Magíster en Data Science - Universidad del Desarrollo
# Paquetes y settingsfrom dateutil.parser import parse import matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as npimport pandas as pd# setting de graficosplt.figure(figsize=(5,3), dpi=200, facecolor='w', edgecolor='k')
<Figure size 1000x600 with 0 Axes>
<Figure size 1000x600 with 0 Axes>
Overview
Resultado de aprendizaje esperado:
Identificar datos de series temporales, sus particularidades y riesgos, en el contexto de posibles aplicaciones profesionales.
Bibliografía recomendada:
Stock & Watson, C.14 link ; Wooldridge, c.12 link, Gujarati, c.12 link
Tipos de datos
Recordemos
Los datos que analizamos con modelos se pueden categorizar en tres grandes tipos:
Corte transversal
Series de tiempo
Panel
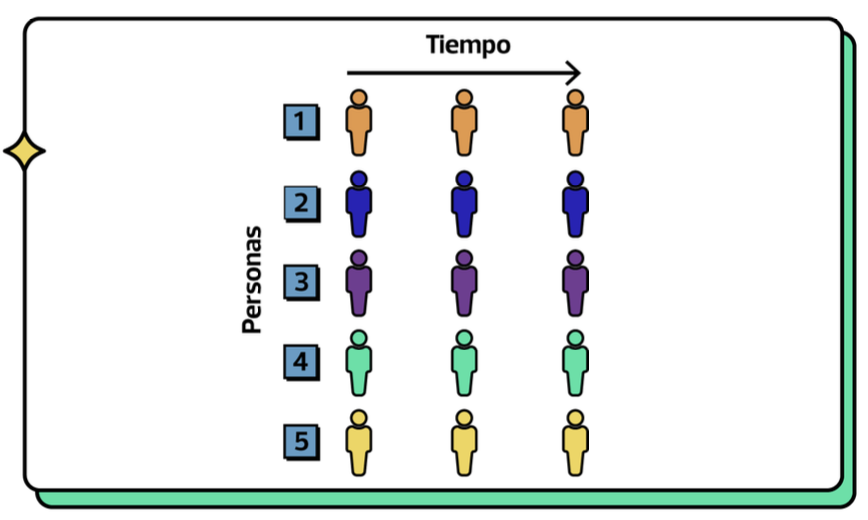
Corte transversal
La unidad de observación son individuos separados unos de otros.
Cada fila reprsenta un individuo (personas, familias, empresas) en un momento del tiempo específico (mismo año, mismo mes, etc). (usualmente)
Estos modelos representan una correlación marginal en las observaciones entre y y x’s (escalada por la varianza de x)
y para que podamos interpretarlas causalmente tenemos varias condiciones o supuestos que de se deben cumplir.
Uno de estos, es el supuesto de exogeneidad: \[ E[u_{i}|X_{i}]=0 \]
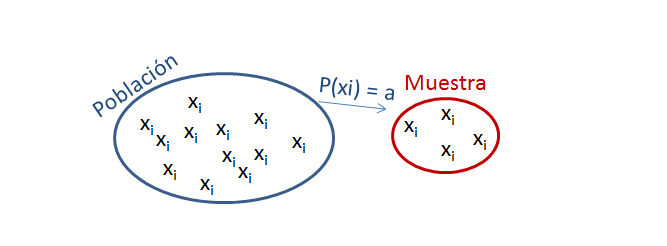
Muestras en corte transversal
Sin embargo, esta forma de ver este supuesto es una simplificación
Como estamos en una muestra aleatoria, no tenemos que verificar que los efectos cruzados tambien sean exogenos:
\[ E[u_{i}|X_{j}]=0 \]
Esto se daba por cumplido, como consecuencia de que era una muestra aletaoria.
Lo cual, generalente, ocurre en corte transversal por lo cual cada observación es i.i.d.
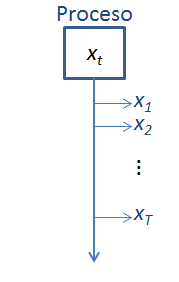
Series de tiempo y procesos estocásticos
En serie de tiempo, nuestro universo es un proceso estocástico
En cada momento se observa un posible resultado (o realización) del proceso estocásticos.
Estimamos modelos de la forma: \[ y_{i}=\beta_{0}+\beta_{1}x_{1i}+\dots+\beta_{1}x_{ki}+u_{i} \]
La imposibilidad de la muestra aleatoria en series de tiempo
Esto tiene vaias implicancias:
NO SON INDEPENDIENTES ya que por construcción, viene del mismo proceso.
Por lo tanto, el supuesto de exogeneidad \(E[u_{i}|X_{i}]=0\) NO ES SUFICIENTE
Requerimos su versión más exigente:
(Exogeneidad estricta): \[E[u_{t}|X_{s}]=0 \qquad \forall s \]
Este supuesto, generalmente NO SE CUMPLE.
Si se cumpliese, seguiruíamos operando como siempre con modelos de regresión multiple estándar.
Trabajando con series de tiempo:
¿Qué hacer entonces?
Reconocer los datos como procesos estocásticos e incluir sus particularidades en la modelación. De eso se tratarán nuestras dos sesiones
Peculiaridades de los procesos estocasticos y su exploración en la data (Sesion 5)
Dependencia temporal, inercia, estacionaerieada y estacionalidad.
Modelos específicos para series de tiempo (Sesión 6)
ARIMA, SARIMAX, GARCH, entre otros
El lenguaje de las series de tiempo
Notación
Variables de series de tiempo se denominan con sub-índice “t” para indicar el perído en el tiempo: \(y_t\)
El total de periodos se suele referir como T.
Transformaciones temporales
Revisemos alginas peculiaridades de las series de tiempo
Dado que una serie de tiempo tiene un orden específico, que en si mismo es importante.
En base a este orden se suelen crear nuevos indicadores o variables.
Revisemos los más comunes:
Rezagos
Diferencias
Tazas de crecimiento
Rezagos
Un rezago es el valor de la variable en períodos anteriores:
Primer rezago: \(y_{t-1}\) es el valor 1 período anterior
Segundo rezago: \(y_{t-2}\) es el valor 2 períodos atrás
j-ésimo rezago: \(y_{t-j}\) es el valor j períodos atrás
Ejemplo rezago
Calculemos el primer y segundo rezago en los datos de amazon:
# Calcular el primer rezago (Lag 1) para la columna 'open'amazon_weekly['open_lag1'] = amazon_weekly['open'].shift(1)# Calcular el segundo rezago (Lag 2) para la columna 'open'amazon_weekly['open_lag2'] = amazon_weekly['open'].shift(2)# Ver los primeros registros del DataFrame con las columnas de rezagoamazon_weekly[['date', 'open', 'open_lag1', 'open_lag2']].head()
date
open
open_lag1
open_lag2
0
2009-11-30
7.1810
NaN
NaN
1
2009-12-07
6.9000
7.181
NaN
2
2009-12-14
6.6250
6.900
7.181
3
2009-12-21
6.5240
6.625
6.900
4
2009-12-28
6.9875
6.524
6.625
Diferencias
Una diferencia corresponde al cambio en una variable entre dos periodos específicos y se usa la notación \(\Delta\)
Primera diferencia: \[\Delta y_t = y_t- y_{t-1}\]
Ejemplo: Calculemos la primera y segunda diferencia en los datos de Amazon:
# Calcular la primera diferencia para la columna 'open'amazon_weekly['open_diff1'] = amazon_weekly['open'] - amazon_weekly['open'].shift(1)# Calcular la segunda diferencia para la columna 'open'amazon_weekly['open_diff2'] = amazon_weekly['open_diff1'] - amazon_weekly['open_diff1'].shift(1)# Ver los primeros registros del DataFrame con las columnas de diferenciaprint(amazon_weekly[['date', 'open', 'open_diff1', 'open_diff2']].head())
date open open_diff1 open_diff2
0 2009-11-30 7.1810 NaN NaN
1 2009-12-07 6.9000 -0.2810 NaN
2 2009-12-14 6.6250 -0.2750 0.0060
3 2009-12-21 6.5240 -0.1010 0.1740
4 2009-12-28 6.9875 0.4635 0.5645
Tasas de crecimiento
Si calculamos la primera diferencia el logaritmo natural, podemos obtener incorporar la tasa de crecimiento en una regresión:
Primera diferencia en logs: \[ \Delta ln(y_{t})=ln(y_{t})-ln(y_{t-1}) \]
Cambio porcentual de \(y_t\) entre \(t -1\) y \(t\approx 100\times \Delta ln(y_{t})\)
Ejemplo Tasa de crecimiento
Calculemos la primera diferencia en logaritmo natural y la taza de crecimiento para la serie de Amazon, en su precio de apertura:
import numpy as np# Calcular el logaritmo natural de la columna 'open' con NumPyamazon_weekly['open_ln'] = np.log(amazon_weekly['open'])# Calcular la primera diferencia en los logaritmos naturales ('open_ln_diff1')amazon_weekly['open_ln_diff1'] = amazon_weekly['open_ln'] - amazon_weekly['open_ln'].shift(1)# Calcular el cambio porcentual entre t-1 y t para 'open' ('open_percent_change')amazon_weekly['open_percent_change'] = (amazon_weekly['open'] - amazon_weekly['open'].shift(1)) / amazon_weekly['open'].shift(1) *100# Ver los primeros registros del DataFrame con las columnas calculadasprint(amazon_weekly[['date', 'open', 'open_ln', 'open_ln_diff1', 'open_percent_change']].head())
date open open_ln open_ln_diff1 open_percent_change
0 2009-11-30 7.1810 1.971439 NaN NaN
1 2009-12-07 6.9000 1.931521 -0.039917 -3.913106
2 2009-12-14 6.6250 1.890850 -0.040671 -3.985509
3 2009-12-21 6.5240 1.875488 -0.015363 -1.524526
4 2009-12-28 6.9875 1.944123 0.068635 7.104537
Tipos de modelos:
Modelo estático
Se modela la relación contemporánea entre dos variables, i.e., relación en el mismo momento en el tiempo
Se incluyen efectos temporales, que se piensan que tienen que ver con tendencias, inercia o estacionalidades
Un modelo con inercia en la inflación (por conceptos): \[ inflación_{t}=\beta_{0}+\beta_{1}desempleo_{t}+\beta_{2} inflación_{t-1} +u_{t}\]
Hay modelos conocidos:
Ejemplo: ARIMA de primer órden \[ \Delta inflacion_t = \phi \cdot \Delta inflacion_{t-1} + \varepsilon_t\]
Supuestos no cumplidos y opciones de modelamiento
Para poder interpretar causalmente un modelo de regresión lineal multiple en series de tiempo necesitamos que se cumplan los siguientes supuestos de Gauss Markov:
Modelo lineal en parámetros \[y_{t}=\beta_{0}+\beta_{1}x_{1t}+\dots+\beta_{1}x_{kt}+u_{t}\]
Media condicionada nula o exogeneidad (que ahora es estricta) \[ E[u_{t}|X_{js}]=0 \quad \forall s\]
No hay colinealidad perfecta.
Homoscedasticidad \[ Var[u_{t}|X_{js}]=\sigma \quad \forall s \]
No hay correlación serial. \[ Cov[u_{t}, u_{s}|X_{js}]=\sigma \quad \forall s\ne t\]
Supuestos no cumplidos y opciones
Cada uno de estos supuestos tiene diferentes implicancias:
1-3 es que el estimador de MCO \(\hat{\beta}\) es insesgado.
4-5 que tiene minima varianza de los estimadores lineales (eficiente)
1-5 -> MELI
Vemos que hay dos elementos diferentes a corte transversal:
cambia la exogeneidad a uno más estricto (ya que no hay muestreo aleatorio)
y aparece un nuevo supuesto, correlación serial.
Objetivos diferentes de los modelos
Los modelos de regresión se pueden usar con dos objetivos principales: predicción y explicación.
En series de tiempo, como no hay muestreo aleatorio, nos enfocaremos en la predicciónn.
Un modelo de regresión puede ser útil para la predicción, aún cuando ninguno de sus coeficientes tenga interpretación causal.
Desde el punto de vista de la predicción, lo que es importante es que el modelo entregue una predicción lo más precisa posible.
La idea base es aprovechar las peculiaridades de las series temporales: la dependencia temporal y tendencias, para identificar patrones en la data que enriquezcan la predicción aun cuando no tengan valor explicativo. Estos elementos los incluiremos DENTRO de la regresión, para que represente de mejor manera el fenómeno a predecir.
Modelos explicativos en series temporales:
Los modelos que se centran en la explicación: Se basen en modelos teoricos estructurales que se corroboran en la data
Se usan otras aproximaciones empíricas como Causalidad de Granger
un concepto estadístico que evalúa si una serie temporal puede predecir otra serie temporal.
Ayuda a determinar si un conjunto de datos precedentes es útil para predecir un conjunto de datos posterior.
Un Concepto relacionado es la cointegración:
La cointegración identifica relaciones estadísticas a largo plazo entre series temporales, lo que puede ser relevante al evaluar la causalidad de Granger.
A pesar de tendencias o patrones a largo plazo, existe una combinación lineal que es estacionaria.
Patrones de dependencia intertemporal
Modelando series de tiempo desde la intuiciónn
¿Cuándo falla supuesto de exogeneidad estricta?
Cuando tenemos particularidades temporales actuando en el proceso estocástico:
Auto-dependencia, la variable depende de si misma en el pasado (variable dependiente rezagada, AR(1) )
Todas estas pueden evitar que nuestras series sean estacionarias
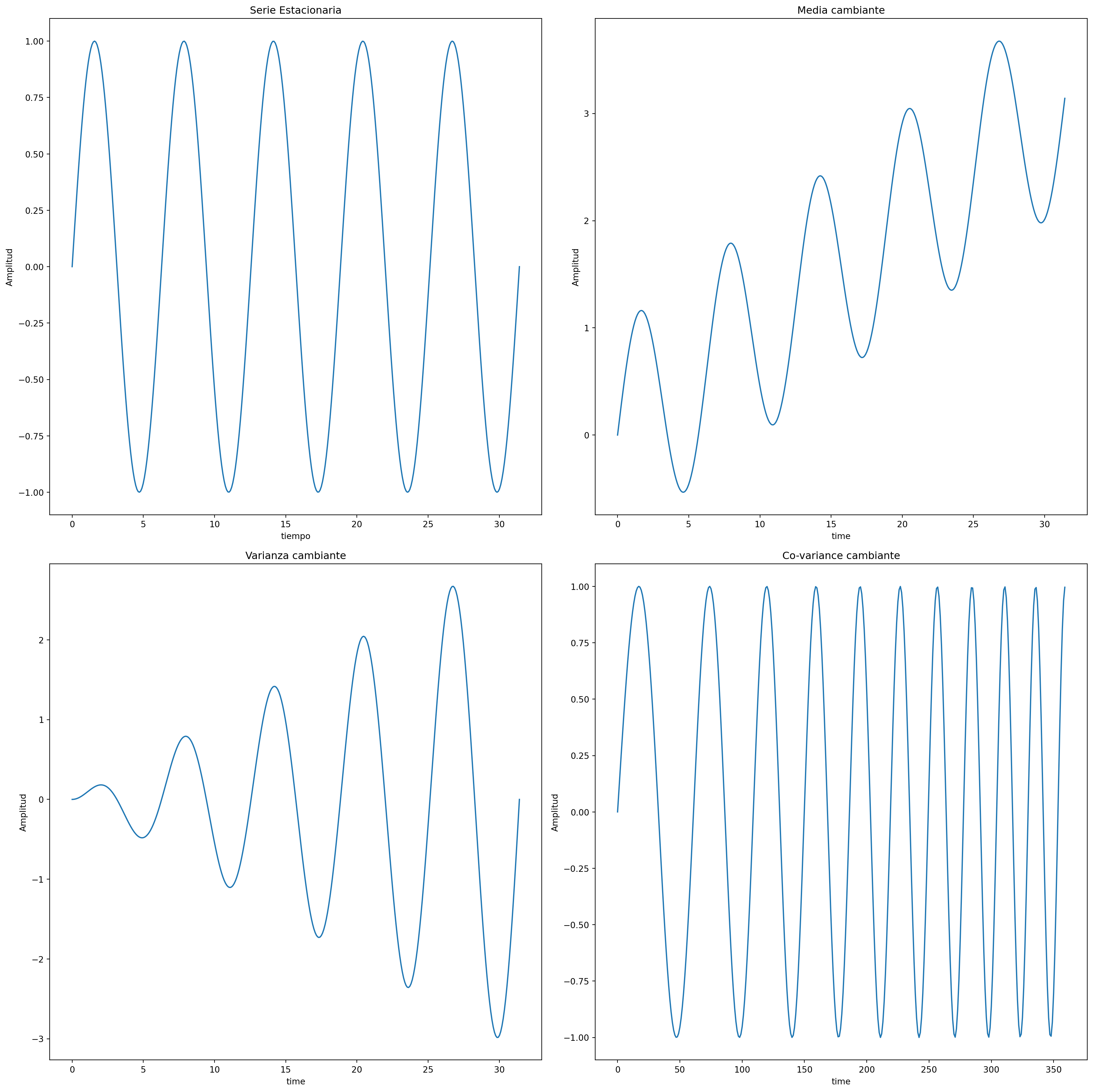
Estacionareidad
Entenderemos estacionareidad si el futuro se parece al pasado, al menos en un sentido probabilistico.
Una serie es estacionaria si:
Su distribución de probabilidad no varia en el tiempo,
Su media, varianza y covarianza es constante
Podemos reemplazar el supuesto de exogeneidad extricta por exogeneidad debil SI la serie es estacionaria.
Ejemplo estacionaereidad
Hay muchos ejemplos de tipos de no estacionareidad.
Ilustremos los más tipicos con unos ejemplos ficticios.
x = np.linspace(0, np.pi*10, 360)y = np.sin(x)
Podemos generar los diferentes tipos con algunas manipulaciones algebráicas.
import matplotlib as pltimport matplotlib.pyplot as pltfig, axs = plt.subplots(2, 2, figsize=(18, 18))axs[0][0].plot(x, y)axs[0][0].set_title('Serie Estacionaria')axs[0][0].set_xlabel('tiempo')axs[0][0].set_ylabel('Amplitud')axs[0][1].plot(x, y+x/10)axs[0][1].set_title('Media cambiante')axs[0][1].set_xlabel('time')axs[0][1].set_ylabel('Amplitud')axs[1][0].plot(x, y*x/10)axs[1][0].set_title('Varianza cambiante')axs[1][0].set_xlabel('time')axs[1][0].set_ylabel('Amplitud')axs[1][1].plot(np.sin(x+x*x/30))axs[1][1].set_title('Co-variance cambiante')axs[1][1].set_xlabel('time')axs[1][1].set_ylabel('Amplitud')plt.tight_layout()
Ausencia de estacionaeridad:
Revisaremos los casos más típicos en los cuales no hay estacionaeridad:
Tendencias
Estacionalidad
Quiebre estructural
Ausencia de estacionareidad 1: Tendencias
Un claro ejemplo de series no estacionarias es cuando hay tendencias.
Podemos identificar la tendencia a través de una media movil
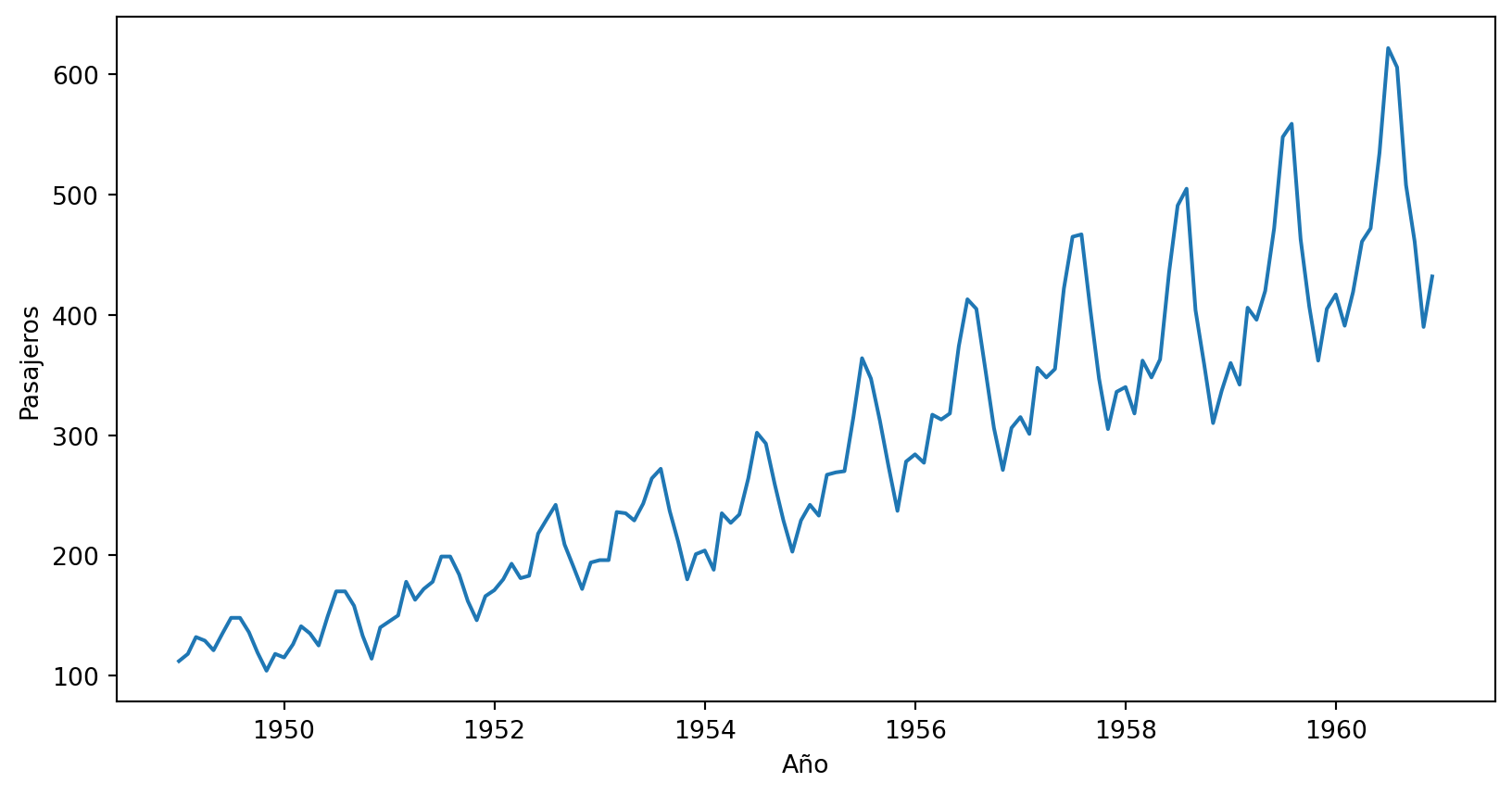
Revisemoslo con los datos de pasajeros de aerolineas.
import pandas as pd# Cargar datosairline = pd.read_csv('data_sesion5/international-airline-passengers.csv', sep=';')# Nota: si no les reconoce bien la dependencia de la carpeta, pueden usar también#airline= pd.read_csv("https://github.com/melanieoyarzun/taller_seriestiempo_IDS/blob/8c0b9774be8d4103da3801d3069d82b4fe006461/Data/international-airline-passengers.csv?raw=true", sep=';')airline['Month'] = pd.to_datetime(airline['Month']+'-01')airline.set_index('Month', inplace=True)airline.head()
Passengers
Month
1949-01-01
112
1949-02-01
118
1949-03-01
132
1949-04-01
129
1949-05-01
121
Ausencia de estacionareidad 1: Tendencias
Ejemplo Aerolinea
Con un grafico rápido, identificamos que está todo bien y que efectivamente se observa que la serie no es estacionaria.
. . .
import matplotlib as mplimport matplotlib.pyplot as pltfig, ax = plt.subplots(1, 1)ax.plot(airline.index, airline['Passengers'])ax.set_xlabel('Año')ax.set_ylabel('Pasajeros')
Text(0, 0.5, 'Pasajeros')
Ausencia de estacionareidad 1: Tendencias
Ejemplo Aerolinea
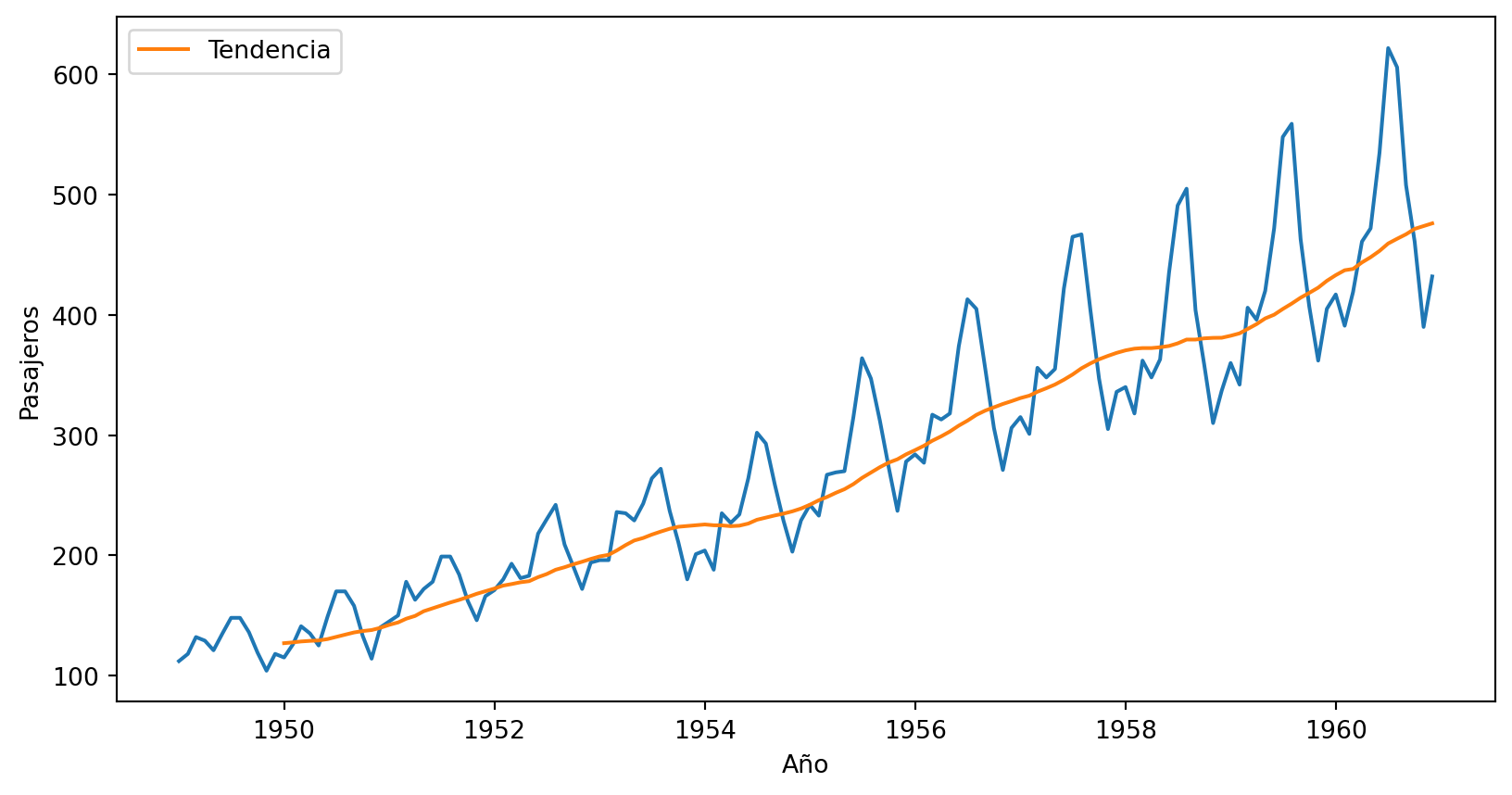
Podemos identificar la tendencia en los datos, al calcular la media movil.
Definimos una función para calcular la media móvil:
. . .
def running_average(x, order): current = x[:order].sum() running = []for i inrange(order, x.shape[0]): current += x[i] current -= x[i-order] running.append(current/order)return np.array(running)
Esta función es autoexplicativa.
Simplemente corre en el dataset paso a paso y calcula la media en una ventana específica.
Ausencia de estacionareidad 1: Tendencias
Ejemplo Aerolinea
Ahora podemos agregar esta línea de tendencia al gráfico anterior.
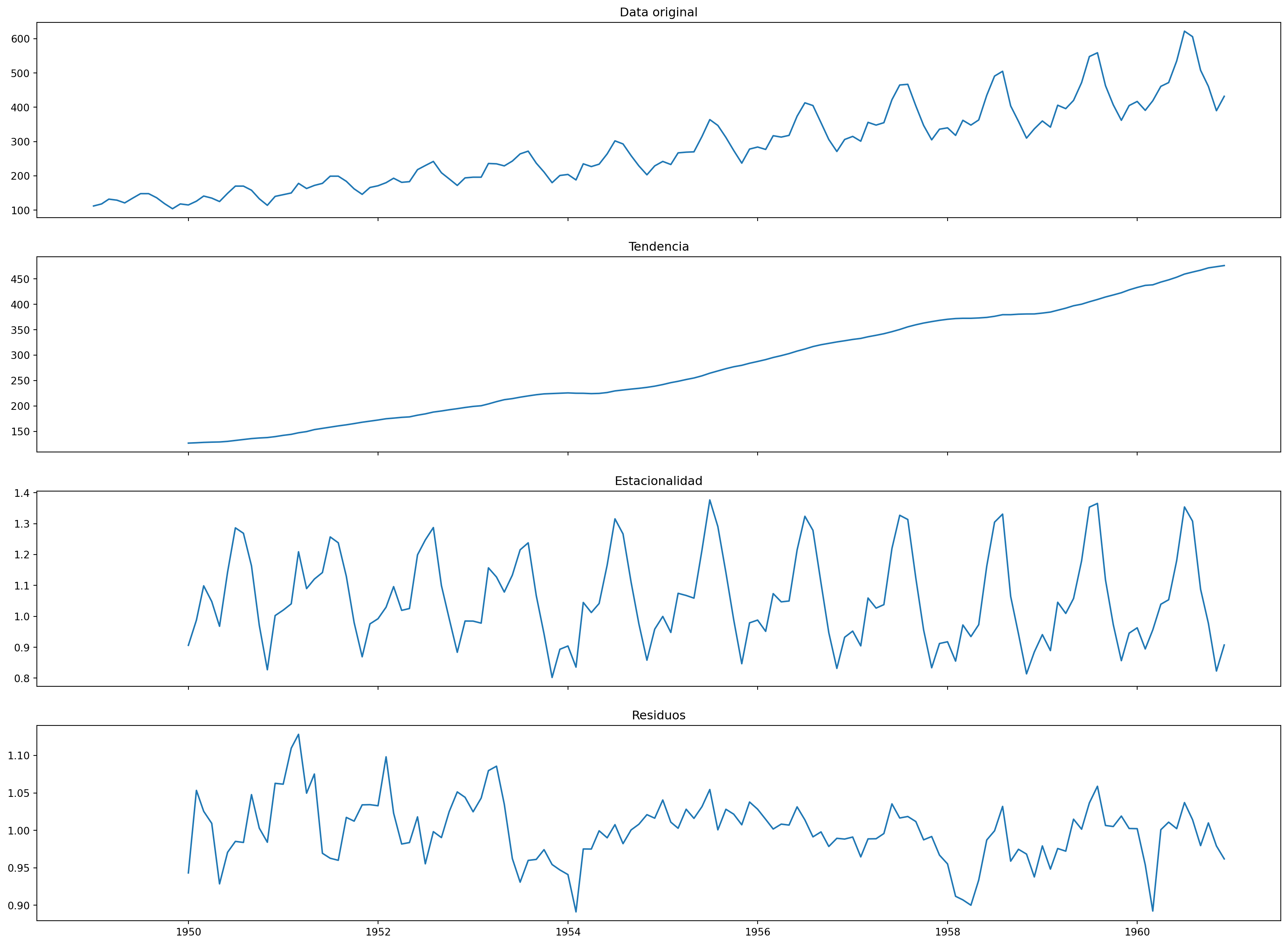
Acá usamos una descomposición multiplicativa, pero este mismo proneso se podría haber hecho siguiendo una descomposición aditiva, con pequeños cambios al codigo.
Ausencia de estacionareidad 3: Quiebre estructural
Otro tipo de no estacionaeridad se presenta cuando la función de regresión poblacional cambia en el transcurso de la las observaciones.
Esto puede ocurrir por varios motivos, por ejemplo cambios en una politica económica, cambios en la estructura de la economía, un nuevo invento o disrupción tecnológica, etc.
Si ocurren tales “cambios estructurales” o “rupturas”, entonces un modelo de regresión que no tenga en cuenta esos cambios puede proporcionar una base engañosa para la inferencia ya la predicción.
Ausencia de estacionareidad 3: Quiebre estructural
Identificación
Las estrategias para identificar un cambio estructurale son varias revisaremos dos:
Contrastes de hipótesis comparando cambios en los coeficientes de regresión mediante estadístico F o Test de Chow.
La segunda es biuscar potenciales cambios estructurales desde la predicción: se simula que la mmuestra termina antes de lo que realmente lo hace y se comparan las predicciones.
Los cambios estructurales se detectan cuando la capacidad de predicción es sustancialmente peor de lo esperado.
Ausencia de estacionareidad 3: Quiebre estructural
Ejemplo datos de amazon
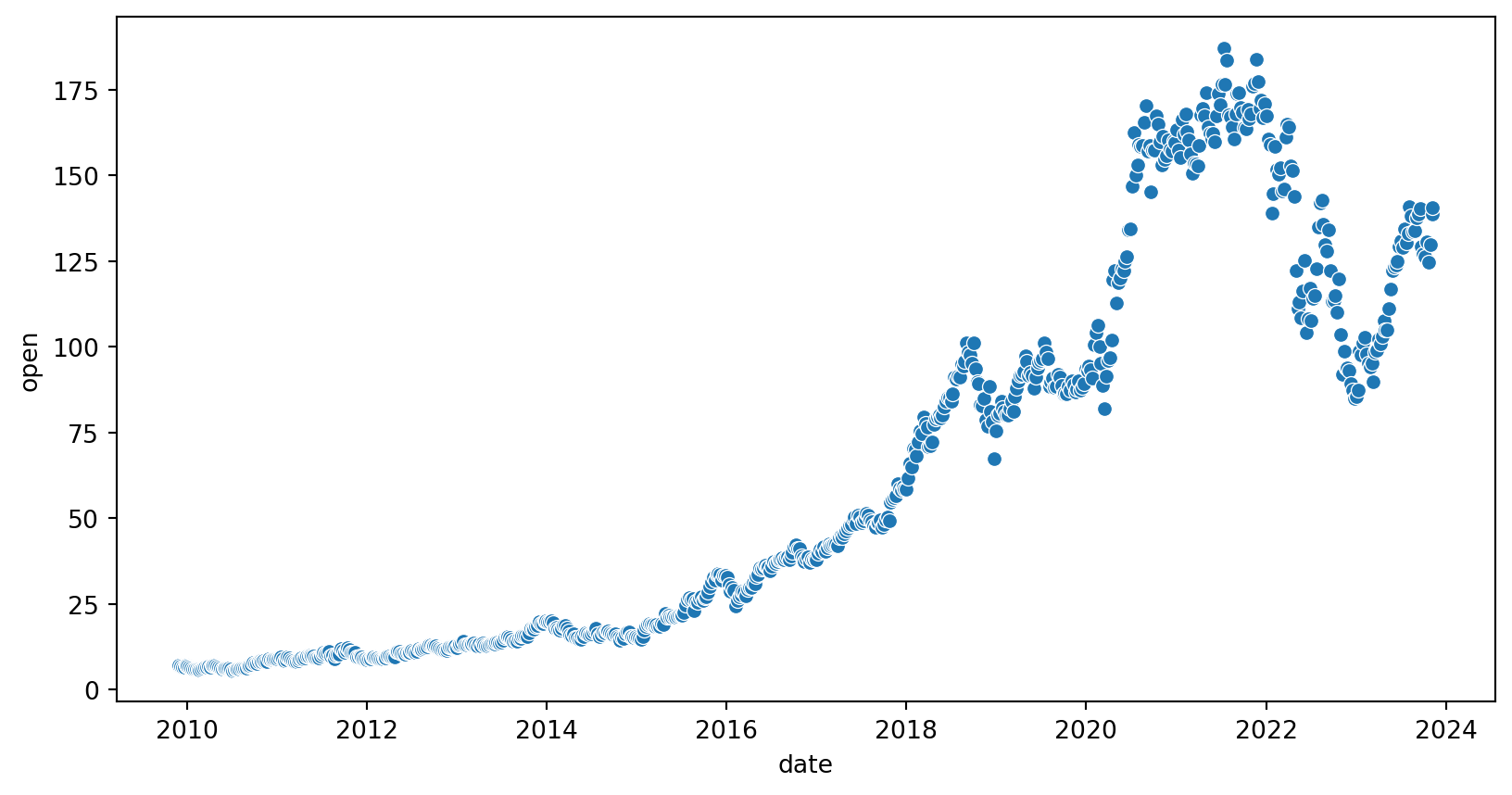
Podemos utilizar datos de acciones y verificar si hay un quiebre estructural antes y después de la crisis financiera de 2008.
Para hacerlo, necesitaremos datos históricos de acciones y realizaremos análisis de series temporales.
. . .
# Importar las bibliotecas necesariasimport numpy as npimport pandas as pdimport statsmodels.api as smimport matplotlib.pyplot as plt# Obtener datos históricos de acciones de Amazonfrom yahoo_fin.stock_info import get_dataamazon_subprime= get_data("amzn", start_date="12/04/2000", end_date="25/09/2015", index_as_date =False, interval="1wk")amazon_subprime.head()
date
open
high
low
close
adjclose
volume
ticker
0
2000-12-04
1.259375
1.381250
1.006250
1.171875
1.171875
1013370000
AMZN
1
2000-12-11
1.143750
1.375000
1.087500
1.143750
1.143750
804546000
AMZN
2
2000-12-18
1.037500
1.059375
0.743750
0.778125
0.778125
1390856000
AMZN
3
2000-12-25
0.815625
0.925000
0.750000
0.778125
0.778125
678338000
AMZN
4
2001-01-01
0.790625
0.893750
0.678125
0.728125
0.728125
866064000
AMZN
Ausencia de estacionareidad 3: Quiebre estructural
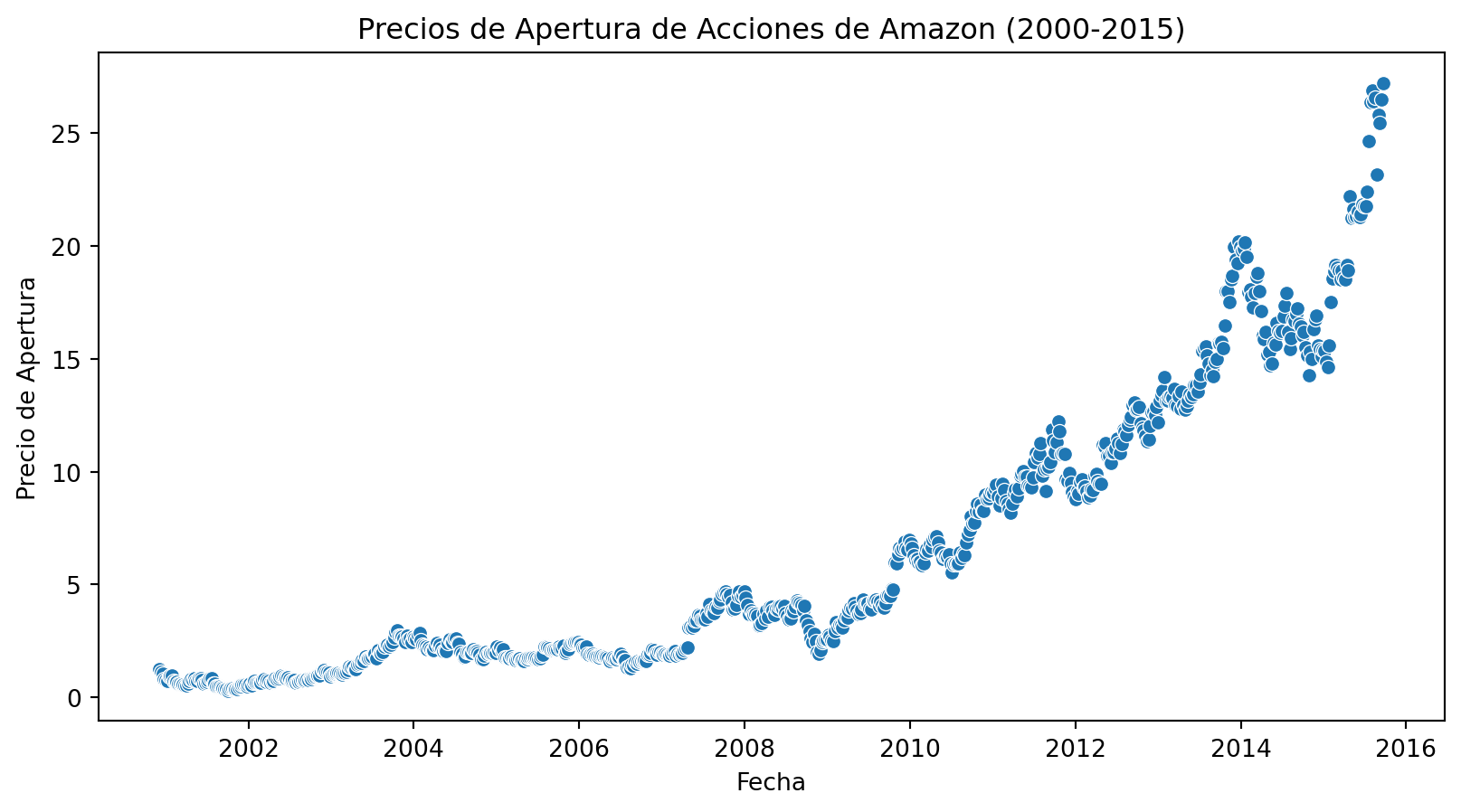
Ejemplo datos de amazon
Graficamos los datos
import seaborn as sns# Crea el scatterplotsns.scatterplot(data=amazon_subprime, y="open", x="date")plt.xlabel("Fecha")plt.ylabel("Precio de Apertura")plt.title("Precios de Apertura de Acciones de Amazon (2000-2015)")plt.show()
Ausencia de estacionareidad 3: Quiebre estructural
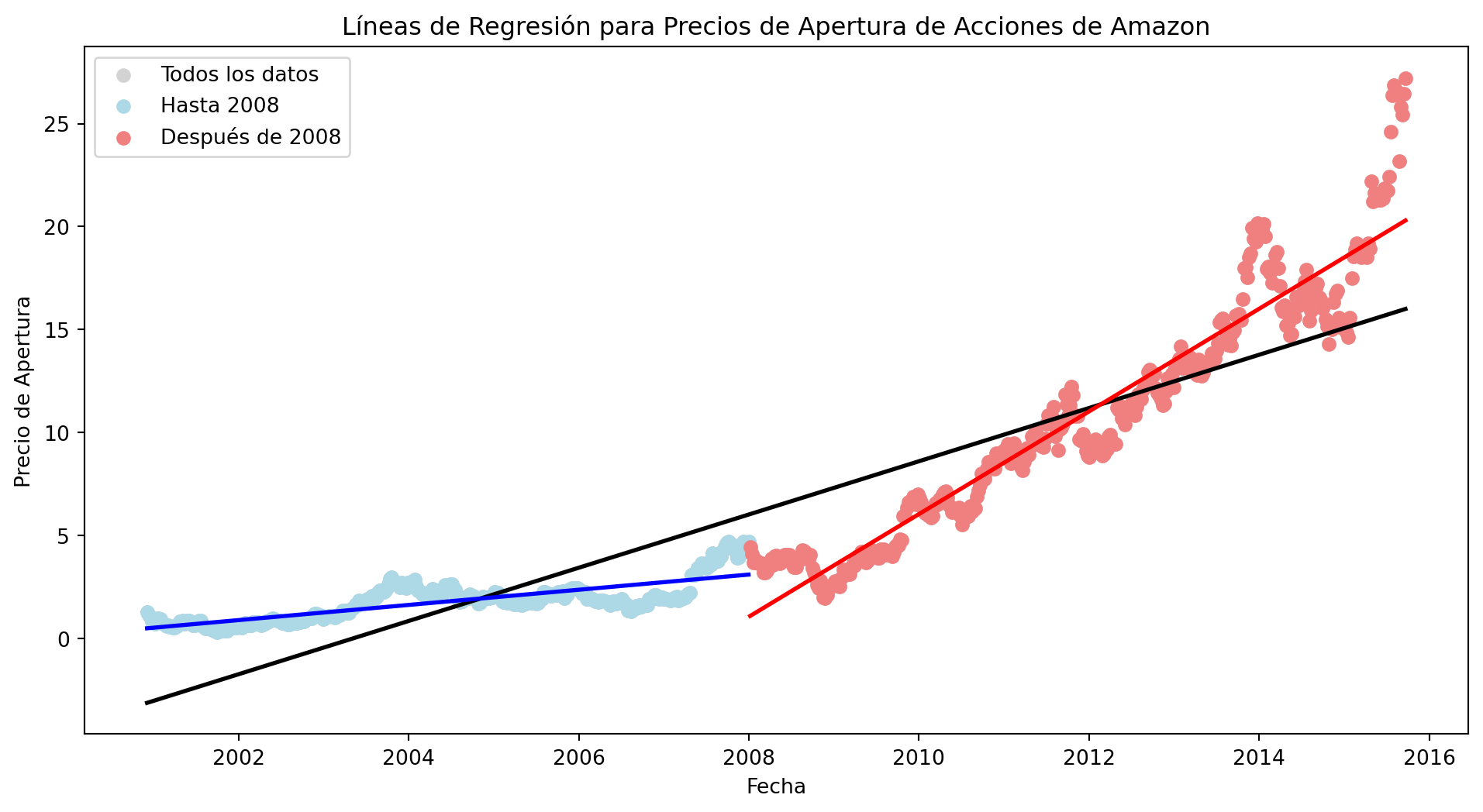
Ejemplo datos de amazon
Podriamos ajustar un modelo a todos los datos o separar anres y después de la crisis subprime.
. . .
# Dividir los datos en tres conjuntos: antes de 2008, después de 2008 y todos los datosdata_before_2008 = amazon_subprime[amazon_subprime['date'] <'2008-01-01']data_after_2008 = amazon_subprime[amazon_subprime['date'] >='2008-01-01']# Ajustar modelos de regresión lineal para cada conjunto de datosmodel_all_data = sm.OLS(amazon_subprime['open'], sm.add_constant(np.arange(len(amazon_subprime)))).fit()model_before_2008 = sm.OLS(data_before_2008['open'], sm.add_constant(np.arange(len(data_before_2008)))).fit()model_after_2008 = sm.OLS(data_after_2008['open'], sm.add_constant(np.arange(len(data_after_2008)))).fit()# Graficar los datos y las líneas de regresiónplt.figure(figsize=(12, 6))# Datos de todos los datos (en negro)plt.scatter(amazon_subprime['date'], amazon_subprime['open'], color='lightgray', label='Todos los datos')# Línea de regresión para todos los datos (en negro)plt.plot(amazon_subprime['date'], model_all_data.predict(sm.add_constant(np.arange(len(amazon_subprime)))), color='black', linewidth=2)# Datos hasta 2008 (en azul)plt.scatter(data_before_2008['date'], data_before_2008['open'], color='lightblue', label='Hasta 2008')# Línea de regresión hasta 2008 (en azul)plt.plot(data_before_2008['date'], model_before_2008.predict(sm.add_constant(np.arange(len(data_before_2008)))), color='blue', linewidth=2)# Datos después de 2008 (en rojo)plt.scatter(data_after_2008['date'], data_after_2008['open'], color='lightcoral', label='Después de 2008')# Línea de regresión después de 2008 (en rojo)plt.plot(data_after_2008['date'], model_after_2008.predict(sm.add_constant(np.arange(len(data_after_2008)))), color='red', linewidth=2)plt.xlabel("Fecha")plt.ylabel("Precio de Apertura")plt.title("Líneas de Regresión para Precios de Apertura de Acciones de Amazon")plt.legend()plt.show()
Ausencia de estacionareidad 3: Quiebre estructural
Ejemplo datos de amazon
-Claramente, los modelos por separados oarecen que explican mejor. - Al parecer hay quiebre estructural. - Revisemos usando el test de Chow:
# Dividir los datos en dos conjuntos: antes de 2008 y después de 2008data_before_2008 = amazon_subprime[amazon_subprime['date'] <'2008-01-01']data_after_2008 = amazon_subprime[amazon_subprime['date'] >='2008-01-01']# Ajustar modelos de regresión lineal para cada conjunto de datosmodel_before_2008 = sm.OLS(data_before_2008['open'], sm.add_constant(np.arange(len(data_before_2008)))).fit()model_after_2008 = sm.OLS(data_after_2008['open'], sm.add_constant(np.arange(len(data_after_2008)))).fit()# Calcular SSR para cada modelossr_before_2008 = np.sum(model_before_2008.resid **2)ssr_after_2008 = np.sum(model_after_2008.resid **2)# Combinar todos los datos en un solo modeloall_data = amazon_subprime['open']model_all_data = sm.OLS(all_data, sm.add_constant(np.arange(len(amazon_subprime)))).fit()# Calcular SSR para el modelo completossr_all_data = np.sum(model_all_data.resid **2)# Calcular el estadístico F para el Test de Chowk =2# Número de coeficientes (incluyendo el intercepto)N =len(amazon_subprime)f_statistic = ((ssr_all_data - (ssr_before_2008 + ssr_after_2008)) / k) / ((ssr_before_2008 + ssr_after_2008) / (N -2* k))# Calcular el valor p asociado al estadístico Ffrom scipy.stats import fp_value =1- f.cdf(f_statistic, k, N -2* k)print("Valor p del Test de Chow:", p_value)
Valor p del Test de Chow: 1.1102230246251565e-16
Podemos usar paquetes que tengan el test directamente programado. Por ejemplo chowtest
Ausencia de estacionareidad 3: Quiebre estructural
Ejemplo datos de amazon
Podemos ver los tres modelos en una tabla integrada:
from stargazer.stargazer import Stargazer# Crear una lista de modelos que deseas incluir en la tablamodelos = [model_before_2008, model_after_2008, model_all_data]# Crear una lista de etiquetas para los modelosetiquetas = ["Modelo Antes de 2008", "Modelo Después de 2008", "Modelo Completo"]# Configurar Stargazerstargazer = Stargazer(modelos)stargazer.custom_columns(etiquetas, [1, 1, 1]) # Asignar etiquetas a las columnas# Generar la tabla HTML o LaTeX #tabla = stargazer.render_html() # Para HTML# tabla = stargazer.render_latex() # Para LaTeX# Imprimir la tablastargazer