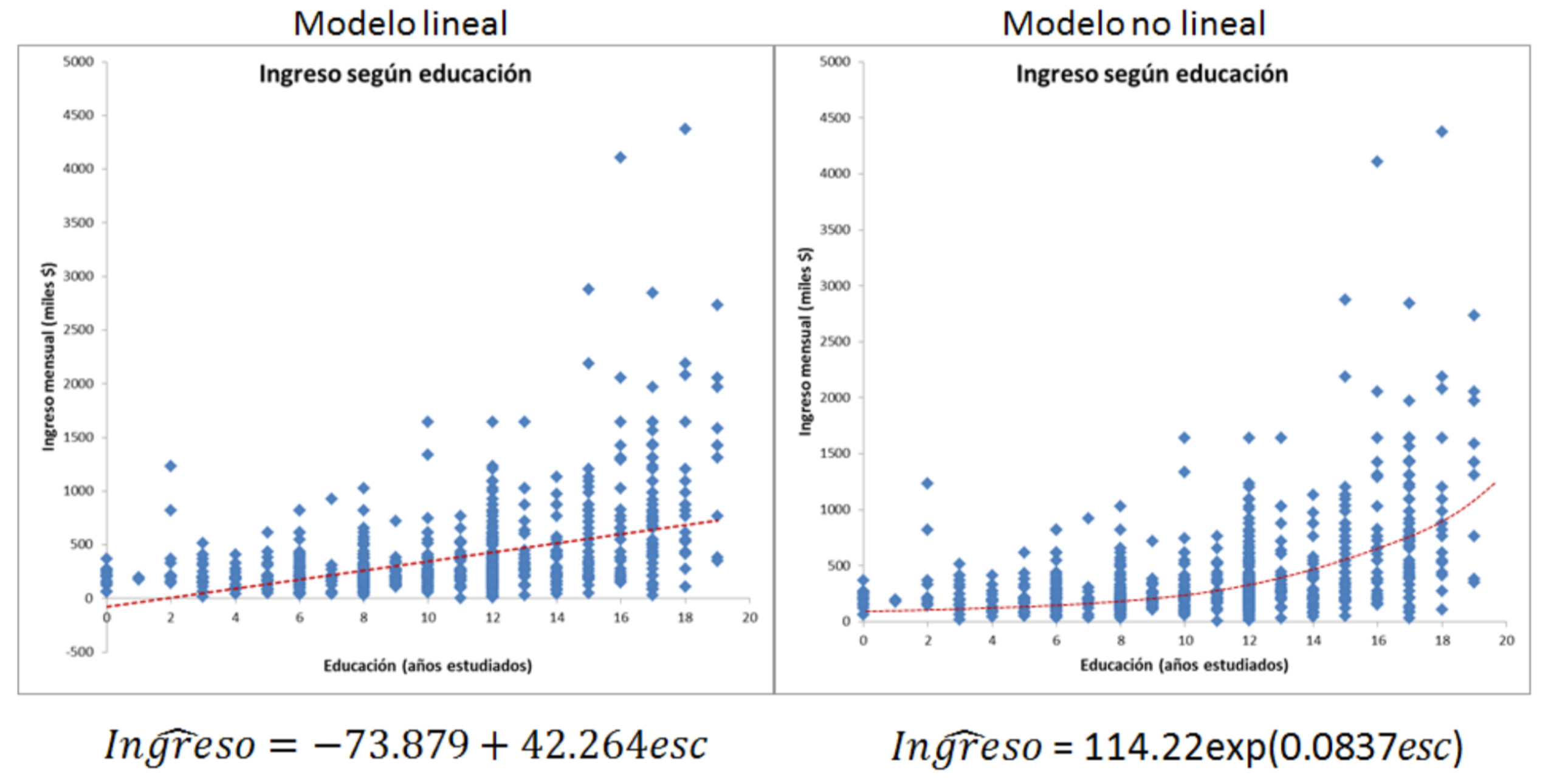
Ahora el efecto de la educación en el salario no es contante: \[ \frac{\partial{ingreso}}{ \partial{esc}}= \beta_1+2*\beta_2*esc \]
Esto no rompe el supuesto de linealidad: el modelo debe ser lineal en los coeficientes \(\beta_j\) y no en las variables \(x_j\)
Variables cuadráticas y polinomios
En el caso de salario y educación:
Información cualitativa
Muchas veces queremos incorporar al análisis información que es no de carácter numérico, sino que responde a una característica o cualidad.
Variable binaria: toma dos valores
Ejemplo: Sexo (h, m), zona de residencia (urbano, rural)
Variable categórica: puede tomar varios valores
Ejemplos: región, industria, ocupación, nacionalidad, color de pelo, etc.
¿Cómo incluimos esta información en los modelos?
Va a depender si estamos pensando que esta es la variable dependiente (y) o independiente (x).
Información cualitativa en variables independientes
Cuando incluimos información cualitativa como variable independiente, hay que tener cuidado en como incorporamos al modelo y como interpretamos.
Pero no cambia la forma de estimación.
Veremos primero el caso de variables binarias, porque es más fácil de incorporar.
El caso de variables categóricas se incluye como una extensión a las binarias.
Variables binarias
Una variable binaria, dictómica, Bernoulli o también comúnmente llamada “dummy”.
Es útil re-definirlas como variables 0-1
-Tiene propiedades estadísticas favorables, pero la mas importante es que si x se codifica 0-1, entonces E(x)=p(x)
El valor 1, pasa a ser la categoría de interés
Siguiendo la idea de un “interruptor”, entonces está activa la categoría de interés.
El valor 0, pasa a ser la categoría base o referencia, que aquella con la cual comparamos.
Ejemplo: Si tenemos la variable sexo, podemos definir a la variable female = 1 para las mujeres y 0 para los hombres,
entonces podemos estudiar el efecto de ser mujer (categoría de interés) en comparación a los hombres (categoría base)
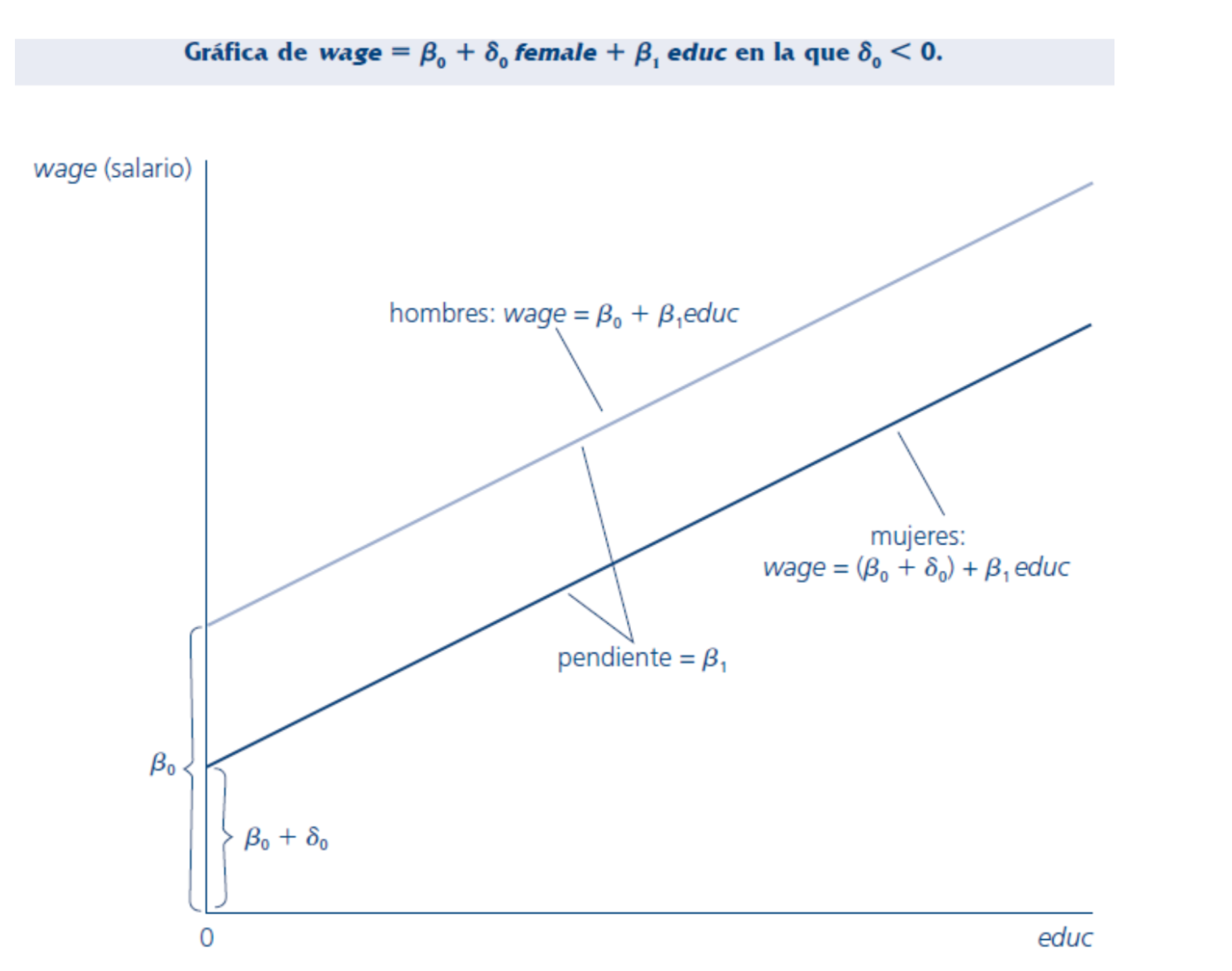
Intercepto diferencial:
La información cualitativa la podemos incluir como una variable más en nuestro modelo.
Esto permite tener un intercepto diferente para cada grupo.
¿Cómo interpretamos\(\delta_0\) ?
Corresponde a la diferencia promedio en Y (Salario en este caso) para el grupo de interés, versus el grupo de referencia.
En este ejemplo, \(\delta_0\) es negativo por eso la constante es menor para mujeres que hombres
a igual nivel de educación el salario promedio es menor para mujeres que hombres en \(\delta_0\), CP.
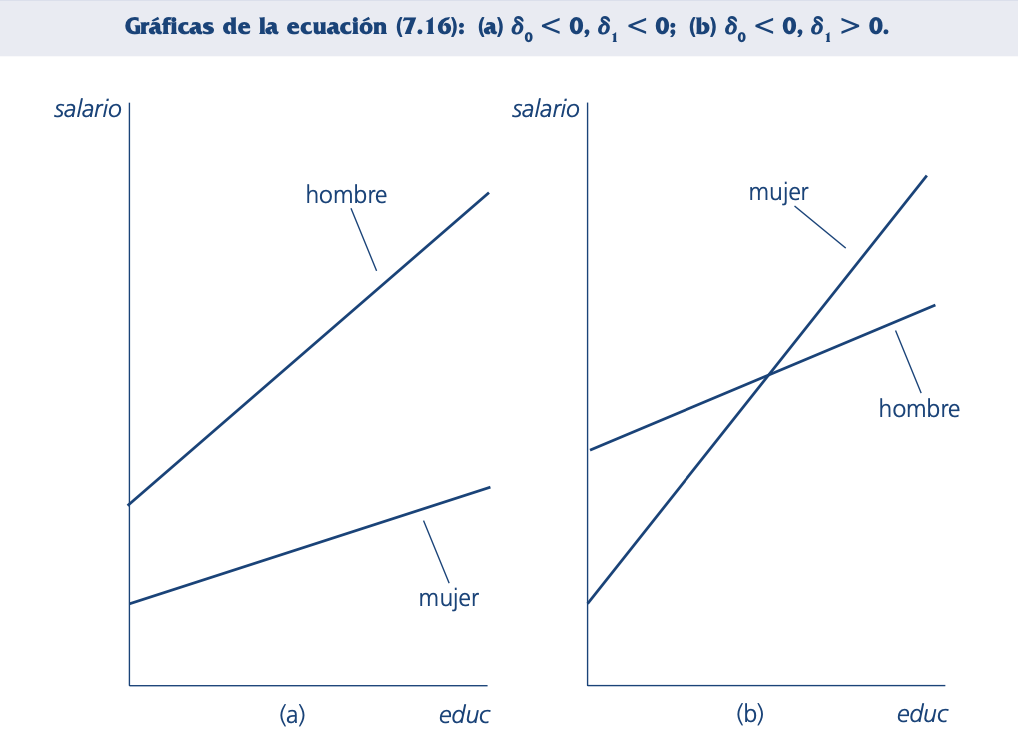
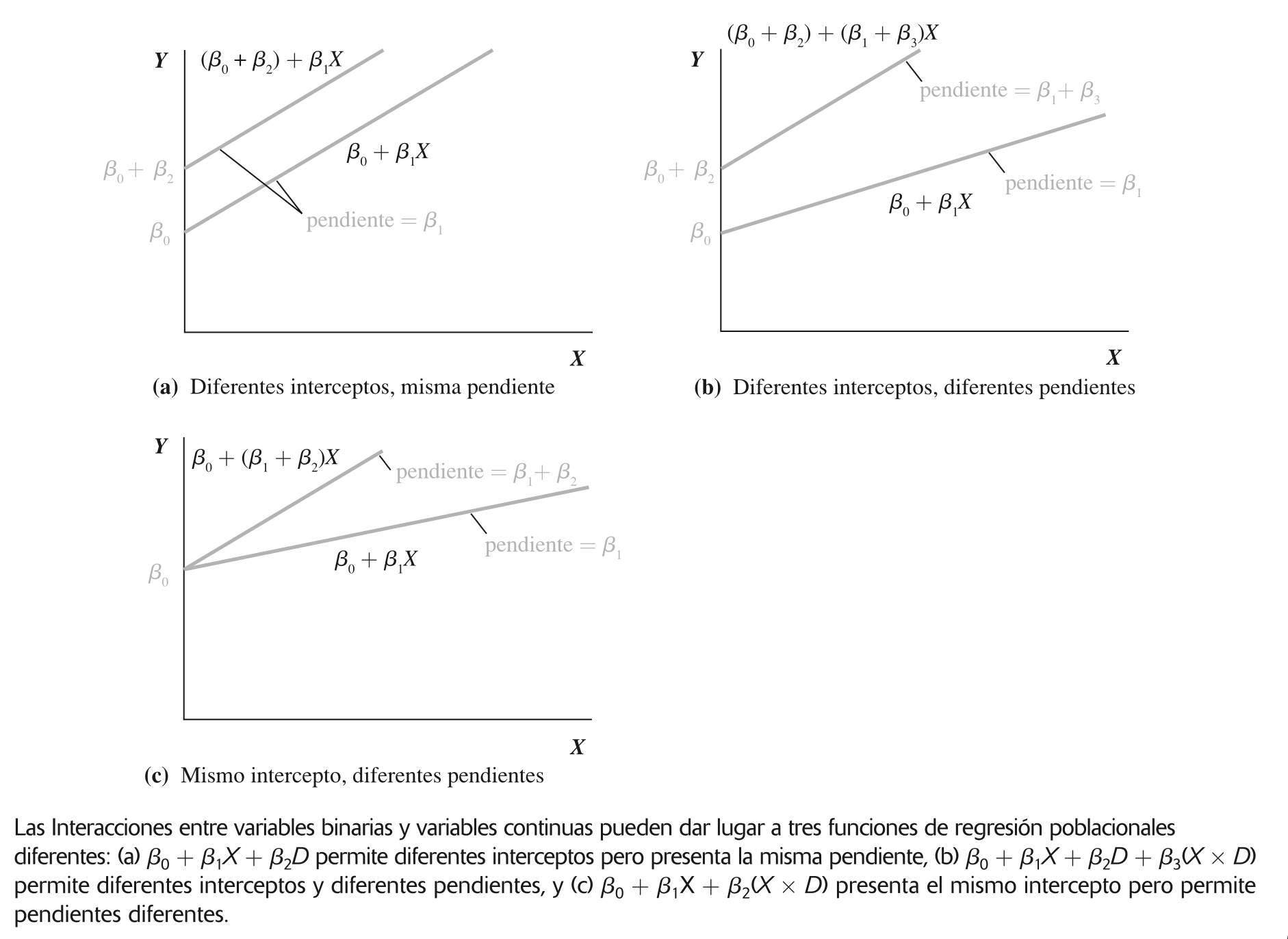
Pendiente diferencial
Se han visto varios ejemplos de cómo considerar, en un modelo de regresión múltiple, diversos interceptos para cualquier cantidad de grupos.
También hay ocasiones en las que variables binarias interactuando con variables explicativas, que no son variables binarias, permiten considerar diferencias en las pendientes.
Continuando con el ejemplo del salario, suponga que se desea saber si el rendimiento de la educación es el mismo para los hombres y para las mujeres, considerando una diferencia constante entre los salarios de hombres y mujeres (una diferencia de la que ya previamente se han encontrado evidencias).
Para simplificar, en este modelo sólo se incluyen educación y género.
¿Qué tipo de modelo permite rendimientos diferentes de la educación?
Hay ciertos cuidados que debemos tener con las variables categóricas.
No podemos simplemente transformarlo en un número e incorporarlo a los modelos, pues el beta representa el cambio, constante en crecer la categoría.
Lo que si podemos hacer, es definir múltiples dummys
Es la idea de “interruptor nuevamente”
Cuidado con la multicolinealidad perfecta o trampa de las dummys:
Ocurre si creamos una dummy para cada categoria y las incluimos todas.
Deben ser n categorías, n-1 variables dummys
Siempre dejar una categoría como base, en la cual todas son 0
Interacciones de variables dummy
Algunas veces queremos saber como tener dos cualidades a la vez afecta a un individuo
Esto lo hacemos mediante interacciones de las variables dummys.
Lo que cambia aca es la cantidad de. grupos y categorias, sin embargo segumos comparando con el caso en que todo vale 0.
Ejemplo, si quisiéramos saber el efecto del estado civil y sexo:
\[ \widehat{wage} = 0.321 - 0.11 female + 0.213 married - 0.301 female \times married \]
Variable dependiente dicotómica
Muchas veces la variable que queremos entender tiene dos posibes resultados, terminó la educación secundaria, ser madre adolescente, trabajar o no, recibir capacitación, comprar o no, etc.
Cuando la variable dependiente es cualitativa, particularmente dicotómica tenemos varias alternativas de acción.
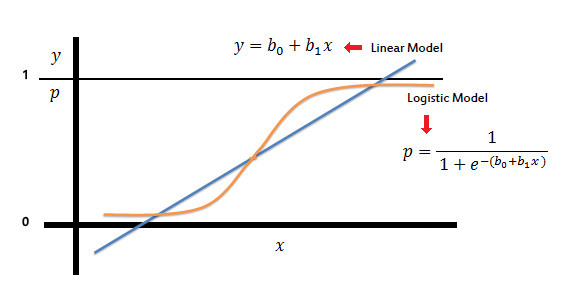
Estimar como siempre: modelo de probabilidad lineal
Estimar modelos no lineales específicos: Logit o Probit
Modelo de probabilidad lineal
Un primer caso, es estimar de la misma manera que antes con un modelo de regresión lineal y MCO.
Un ejemplo posible es querer entender la participación laboral de una mujer. Definimos nuestra variable de interés:
Y nuestra regresión sería:
\[ pa = \beta_0 + \beta_1 pareja+ \beta_2educ+\beta_3edad+\beta_4edad2+ \beta_5h_{0-5}+\beta_6h_{6-13}+\beta_7h_{14-17}+u \]
Modelo de probabilidad lineal
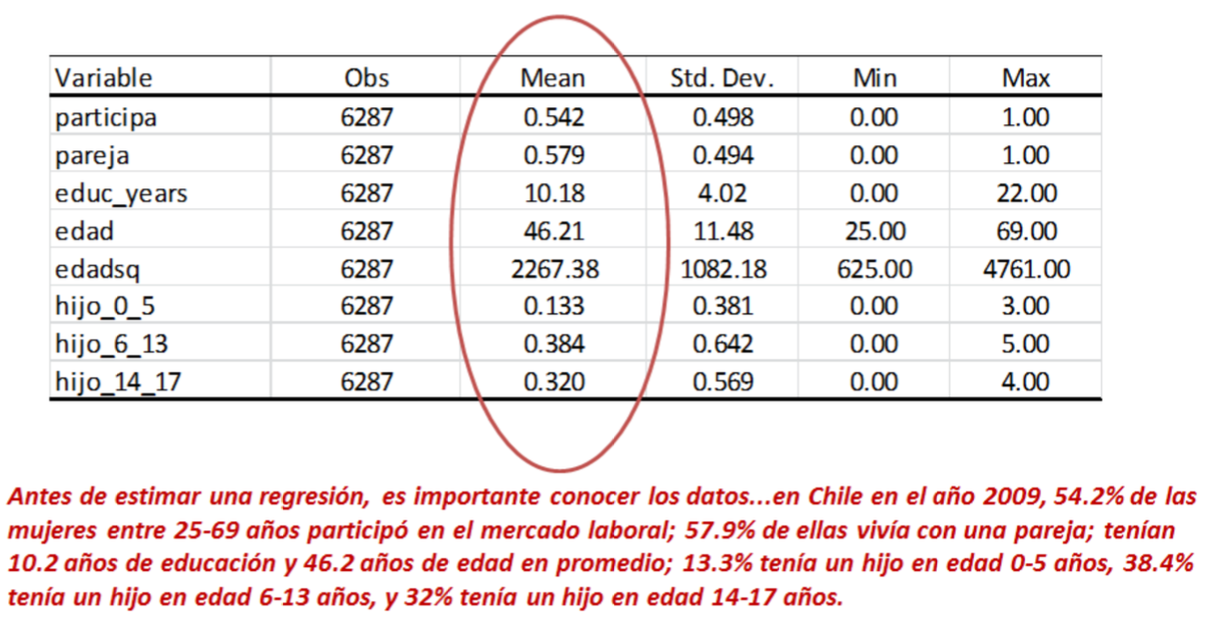
Estadística descriptiva de nuestras variables:
Modelo de probabilidad lineal
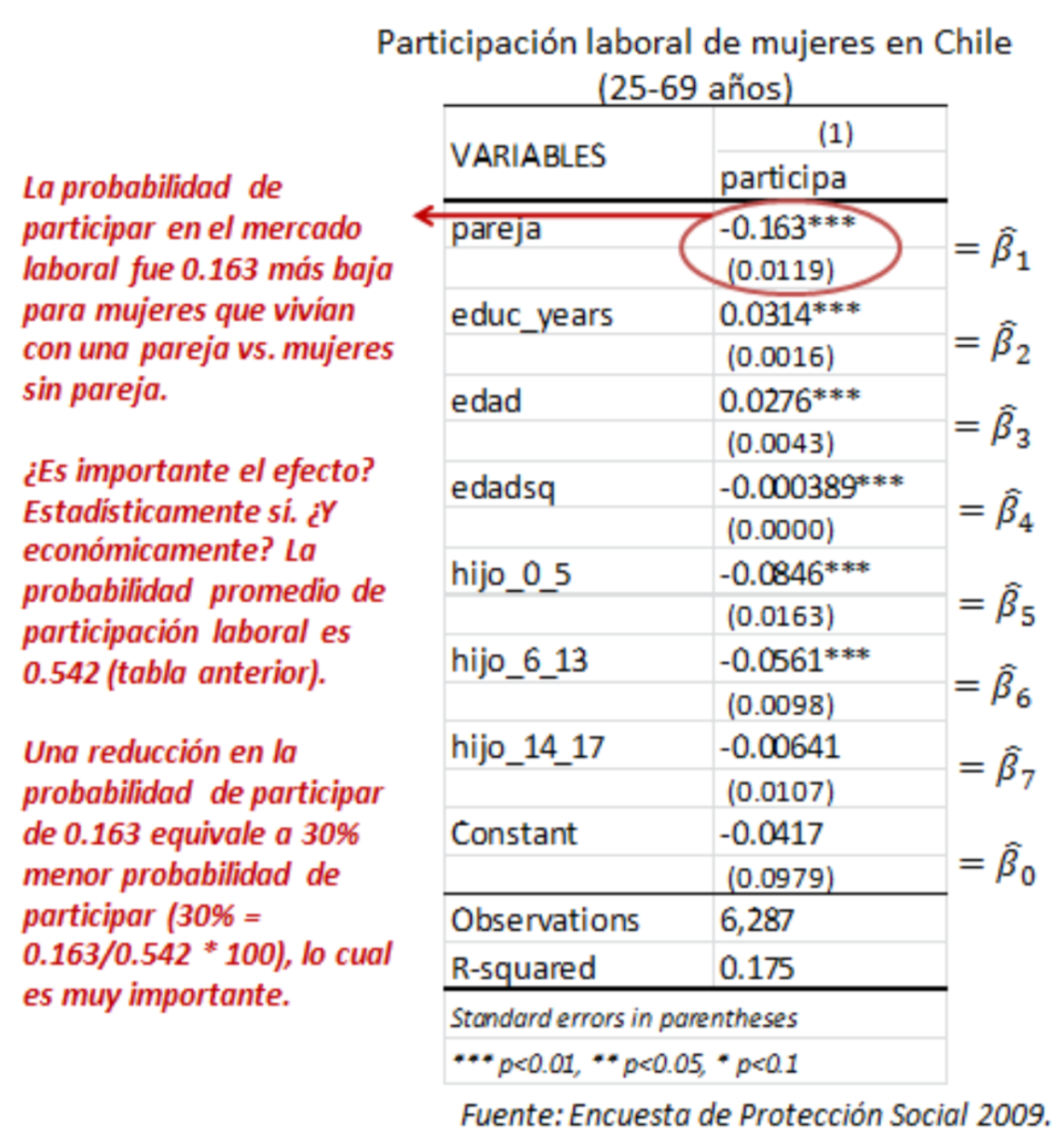
Estimando el modelo:
Modelo de probabilidad lineal
Modelo de probabilidad lineal
Modelos no lineales para dicotómica depediente
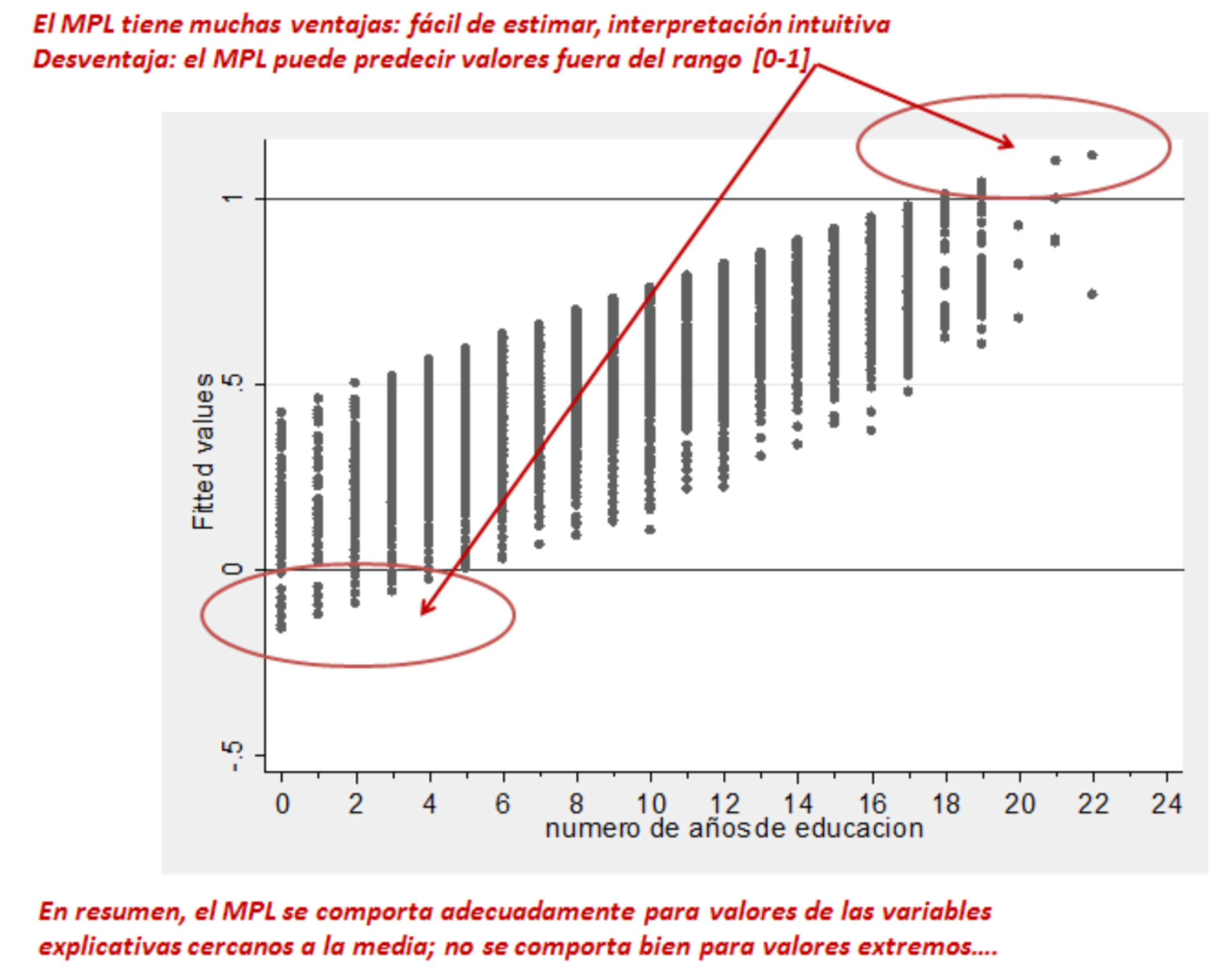
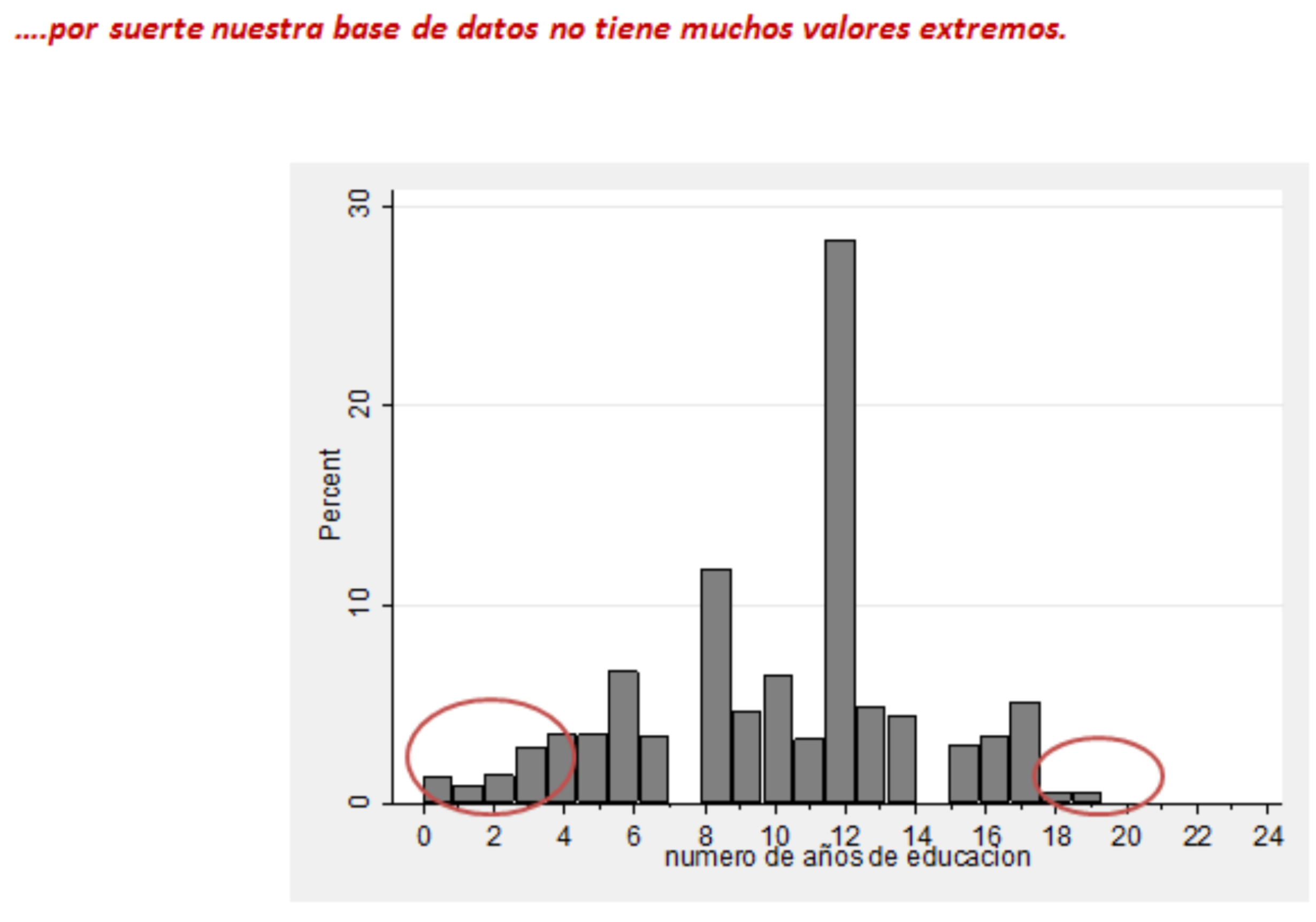
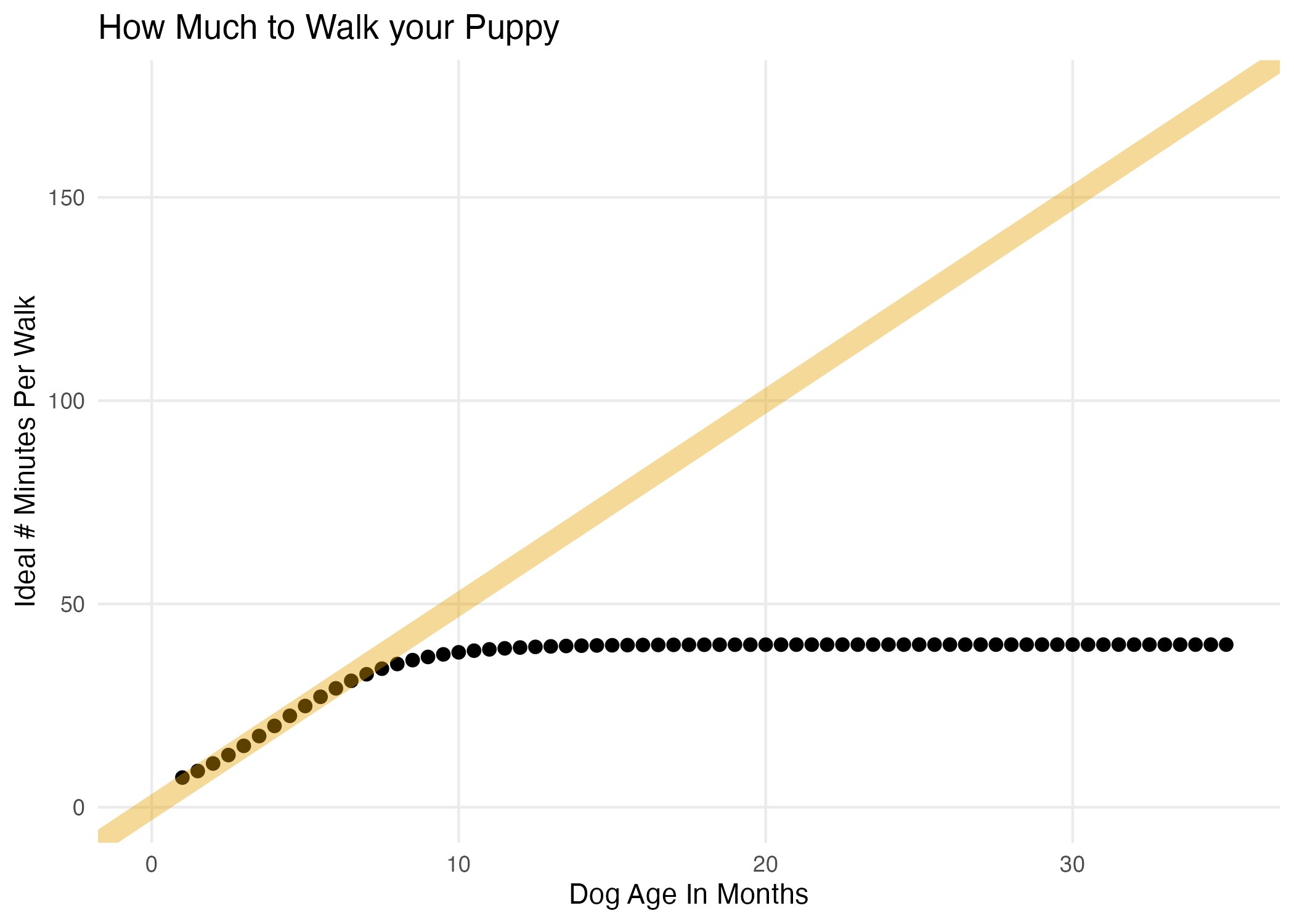
El problema central del MPL es que p puede ser ilógico, menor que 0 y mayor que 1.
Una solución es usar una función que se acerque asintóticamente a 0 y a 1, para describir mejor una probabilidad.
Hay dos casos más usados:
Modelo Probit: Usar una función de distribución acumulada de una distribución normal
Modelo Logit : Usar una función de distribución acumulada de una distribución logística
Modelo Logit
EL modelo logit es probablemente el mas usado en ciencia de datos, asi que revisemos un poco más.
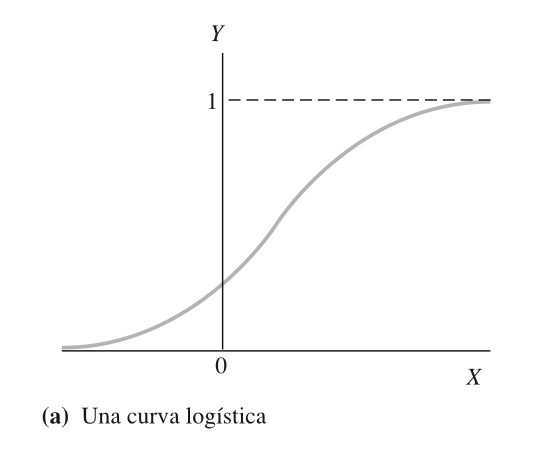
La función logística toma cualquier valor de (x) y lo transforma en un valor entre 0 y 1.
\[ f(x) = \frac{1}{1 + e^{-x}} \]
Donde: - \(f(x)\) es la salida de la función logística para un valor de \(x\). - \(e\) es la base del logaritmo natural (aproximadamente igual a 2.71828).
La función logística La función logística aumenta suavemente a partir de un mínimo de 0 hasta un máximo de 1.
Este es el caso de un modelo no lineal en los parámetros, que efectivamente NO podemos estimar por MCO.
El método más usual para estimar se llama por máxima verosimilitud Etso consiste en iterativamente…
Los detalles más allá de esta explicación,. se escapan a los objetivos de este curso.
Modelo Logit
-Gráficamente:
MPL y logit
Podemos ver a ambos modelos juntos grpaficamente:
Modelos para dicotómica depediente
Modelos para dicotómica depediente
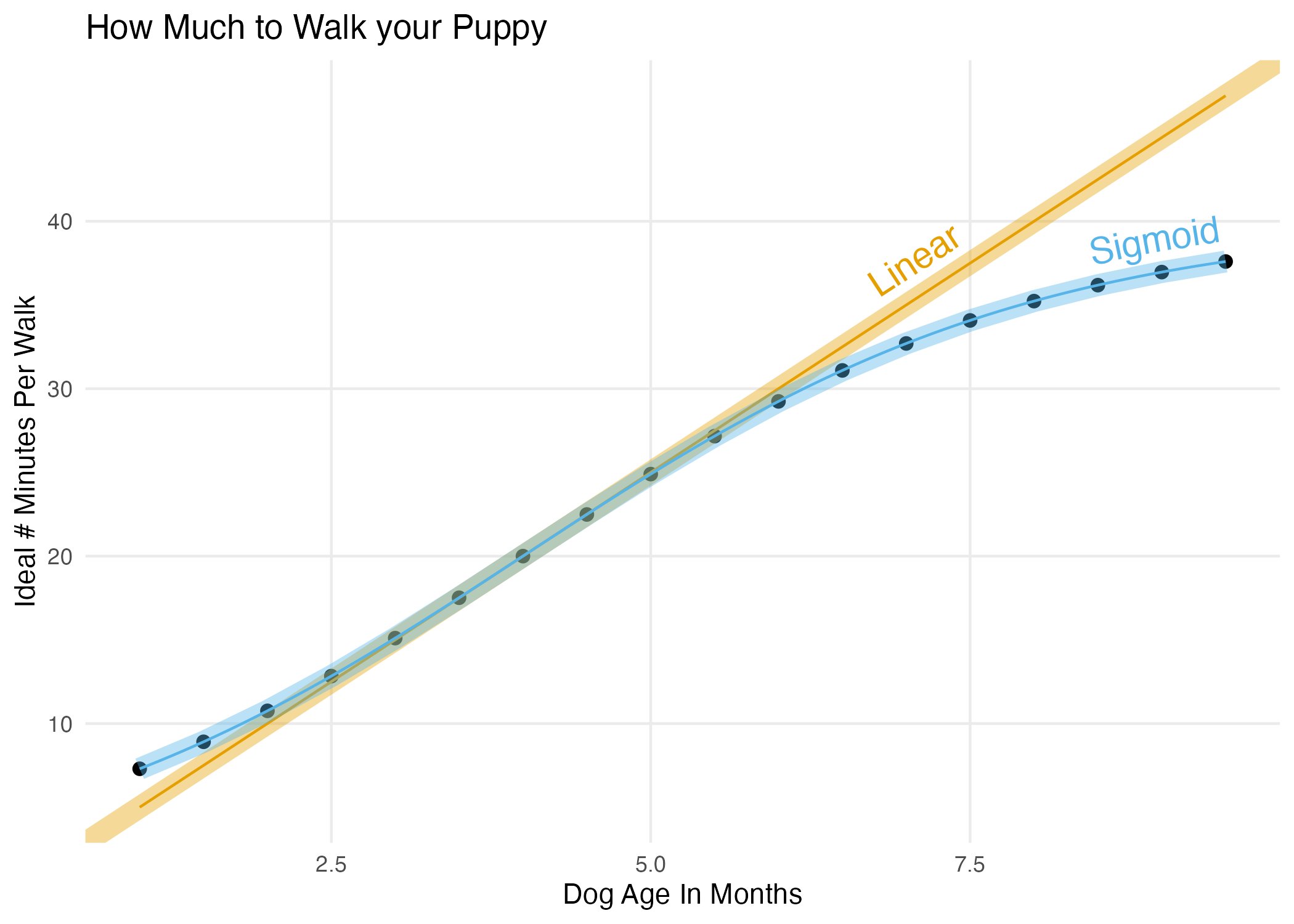
MPL vs Logit
Para un cierto rango de valores, el modelo lineal y Logit pueden ser muy similares:
MPL vs Logit
Pero a veces pueden ser muy diferentes
Ejemplo Probabilidad de Diabetes:
Realicemos un ejemolo, con los datos sobre Diabetes que vienen en el paquete scikit-learn
Carguemos los datos:
import numpy as npimport pandas as pdimport statsmodels.api as smfrom sklearn import datasets# Cargamos el conjunto de datos de diabetes de scikit-learndiabetes = datasets.load_diabetes()X = diabetes.datay = diabetes.target# Creamos un DataFrame de pandas para facilitar la manipulación de datosdf = pd.DataFrame(X, columns=diabetes.feature_names)df['target'] = y# Definimos una variable binaria de respuesta (por ejemplo, si el objetivo es mayor o igual a 200)df['binary_response'] = (df['target'] >=200).astype(int)df.head()
age
sex
bmi
bp
s1
s2
s3
s4
s5
s6
target
binary_response
0
0.038076
0.050680
0.061696
0.021872
-0.044223
-0.034821
-0.043401
-0.002592
0.019907
-0.017646
151.0
0
1
-0.001882
-0.044642
-0.051474
-0.026328
-0.008449
-0.019163
0.074412
-0.039493
-0.068332
-0.092204
75.0
0
2
0.085299
0.050680
0.044451
-0.005670
-0.045599
-0.034194
-0.032356
-0.002592
0.002861
-0.025930
141.0
0
3
-0.089063
-0.044642
-0.011595
-0.036656
0.012191
0.024991
-0.036038
0.034309
0.022688
-0.009362
206.0
1
4
0.005383
-0.044642
-0.036385
0.021872
0.003935
0.015596
0.008142
-0.002592
-0.031988
-0.046641
135.0
0
Ejemplo Probabilidad de Diabetes:
Modelo MPL
# Estimamos un modelo MPL (Regresión por mínimos cuadrados ordinarios)X_mpl = df[['age', 'bmi', 'bp']]X_mpl = sm.add_constant(X_mpl)y_mpl = df['target']mpl_model = sm.OLS(y_mpl, X_mpl)mpl_result = mpl_model.fit()# Imprimimos el resumen del modelo MPLprint(mpl_result.summary())
No olvides instalarlo si no lo tienes: pip install stargazer
Ejemplo Probabilidad de Diabetes:
Ambos modelos
# pip install stargazer #instalar el paquete, si no lo tienesfrom stargazer.stargazer import Stargazerstargazer = Stargazer([logit_result, mpl_result])stargazer.title("Comparación de Modelos Logit y MPL")stargazer.custom_columns(["Modelo Logit", "Modelo MPL"], [1, 1]) # Nombres de los modelosstargazer.add_custom_notes(["Notas personalizadas para la tabla."]) # Notas personalizadasstargazer
Comparación de Modelos Logit y MPL
Modelo Logit
Modelo MPL
(1)
(2)
age
-1.099
25.990
(2.955)
(63.923)
bmi
24.173***
788.783***
(3.191)
(65.562)
bp
14.942***
394.127***
(3.038)
(68.392)
const
-1.265***
152.133***
(0.140)
(2.859)
Observations
442
442
R2
0.396
Adjusted R2
0.392
Residual Std. Error
60.108 (df=438)
F Statistic
95.811*** (df=3; 438)
Note:
*p<0.1; **p<0.05; ***p<0.01
Notas personalizadas para la tabla.
Ejemplo Probabilidad de Diabetes:
Ambos modelos
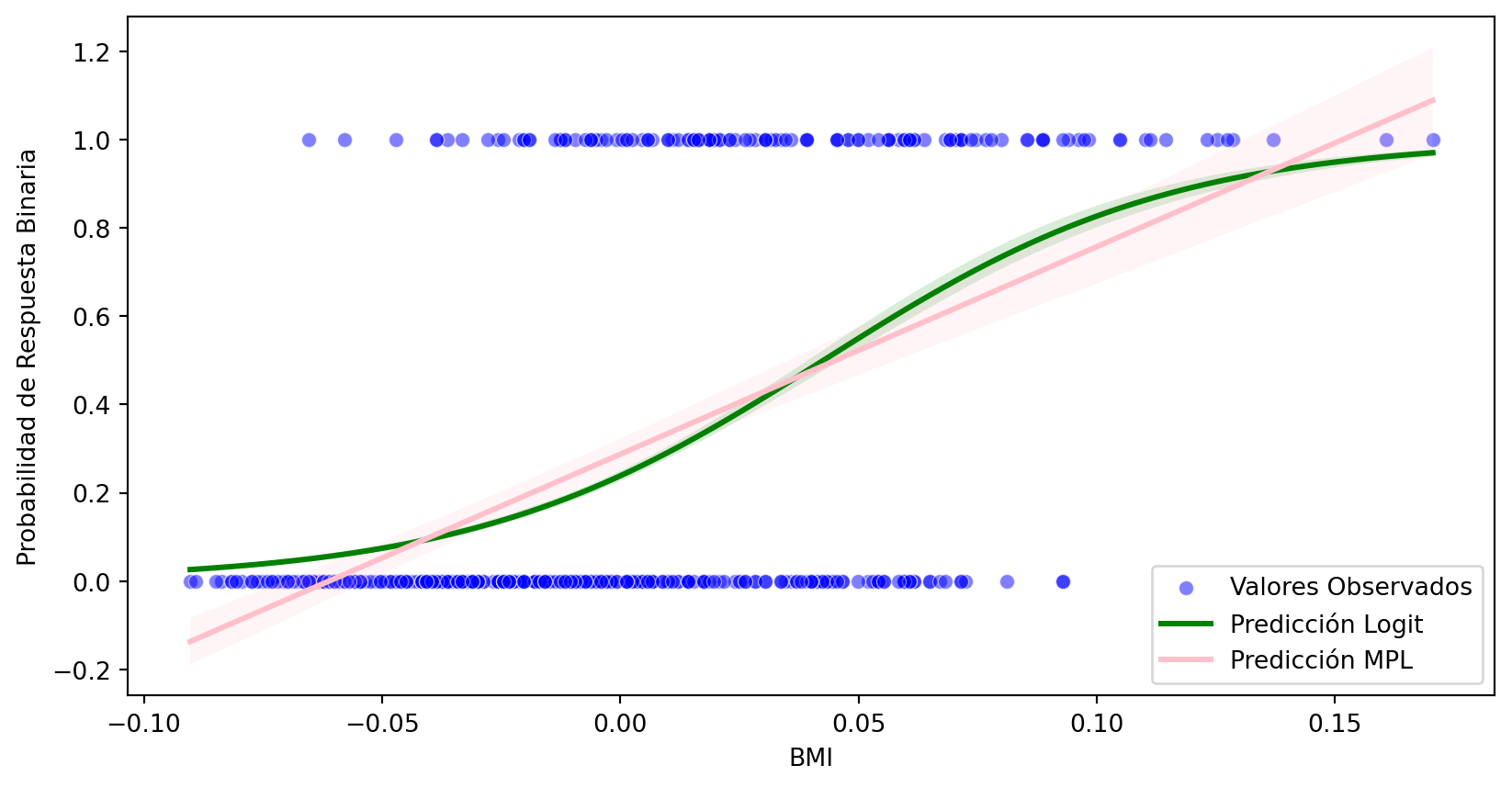
Podemos hacer un grafico con los valores predichos de los modelos:
import seaborn as snsimport matplotlib.pyplot as plt# Grafica los valores observadossns.scatterplot(x='bmi', y='binary_response', data=df, label='Valores Observados', color='blue', alpha=0.5)# Realizamos la predicción del modelo logitlogit_predictions = logit_result.predict(X_logit)# Grafica la función del modelo Logit predichasns.regplot(x='bmi', y=logit_predictions, data=df, logistic=True, ci=95, label='Predicción Logit', color='green', scatter=False)# Grafica la función del modelo Logit predichasns.regplot(x='bmi', y='binary_response', data=df, logistic=False, ci=95, label='Predicción MPL', color='pink', scatter=False)# Configura las etiquetas y la leyendaplt.xlabel('BMI')plt.ylabel('Probabilidad de Respuesta Binaria')plt.legend()# Muestra el gráficoplt.show()
Logit: EFectos marginales
Un elemento importante a tener en cuenta, es que los modelos logit no entregan directo efectos marginales. Por lo cual, generalmente es más complejo interpretar sus resultados. Para etso calculamos los efectos marginales:
# Calcular efectos marginalesmargeff = logit_result.get_margeff(at='mean')# Imprimir los efectos marginalesprint(margeff.summary())
Ahora, si nuestra variable dependiente es categorica, necesitaremos usar otra clase de modelos.
Mencionaremos los más usados:
Conditional Logit: utilizado cuando Y no tiene orden, regresores varían entre alternativas (ej. precio en modo de transporte) y hay más de dos alternativas.
Multinomial Logit: utilizado cuando Y no tiene orden, regresores no varian entre alternativas y hay más de dos alternativas en el conjunto de opciones.
Ordered probit: utilizado cuando Y es discreta en un intervalo finito y con orden lógico. Ejemplo: ¿cuánto le gusta el curso? 1: nada, 2: poco, 3: algo, 4: bastante y 5: mucho.
Nuevamente, mayores detalles van más allá de los objetivos del curso.
Taller de aplicación 2:
Taller aplicacción 2: Datos sobre viviendas
Realicemos un ejercicio de interpretación para poner en práctica estos contenidos:
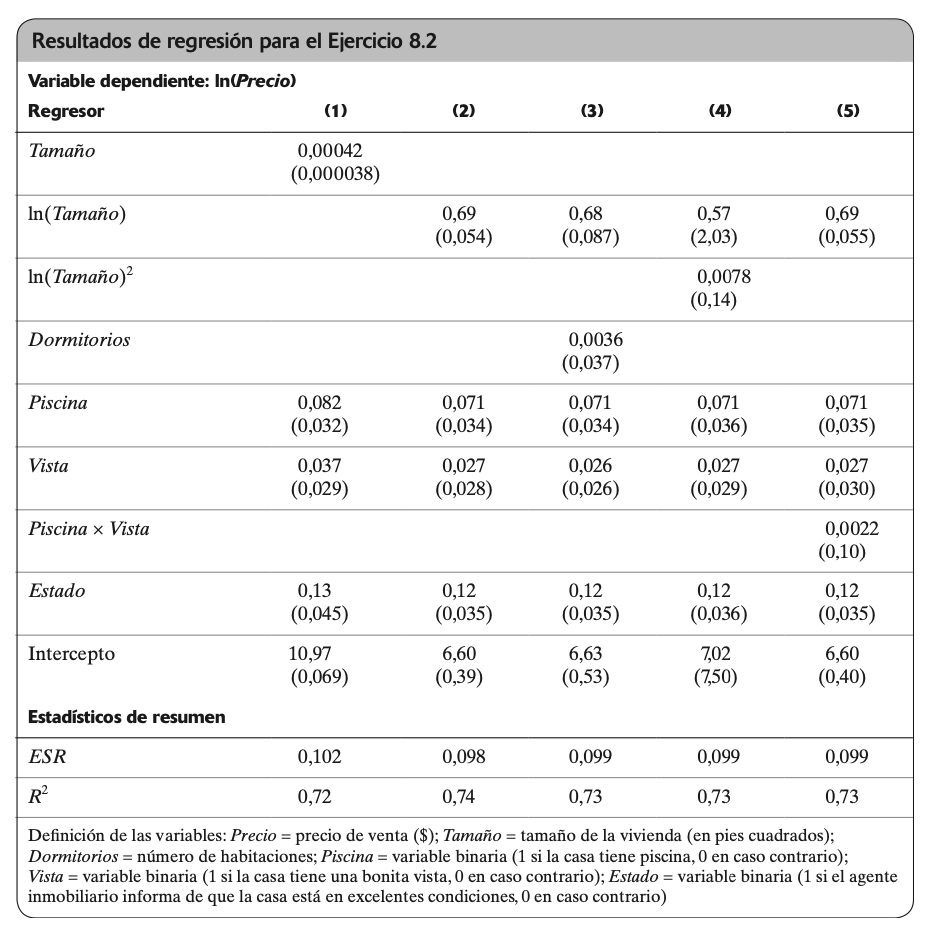
Supóngase que un investigador recoge datos sobre las viviendas que se han vendido en un determinado vecindario durante el año pasado y obtiene los resultados de regresión:
Utilizando los resultados de la columna (1), ¿cuál es la variación esperada en el precio de una vivienda si se construye un anexo a ella de 500 pies cuadrados? Construya un intervalo de confianza al 95 % para la variación porcentual en el precio.
Comparando las columnas (1) y (2), ¿es mejor utilizar la variable Tamaño o la variable ln(Tamaño) para explicar el precio de la vivienda?
Utilizando la columna (2), ¿cuál es el efecto estimado de tener piscina sobre el precio? (Asegúrese de obtener las unidades de forma correcta). Construya un intervalo de confianza al 95 % para este efecto.
La regresión de la columna (3) añade la variable de número de dormitorios a la regresión. ¿Cuál es la cuantía del efecto estimado de tener un dormitorio adicional? ¿Es el efecto estadísticamente significativo? ¿Por qué cree que el efecto estimado es tan pequeño? (Pista: ¿qué otras variables se están manteniendo constantes?)
¿Es el término cuadrático ln(Tamaño)2 importante?
Utilice la regresión de la columna (5) para calcular la variación esperada en el precio cuando se añade una piscina a una casa sin vista. Repita el ejercicio para una vivienda con una buena vista. ¿Existe una gran diferencia? ¿Es la diferencia estadísticamente significativa?
Taller de aplicación 2:
Taller aplicacción 2: Ingreso y educación
Mediante el uso de la encuesta casen 2023 vamos a analizar las condiciones laborales del país.
Estime la ecuación de Mincer, e incorpore información cualitativa.
Estime un MPL para analizar la probabilidad de que una persona participe del mercado laboral. ¿Cuál es el rol del género?
Estime un MPL para analizar la probabilidad de encontrar trabajo.
Estime ambos modelos con Logit
Construya una tabla con los 4 modelos, usando el paquete Stargazer. Compare los resultados
2. Estimación formal análisis de regresión
Terminología
Podemos incluir múltiples variables en el lado derecho de la ecuación:
\[
y = \beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2}+\dots+\beta_{k}x_{k}+u
\]
Donde \(\beta_{0}\) es término constante.
\(\beta_{j}\) es parámetro de pendiente, asociado a la variable \(x_{j} \quad (j=1, \ldots, k)\).
\(u\) es el término de error.
Esta relación se conoce como modelo de regresión lineal múltiple.
El modelo tiene \(k+1\) parámetros (k pendientes + constante).
Ahora, tomamos las derivadas parciales de SRC con respecto al vecor de coeficientes \(\beta\). Si no estuvieramos trabajando en forma matricial, tendriamos que hacerlo respecto a \(\beta_{0}, \beta_{1}, \beta_{2}, \ldots, \beta_{k}\) y los igualamos a cero para encontrar los estimadores de MCO.
En forma matricial es más sencillo de desarrollar:
Esta fórmula nos da los estimadores de MCO para todos los coeficientes del modelo de regresión lineal múltiple.
Ejemplo de Regresión Lineal Múltiple
En su forma matricial
Supongamos que queremos realizar una regresión lineal múltiple para predecir el precio de una casa (\(y\)) en función de dos variables independientes: el área en pies cuadrados (\(x_1\)) y el número de habitaciones (\(x_2\)).
El modelo de regresión es el siguiente:
\[
y = \beta_0 + \beta_1x_1 + \beta_2x_2 + u
\]
Donde:
\(y\) es la variable dependiente (precio de la casa).
\(x_1\) es la primera variable independiente (área en pies cuadrados).
\(x_2\) es la segunda variable independiente (número de habitaciones).
\(\beta_0\), \(\beta_1\), y \(\beta_2\) son los coeficientes que queremos estimar.
\(u\) es el término de error.
Ejemplo de Regresión Lineal Múltiple
En su forma matricial
Ahora, definamos los datos en forma de vectores:
import numpy as np# Datos de las variables independientesx1 = np.array([1500, 2000, 2500, 3000, 3500])x2 = np.array([2, 3, 2, 4, 3])# Variable dependiente (precio de la casa)y = np.array([200000, 280000, 320000, 420000, 380000])# Matriz de diseño X que incluye una columna de unos para la constanteX = np.column_stack((np.ones(len(x1)), x1, x2))X
Los valores en beta contendrán los estimadores de MCO para \(\beta_0\), \(\beta_1\), y \(\beta_2\).
Ejemplo de Regresión Lineal Múltiple
Usando statsmodels
Para replicar este cálculo utilizando un paquete, puedes utilizar la biblioteca de Python llamada statsmodels.
Aquí está cómo hacerlo:
import statsmodels.api as sm# Ajuste del modelo de regresiónmodel = sm.OLS(y, X).fit()# Obtención de los coeficientes estimadoscoef_estimados = model.paramscoef_estimados
coef_estimados contendrá los mismos valores que obtuvimos previamente en beta.
Ejemplo de Regresión Lineal Múltiple
Usando statsmodels: tabla
Una forma común de presentar un modelo de regresión es a través de tablas. En nuestro caso, statsmodels nos entrega una tabla directamente:
model.summary()
OLS Regression Results
Dep. Variable:
y
R-squared:
0.932
Model:
OLS
Adj. R-squared:
0.863
Method:
Least Squares
F-statistic:
13.65
Date:
Wed, 08 Nov 2023
Prob (F-statistic):
0.0683
Time:
10:44:24
Log-Likelihood:
-56.638
No. Observations:
5
AIC:
119.3
Df Residuals:
2
BIC:
118.1
Df Model:
2
Covariance Type:
nonrobust
coef
std err
t
P>|t|
[0.025
0.975]
const
2.211e+04
6.02e+04
0.367
0.749
-2.37e+05
2.81e+05
x1
77.8947
24.407
3.192
0.086
-27.118
182.908
x2
3.684e+04
2.31e+04
1.598
0.251
-6.24e+04
1.36e+05
Omnibus:
nan
Durbin-Watson:
1.675
Prob(Omnibus):
nan
Jarque-Bera (JB):
0.502
Skew:
0.287
Prob(JB):
0.778
Kurtosis:
1.558
Cond. No.
1.12e+04
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 1.12e+04. This might indicate that there are strong multicollinearity or other numerical problems.
Ejemplo de Regresión Lineal Múltiple
Usando statsmodels: coefplot
Otra forma de presentar resultados es a través de los gráficos de coeficientes:
# Paso 1: Importar las bibliotecas necesariasimport seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# Paso 2: Obtener el modelo ajustado (ya lo tienes)# Supongamos que tienes un modelo de regresión llamado 'model' ajustado previamente# Paso 3: Obtener los coeficientes y errores estándar del modelocoeficientes = model.paramserrores_estandar = model.bse# Paso 4: Crear un DataFrame con los coeficientes y errores estándarcoef_df = pd.DataFrame({'Coeficiente': coeficientes, 'Error Estándar': errores_estandar})# Paso 5: Crear el coef plot utilizando seabornplt.figure(figsize=(10, 6))sns.barplot(x='Coeficiente', y=coef_df.index, data=coef_df, ci=None, palette="viridis")# Paso 6: Agregar líneas para los intervalos de confianzafor i, row in coef_df.iterrows(): plt.plot([row['Coeficiente'] -1.96* row['Error Estándar'], row['Coeficiente'] +1.96* row['Error Estándar']], [i, i], 'ro-', markersize=8, lw=2)plt.title('Coeficiente de Parcelas (Coef Plot)')plt.xlabel('Coeficiente')plt.ylabel('Variable Predictor')plt.grid(axis='x', linestyle='--', alpha=0.6)# Paso 7: Mostrar el coef plotplt.show()
Ejemplo de Regresión Lineal Múltiple
Varios modelos en una tabla
Generalmente, no hacemos solo un modelo. Una forma típica es agregar los modelos en cascada.
Hagamos un dataframe con todos los datos:
data = pd.DataFrame({'x1': x1, 'x2': x2, 'y': y})data
x1
x2
y
0
1500
2
200000
1
2000
3
280000
2
2500
2
320000
3
3000
4
420000
4
3500
3
380000
Ejemplo de Regresión Lineal Múltiple
Varios modelos en una tabla
Ajustamos los modelos, con constante
# Modelo de regresión simple para x1model_x1 = sm.OLS(data['y'], sm.add_constant(data['x1'])).fit()# Modelo de regresión simple para x2model_x2 = sm.OLS(data['y'], sm.add_constant(data['x2'])).fit()# Modelo de regresión múltiple para x1 y x2model_multiple = sm.OLS(data['y'], sm.add_constant(data[['x1', 'x2']])).fit()
Ejemplo de Regresión Lineal Múltiple
Varios modelos en una tabla
Armamos nuestra tabla:
from stargazer.stargazer import Stargazerstargazer = Stargazer([model_x1, model_x2, model_multiple])# personalizamos las etiquetas de las columnasstargazer.custom_columns(['Modelo x1', 'Modelo x2', 'Modelo Múltiple'], [1, 1, 1])#veamos la tablastargazer
Dependent variable: y
Modelo x1
Modelo x2
Modelo Múltiple
(1)
(2)
(3)
const
70000.000
100000.000
22105.263
(64342.832)
(110969.751)
(60226.718)
x1
100.000**
77.895*
(24.766)
(24.407)
x2
78571.429
36842.105
(38288.202)
(23062.002)
Observations
5
5
5
R2
0.845
0.584
0.932
Adjusted R2
0.793
0.445
0.863
Residual Std. Error
39157.800 (df=3)
64068.416 (df=3)
31788.777 (df=2)
F Statistic
16.304** (df=1; 3)
4.211 (df=1; 3)
13.646* (df=2; 2)
Note:
*p<0.1; **p<0.05; ***p<0.01
Recta de regresión
Recta de regresión y predicción del modelo
Una vez obtenido el vector de coeficientes, \(\widehat{\beta}\), se expresa la recta de la regresión de la siguiente forma:
Con los coeficientes estimados se puede predecir el valor de \(\widehat{y}\) para cada individuo.
Y también es posible conocer su residuo:
\[ \widehat{u}=y-\widehat{y} \]
Interpretación de resultados
La regresión múltiple permite interpretar los coeficientes como efectos parciales de cada variable manteniendo las demás constantes (ceteris paribus) sin haber obtenido los datos de esa forma: \[ \Delta \widehat{y}=\widehat{\beta_{1}} \Delta x_{1}+\widehat{\beta_{2}} \Delta x_{2}+\widehat{\beta_{3}} \delta x_{3}+\dots+\widehat{\beta_{k}}\Delta x_{k} \]
Es decir, ajustamos las sumas por sus grados de libertad.
El principal atractivo de \(\bar{R}^2\) es que penaliza por el número de regresores.
Note que \(\bar{R}^2\) podría ser negativo.
3. Inferencia de los estimadores
La esencia del análisis de regresión está en realizar un esfuerzo por cuantificar relaciones empíricas entre variables analizando datos.
Mediante la estadística, en especial las pruebas de hipótesis van más allá de calcular valores estimados.
Vamos a determinar que podemos aprender sobre una población mediante una muestra.
¿Es posible que nuestros resultados sean una casualidad? ¿Pueden nuestras teorías ser rechazadas usando los resultados obtenidos de la muestra?
Si la teoría es correcta, ¿cual es la probabilidad de que esta muestra fuera observada?
Propiedades etsdaísticas con los supuestos clásicos
Supuestos clásicos
Modelo lineal
Muestreo Aleatorio
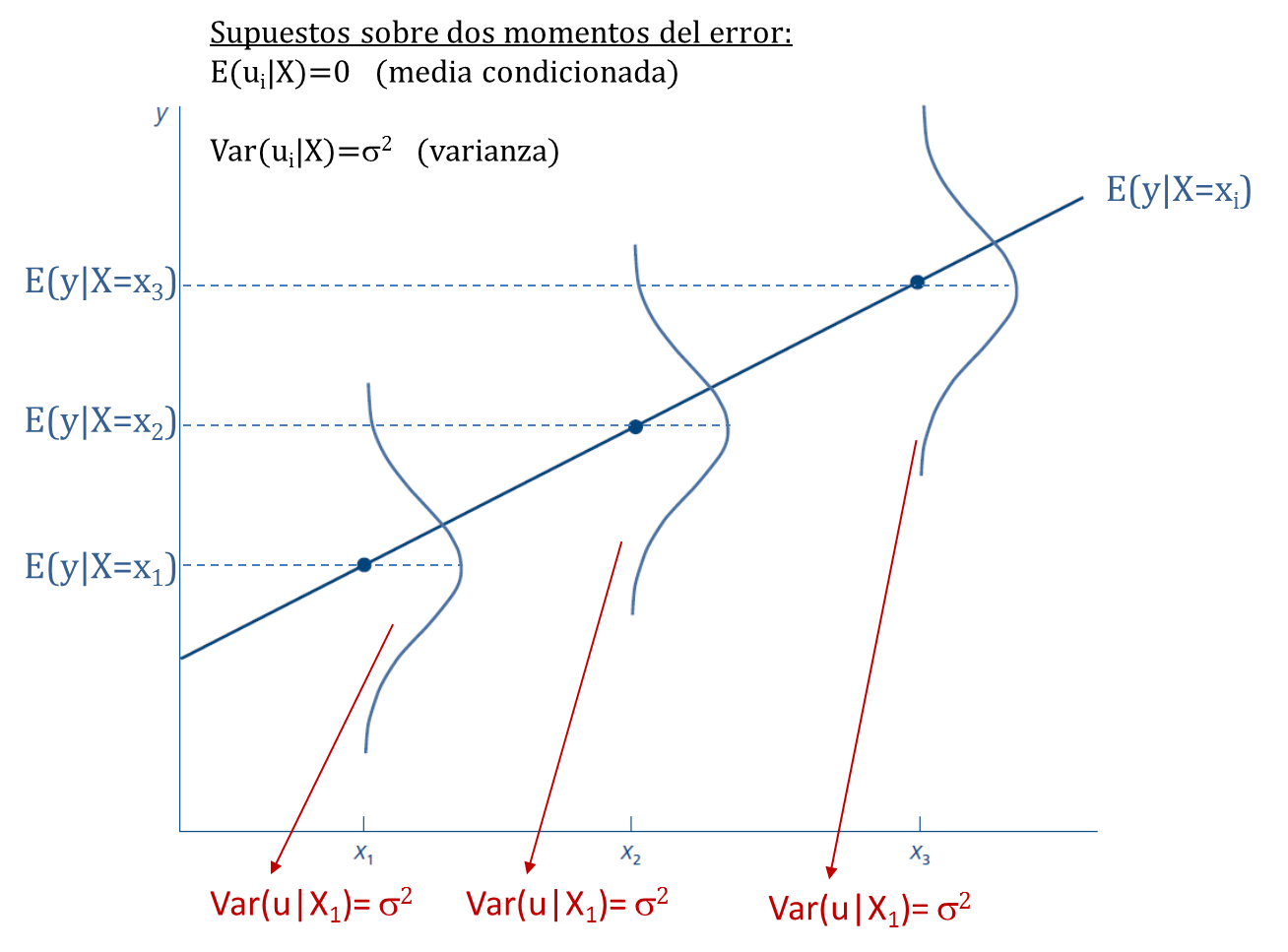
Media condicionada del error nula / Independencia del error o condición de identificación
No multicolonealidad perfecta o suficiente variabilidad en las variables independientes
Homocedasticidad o Varianza constante
Teorema de Gauss-Markov
Bajo supuestos 1-5, los estimadores MCO \(\widehat{\beta}_0, \widehat{\beta}_1,\dots. \widehat{\beta}_k\) son los Mejores Estimadores Lineales Insesgados (MELI)
Propiedades estadisticas MCO
Como \(\hat{\beta}\) es un estimador, tiene distribución, media y varianza.
Para poder conocer sus propiedades estadísticas, necesitamos que esté en función de su valor poblacional, \(\beta\), y el error u.
\(\beta_{\text{omitida}}\) es el efecto de la variable omitida en \(y\).
\(\gamma_{oi}\) es el efecto cruzado de la omitida y la variable \(i\).
Variables Irrelevantes
Consecuencias:
No afecta el sesgo.
MCO no es MELI (Mejor Linealmente Insesgado).
Genera estimadores ineficientes.
Detección:
Teoría
Si la teoría es ambigua, se pueden observar los t.
Corrección:
Eliminar la variable irrelevante.
Forma funcional incorrecta
Elegir una forma funcional.
Lineal en los coeficientes
Apoyarse en la teoría
Incluir una constante aditiva
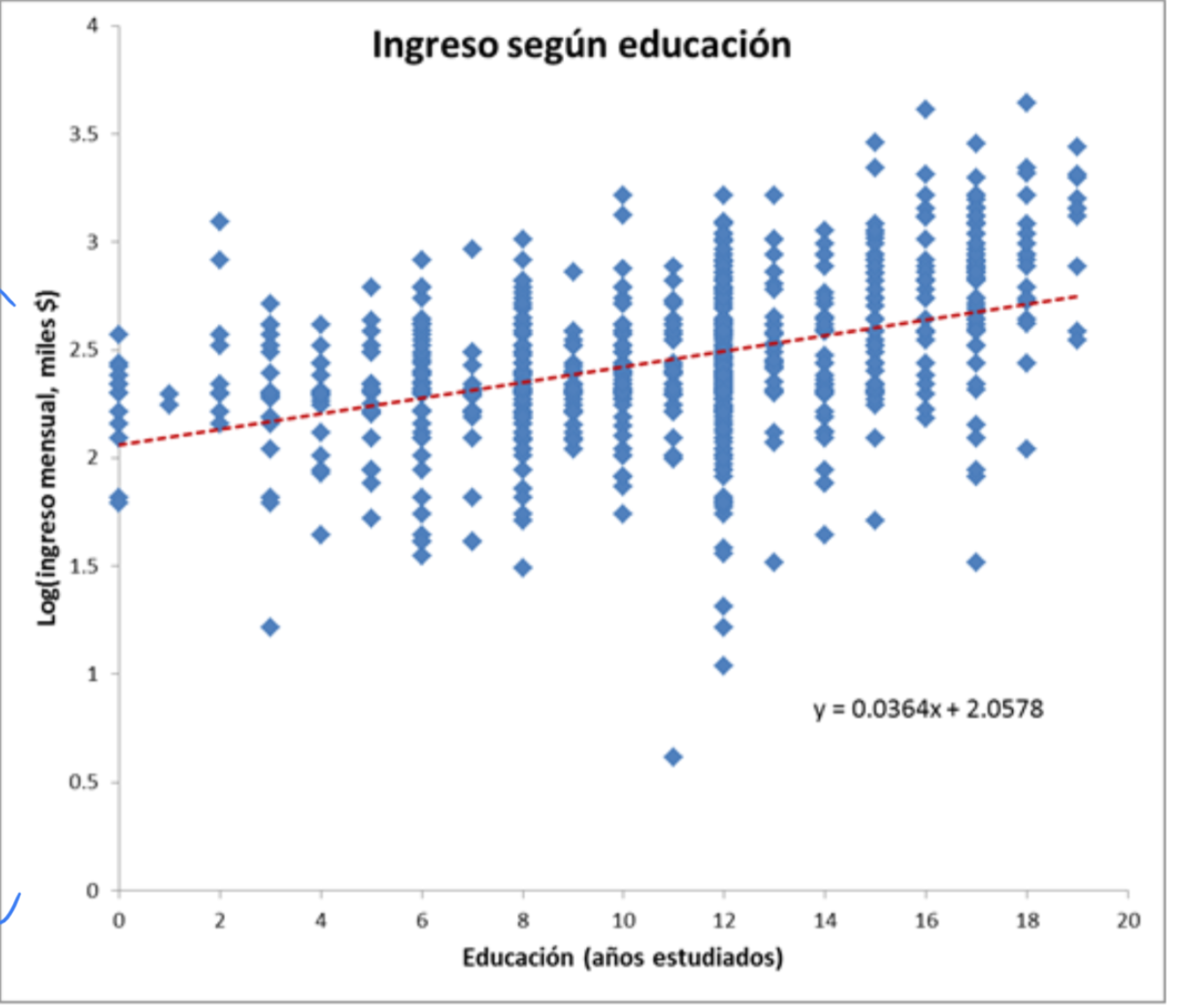
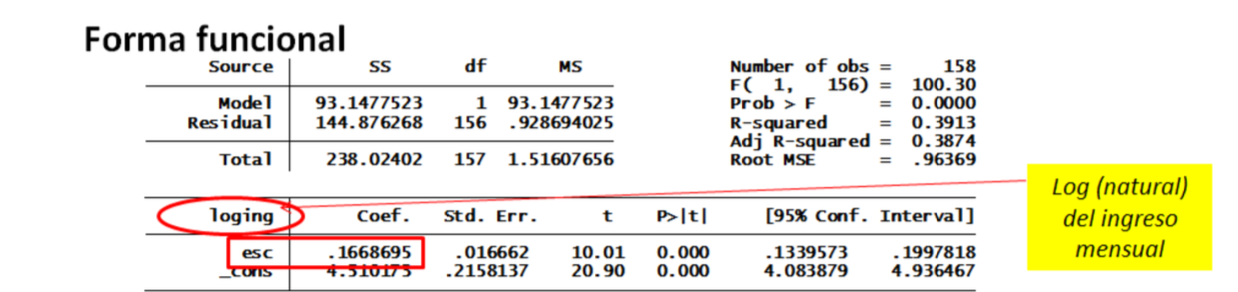
Otras formas funcionales:
Logarítmica (elasticidades, semi-elasticidades)
Cuadrática
Variables Dummy
Multicolinealidad
Definición: Alta relación entre variables (perfecta o imperfecta).
Consecuencias:
\(\hat{\beta}\) aún son insesgados, pero los errores estándar son muy altos.
Detección:
Teoría
Correlación muestral grande (0.8)
Si la relación es entre más de dos variables, VIF (VIF > 5).
Correcciones:
Incrementar los datos.
No hacer nada, nuestros estimadores son insesgados. Podemos usar test conjuntos de significancia.
Eliminar una variable irrelevante, pero riesgo de sesgo por omitida.
Transformar las multicolineares.
Heterocedasticidad
Definición: La varianza de la variable independiente (y el error) es diferente para distintos grupos de individuos o de la población.
Heterocedasticidad
Consecuencias:
No genera sesgo en \(\hat{\beta}\). Ni en los \(R^2\).
Los errores estándar son afectados, lo cual afecta la inferencia.
MCO no es MELI.
Heterocedasticidad
Detección:
Gráfico de los residuos.
Graficar la varianza
Pruebas estadísticas: Test Breush-Pagan o Test de White
Heterocedasticidad
Detección:
Heterocedasticidad
Test Breush-Pagan
Estimamos el modelo.
Estimamos los residuos y su varianza.
Estimamos una regresión de dichos residuos sobre todas las variables.
Si no hay heterocedasticidad, todos los estimadores obtenidos en conjunto son 0.
Heterocedasticidad
Test de White
Estimamos el modelo.
Estimamos los residuos y su varianza.
Estimamos una regresión de dichos residuos sobre todas las variables, su cuadrado y producto cruzado.
Si no hay heterocedasticidad, todos los estimadores obtenidos en conjunto son 0.
Heterocedasticidad
Soluciones a la heterocedasticidad
Se pueden ajustar los errores para que sean válidos o robustos a la presencia de heterocedasticidad.
Podemos corregir la estimación del modelo mediante Mínimos Cuadrados Generalizados o Mínimos Cuadrados Ponderados.
Heterocedasticidad
Soluciones a la heterocedasticidad
Para utilizar errores robustos a la heterocedasticidad en modelos de regresión en statsmodels, puedes utilizar el método get_robustcov_results() después de ajustar tu modelo.
Esto proporcionará resultados que tienen errores estándar robustos a la heterocedasticidad.