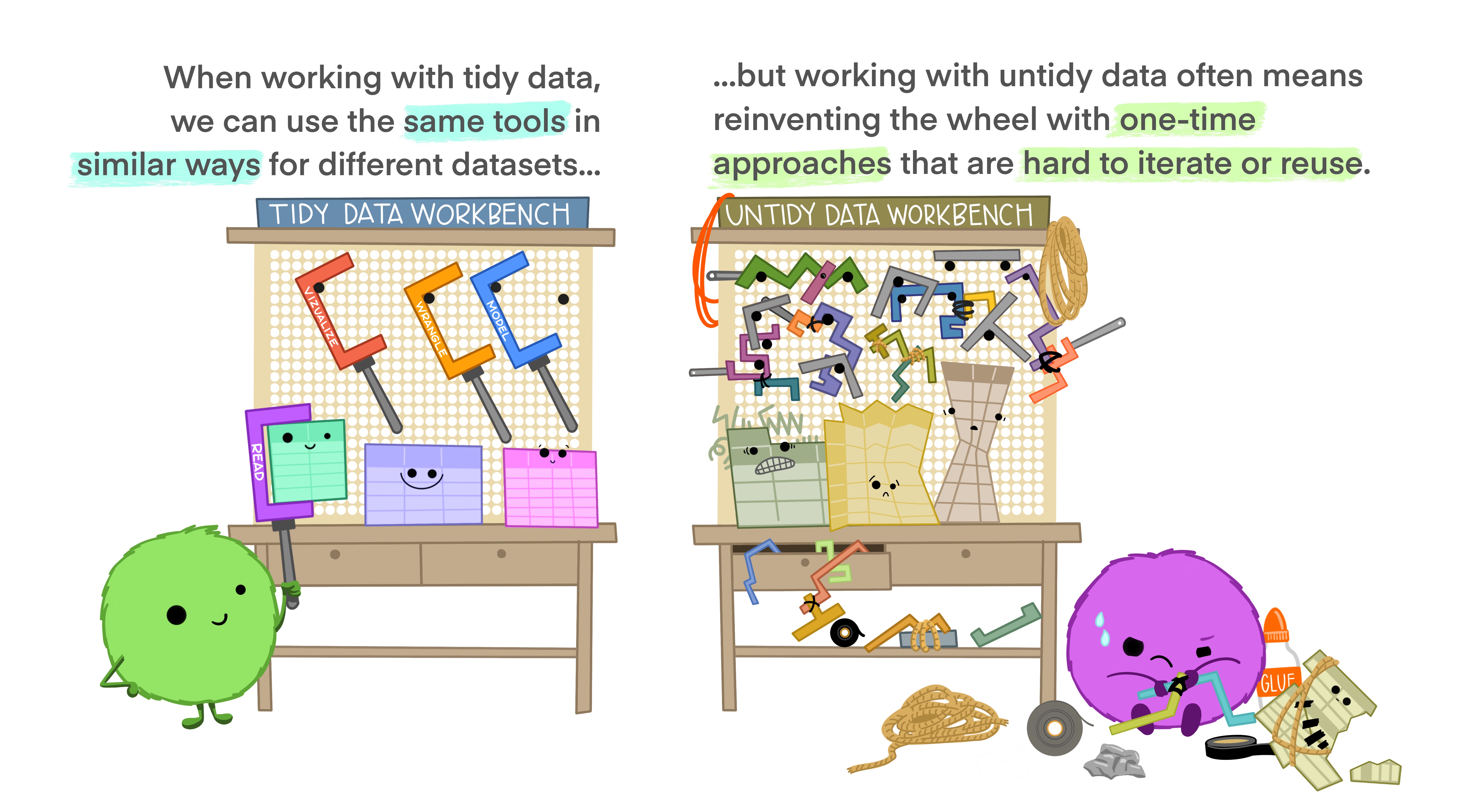
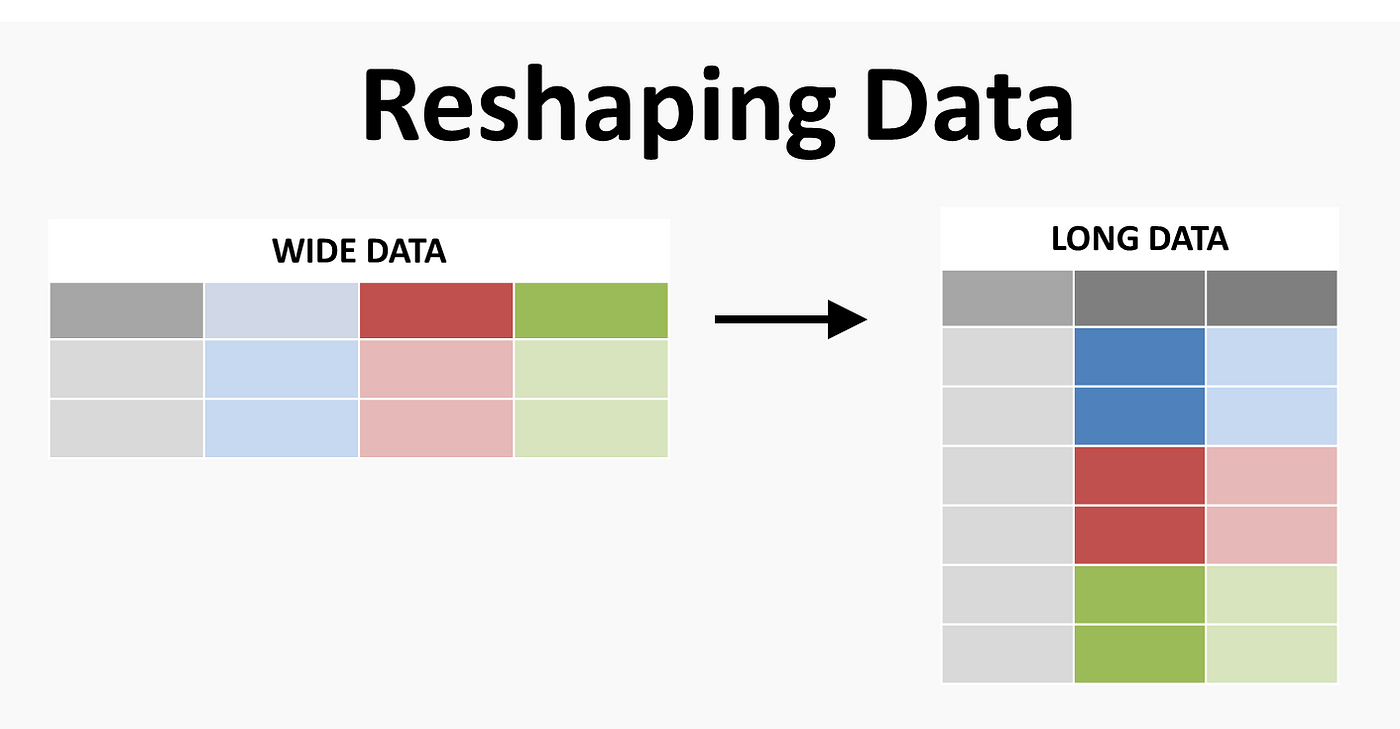
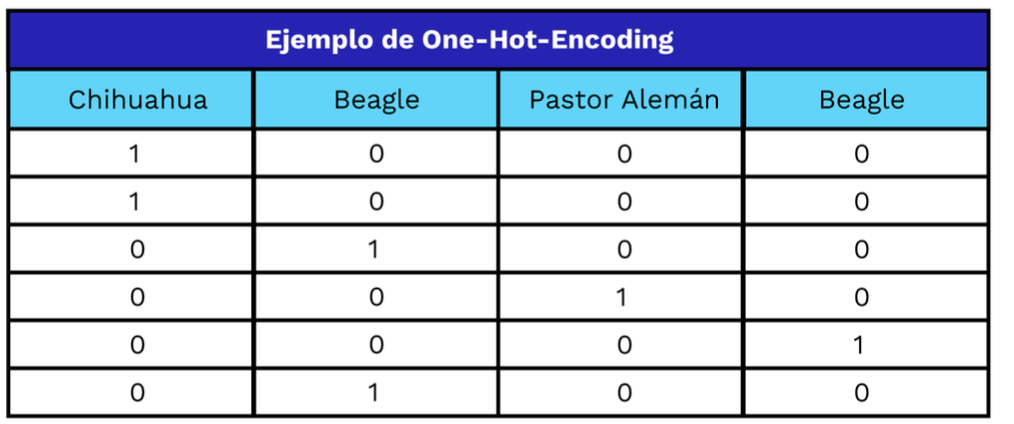
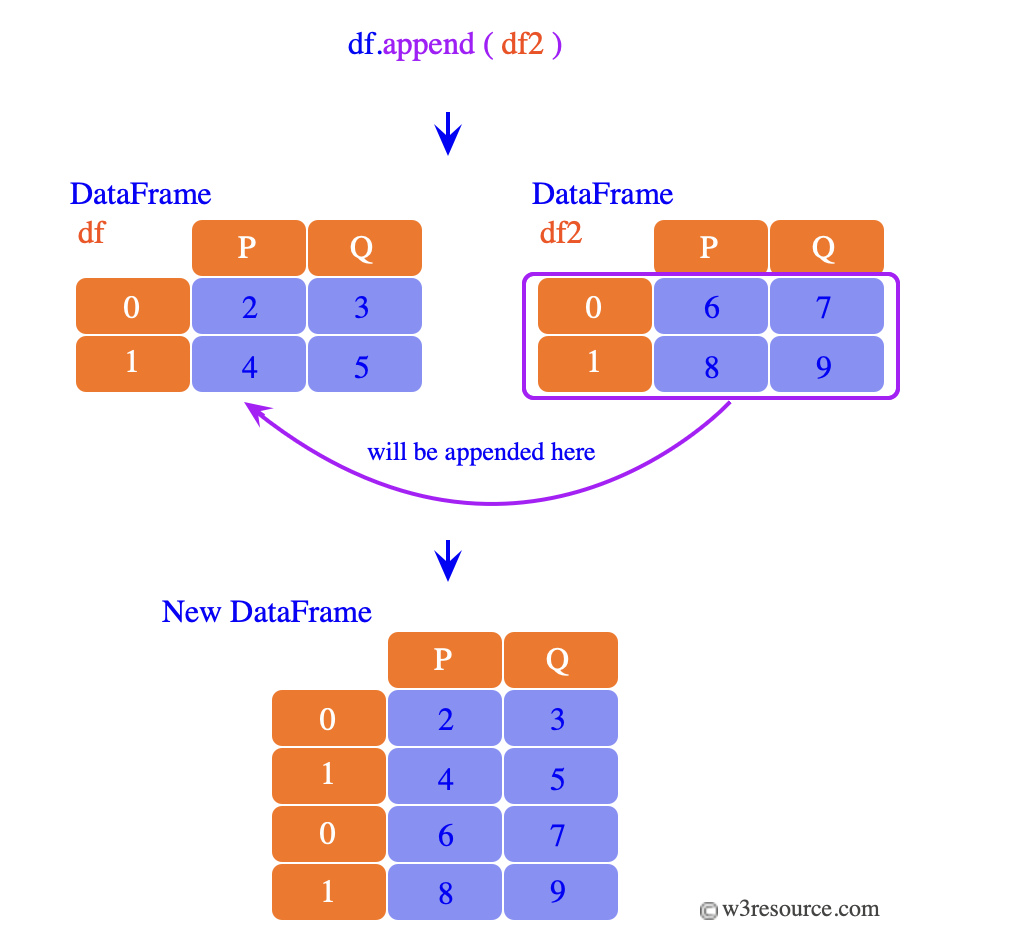
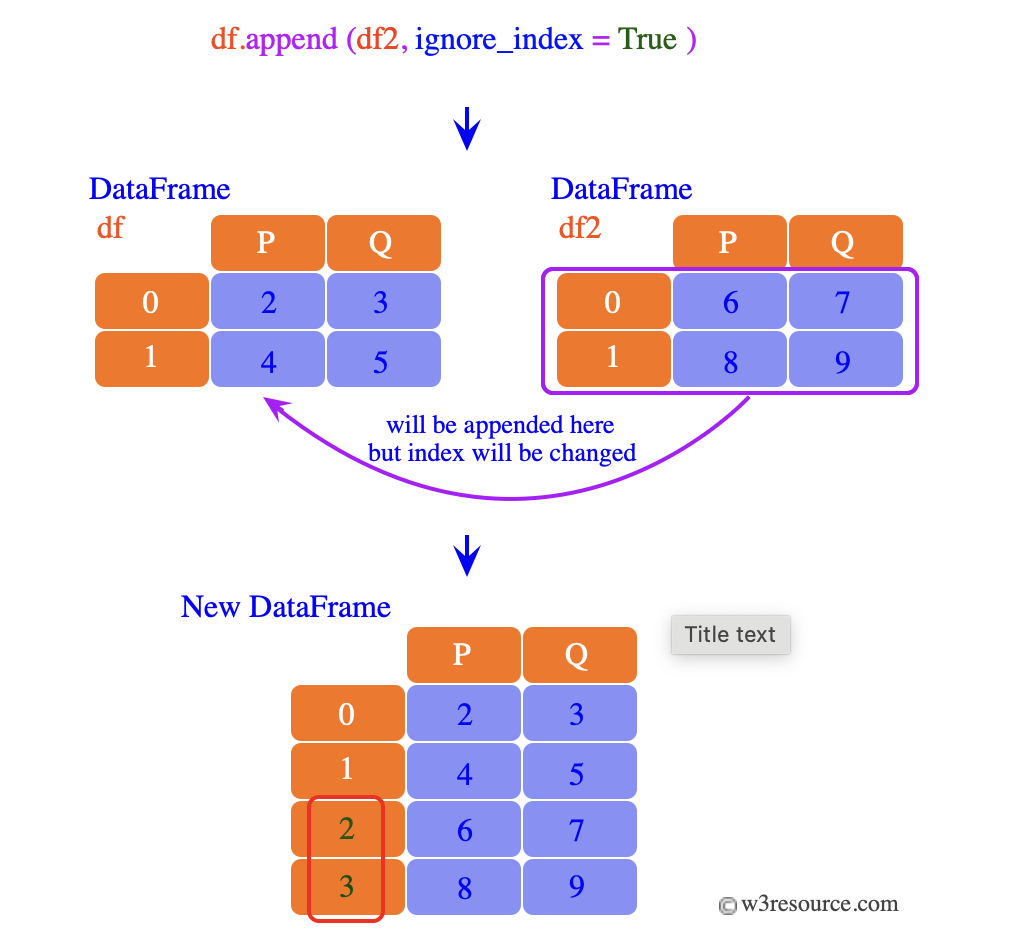
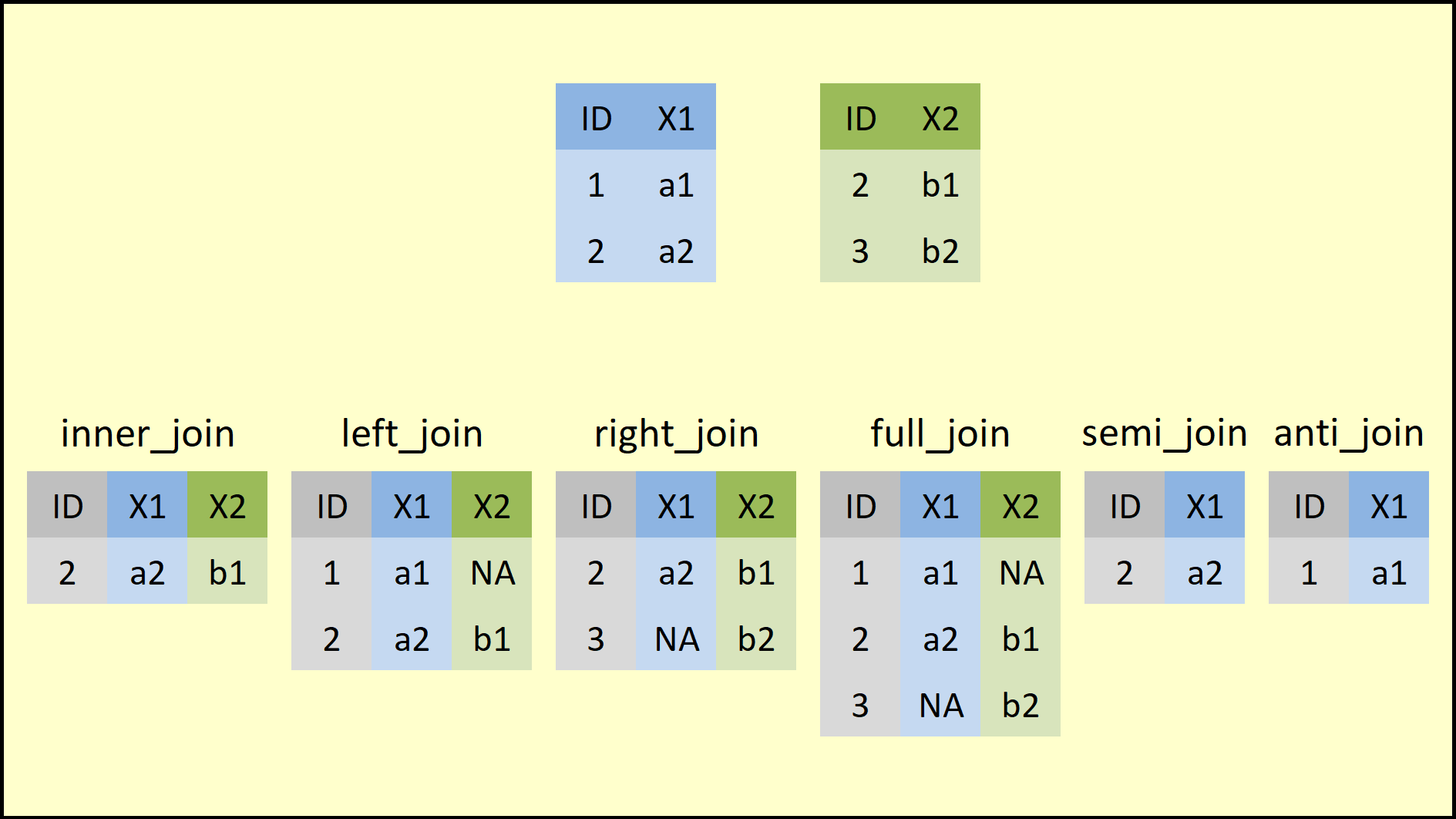
Algunos tipos de argumentos para funciones read:
- Indexing: escoger una columna para indexar los datos, obtener nombres de columnas del archivo o usuario
- Type inference y data conversion: automático o definido por el usuario
- Datetime parsing: puede combinar información de múltiples columnas
- Iterating: trabajar con archivos muy grandes
- Unclean Data: saltarse filas (por ejemplo, comentarios) o trabajar con números con formato (por ejemplo, 1,000,345)
- Memory:
low_memory indica que usemos pocos recursos (o no) del sistema.