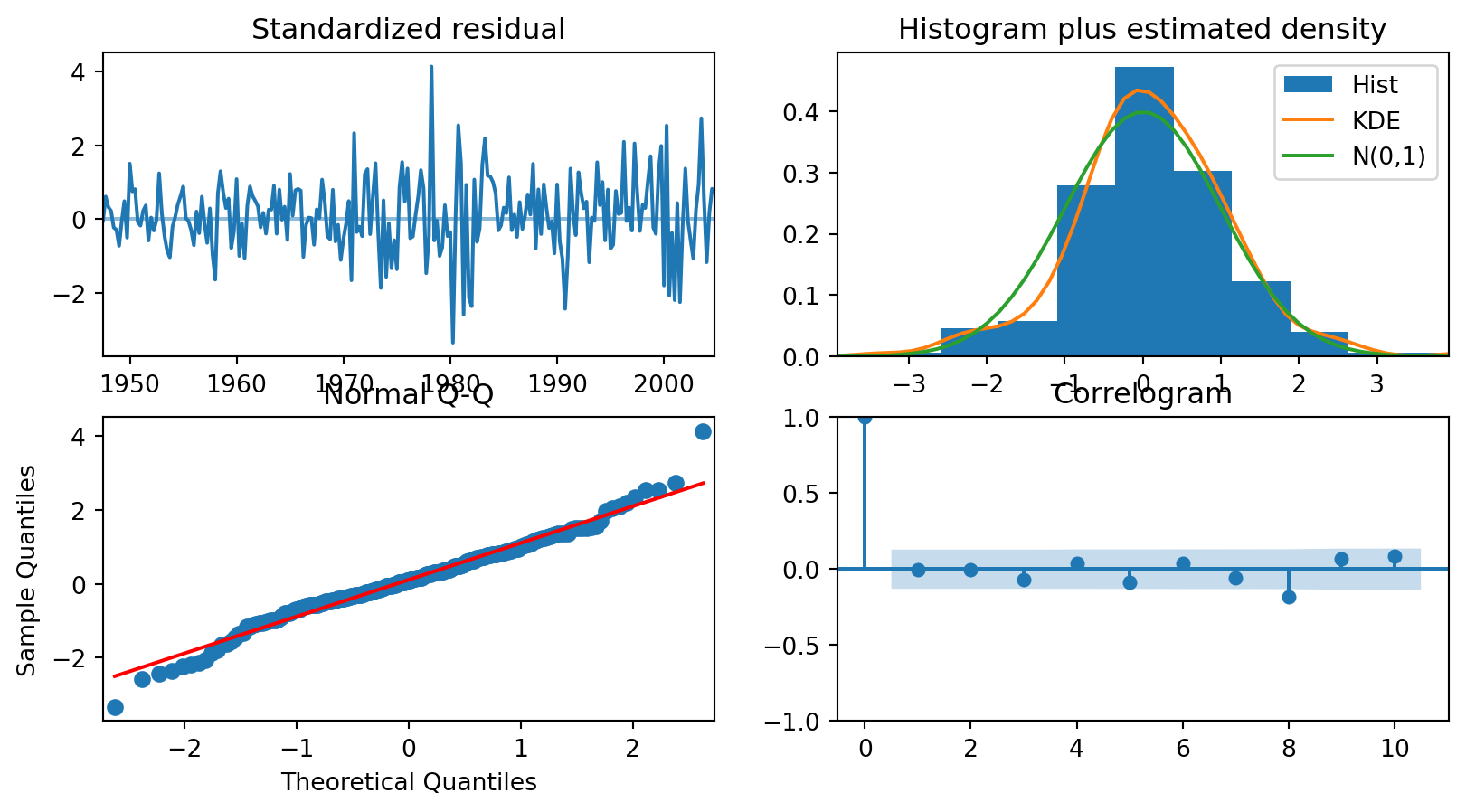
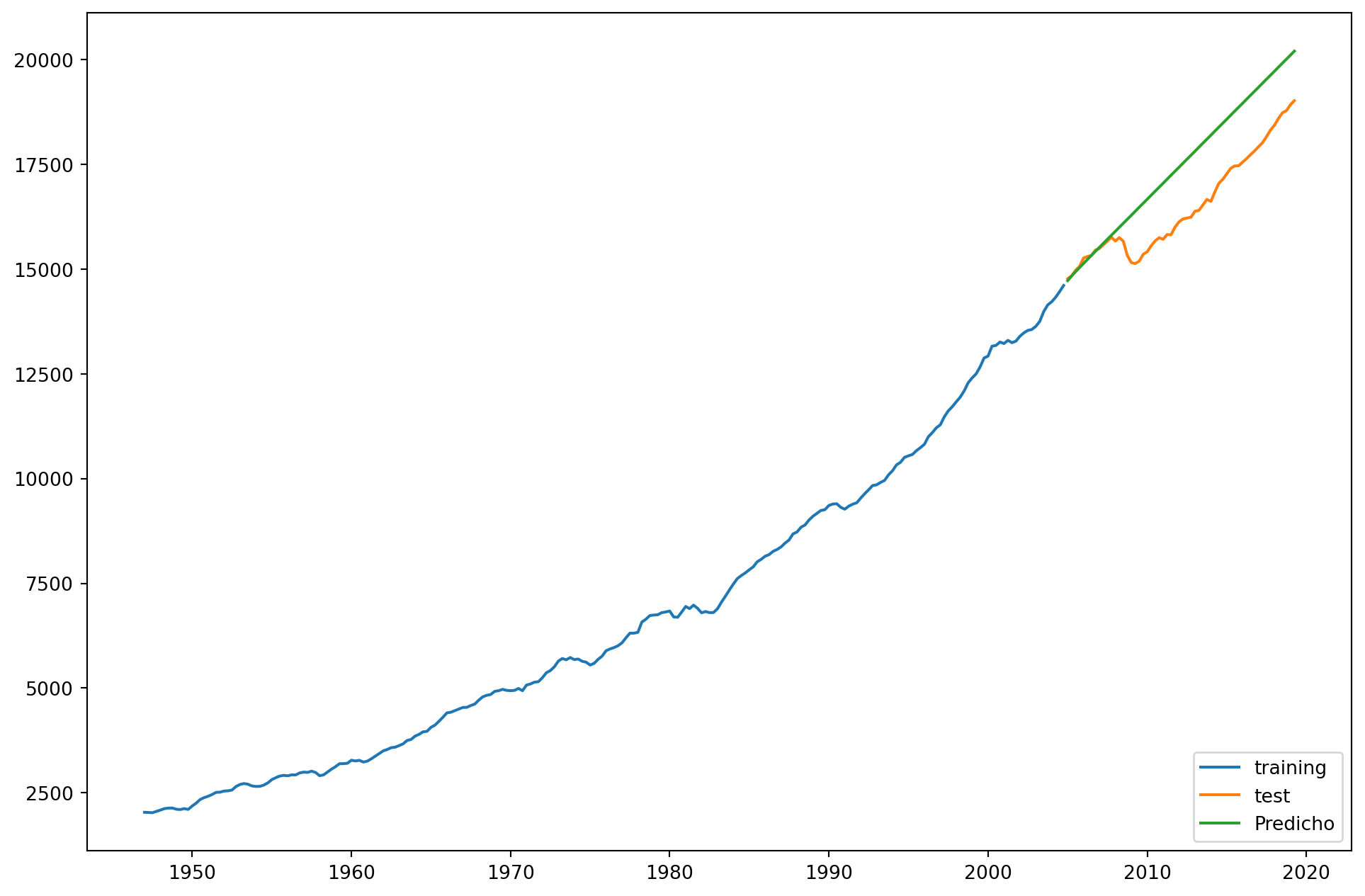
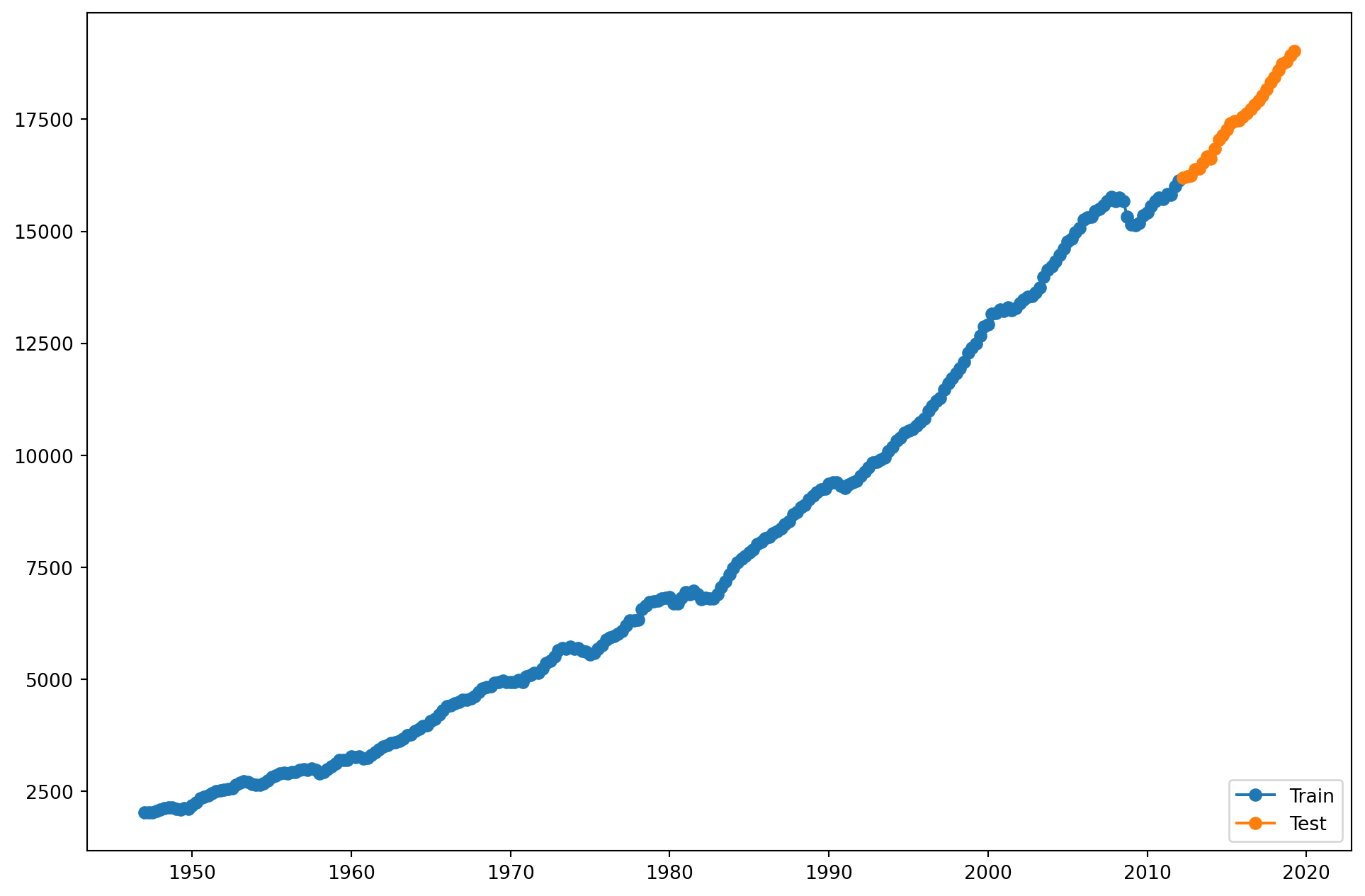
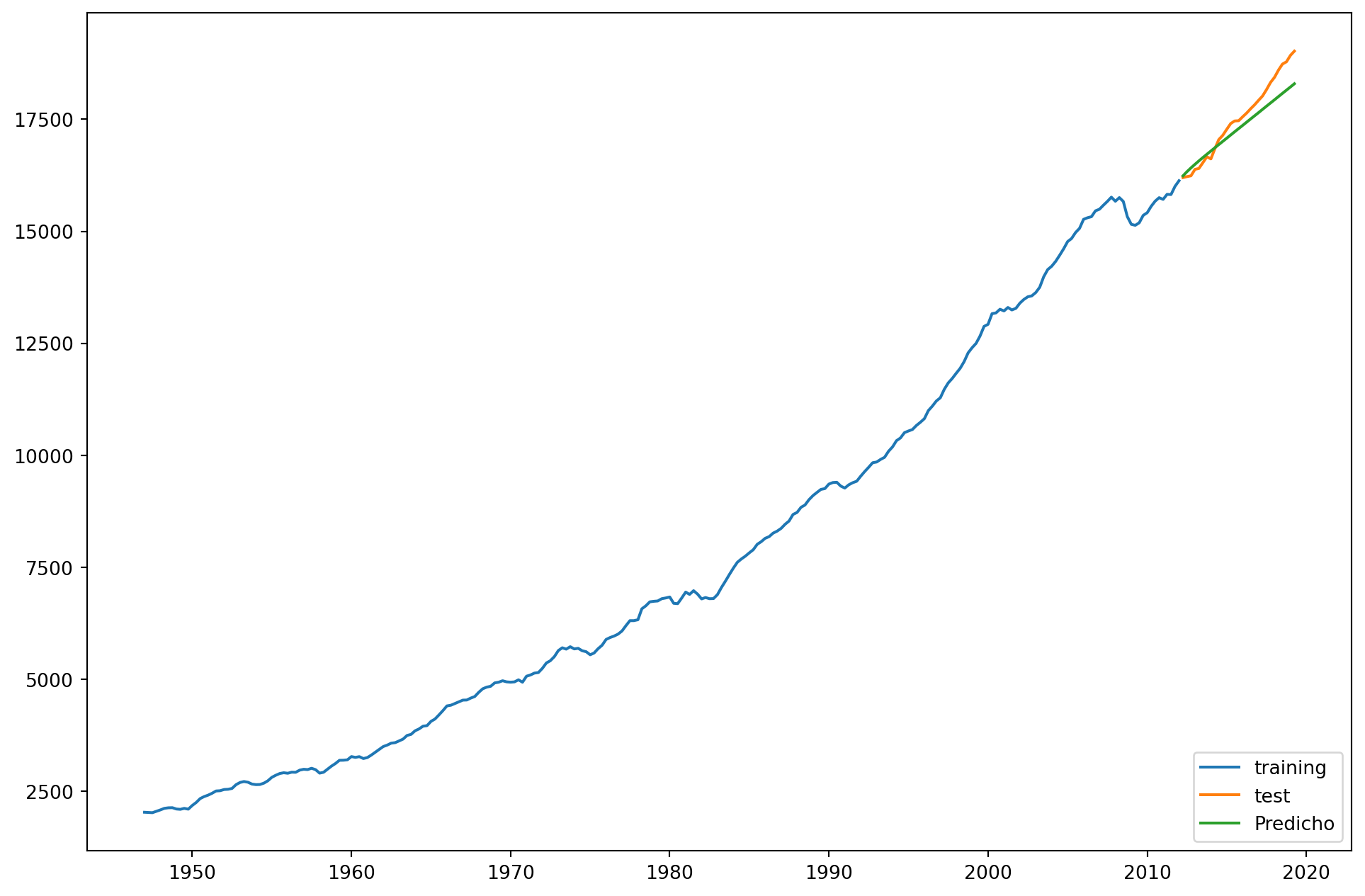
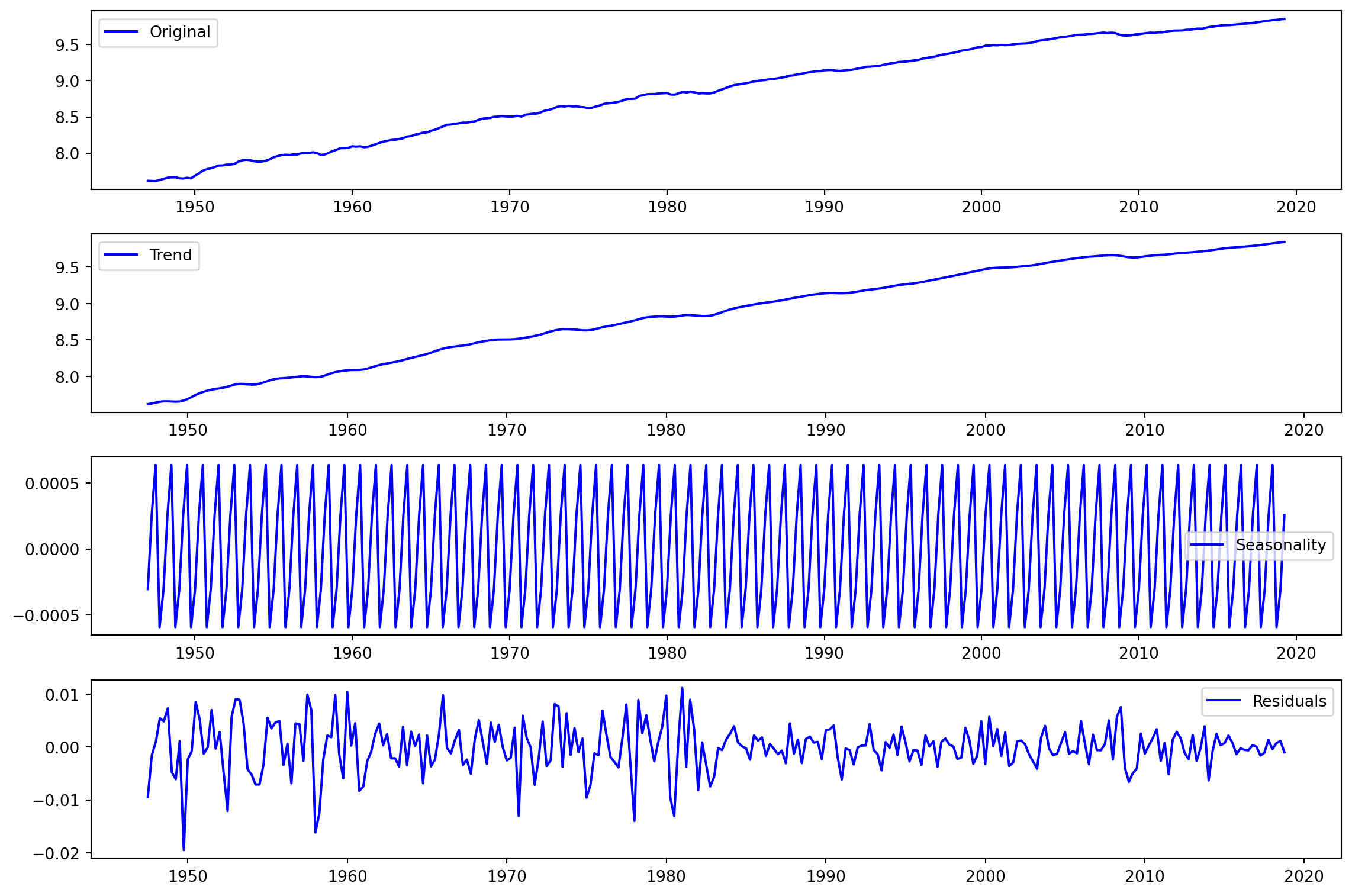
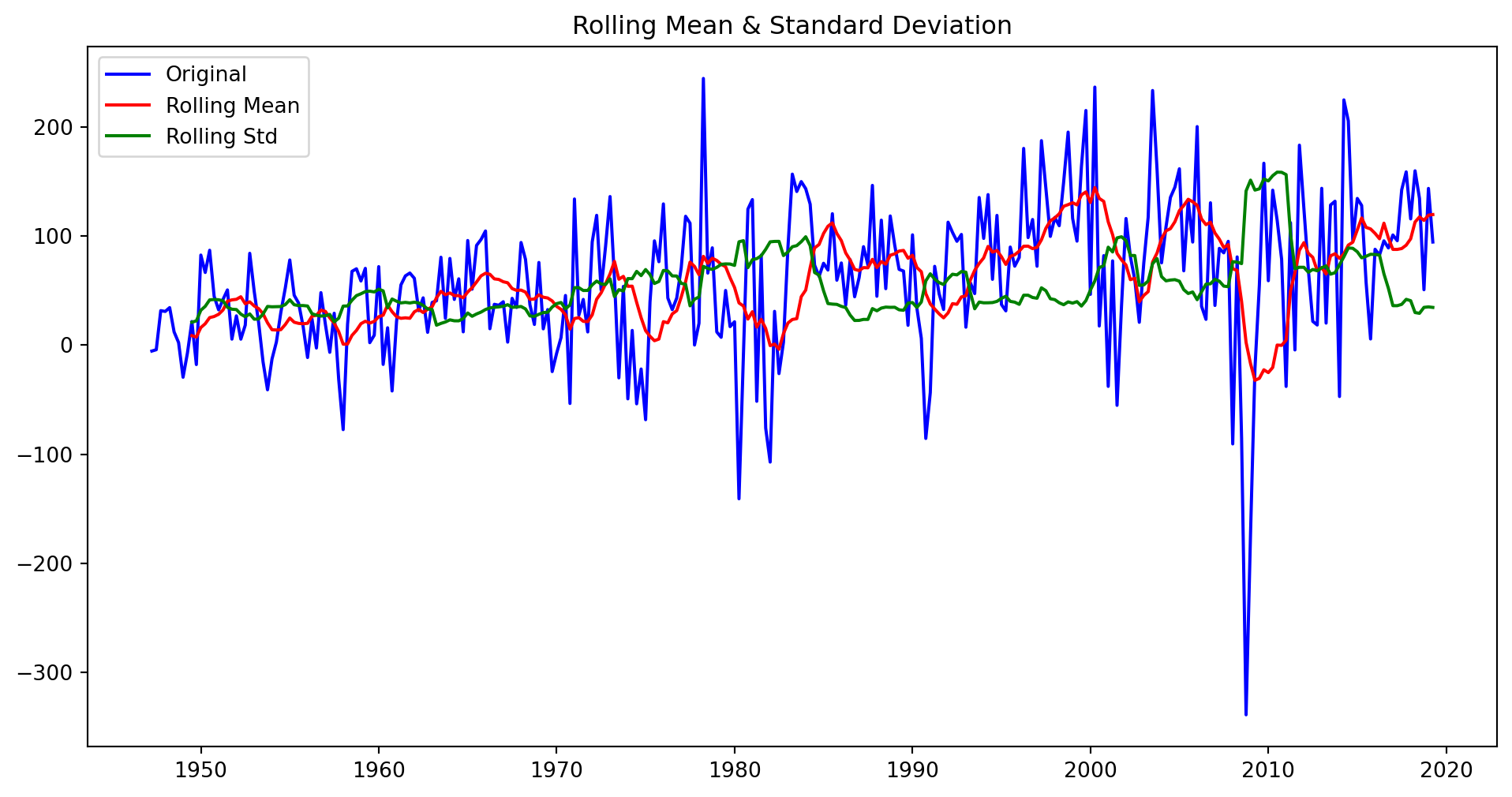
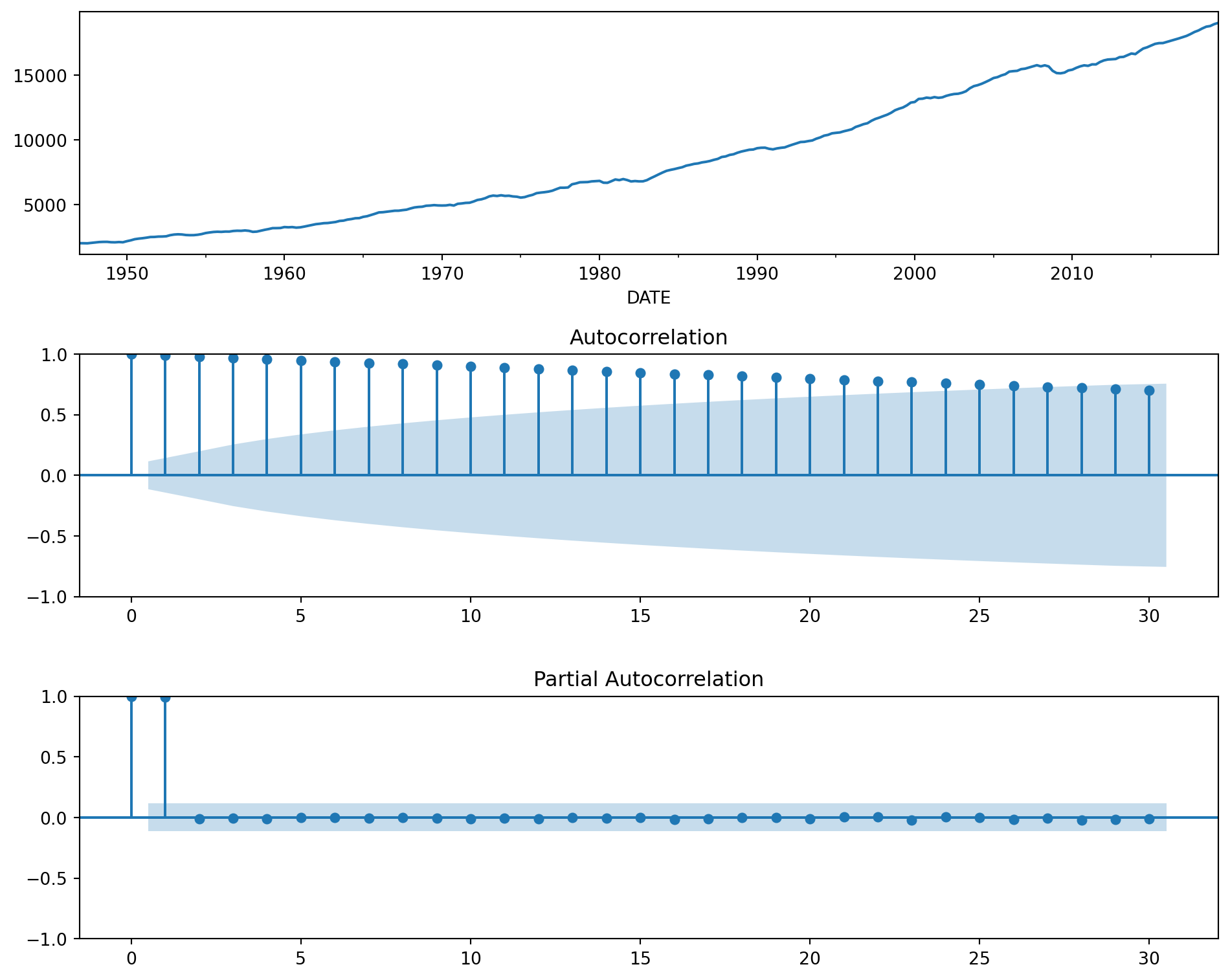
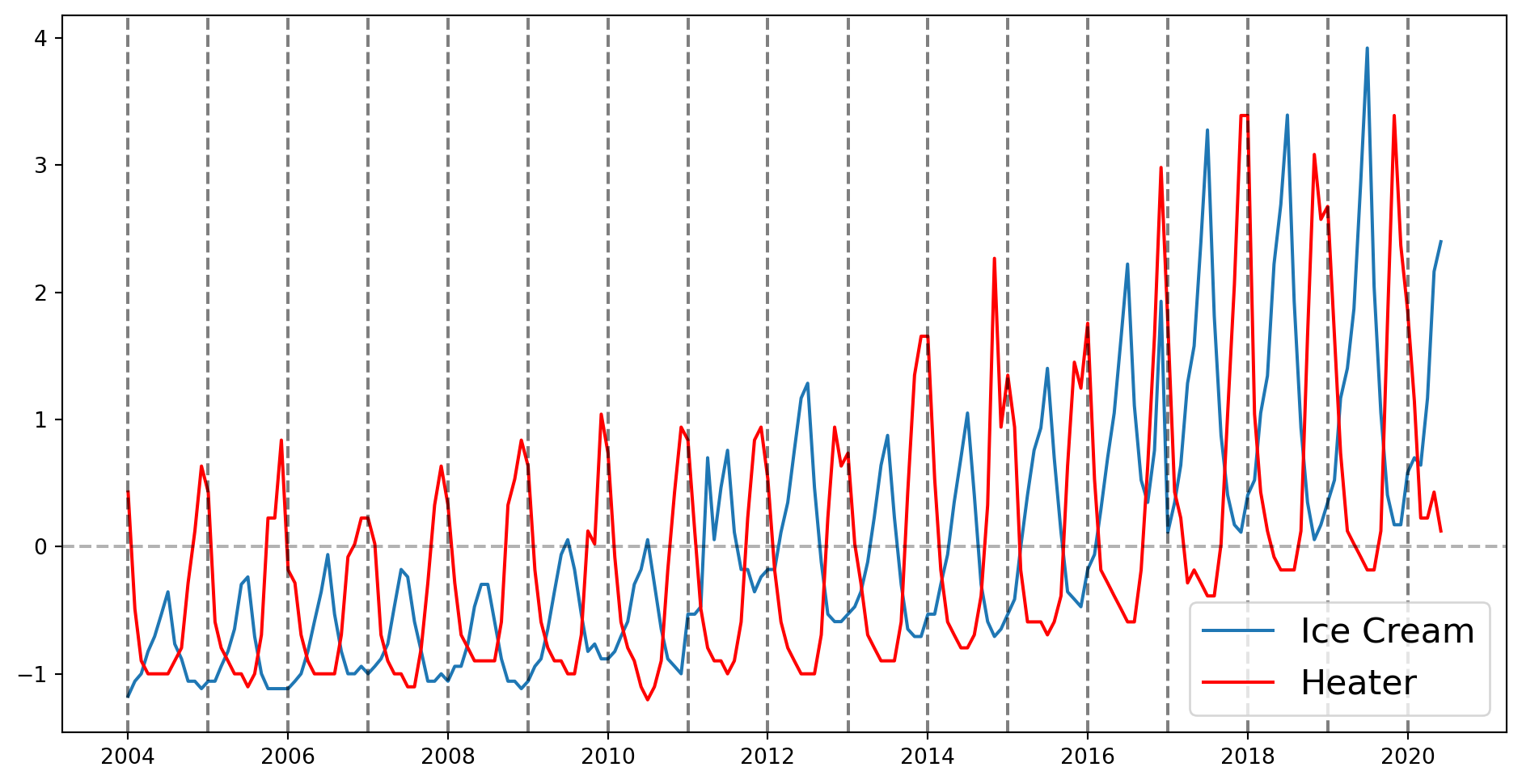
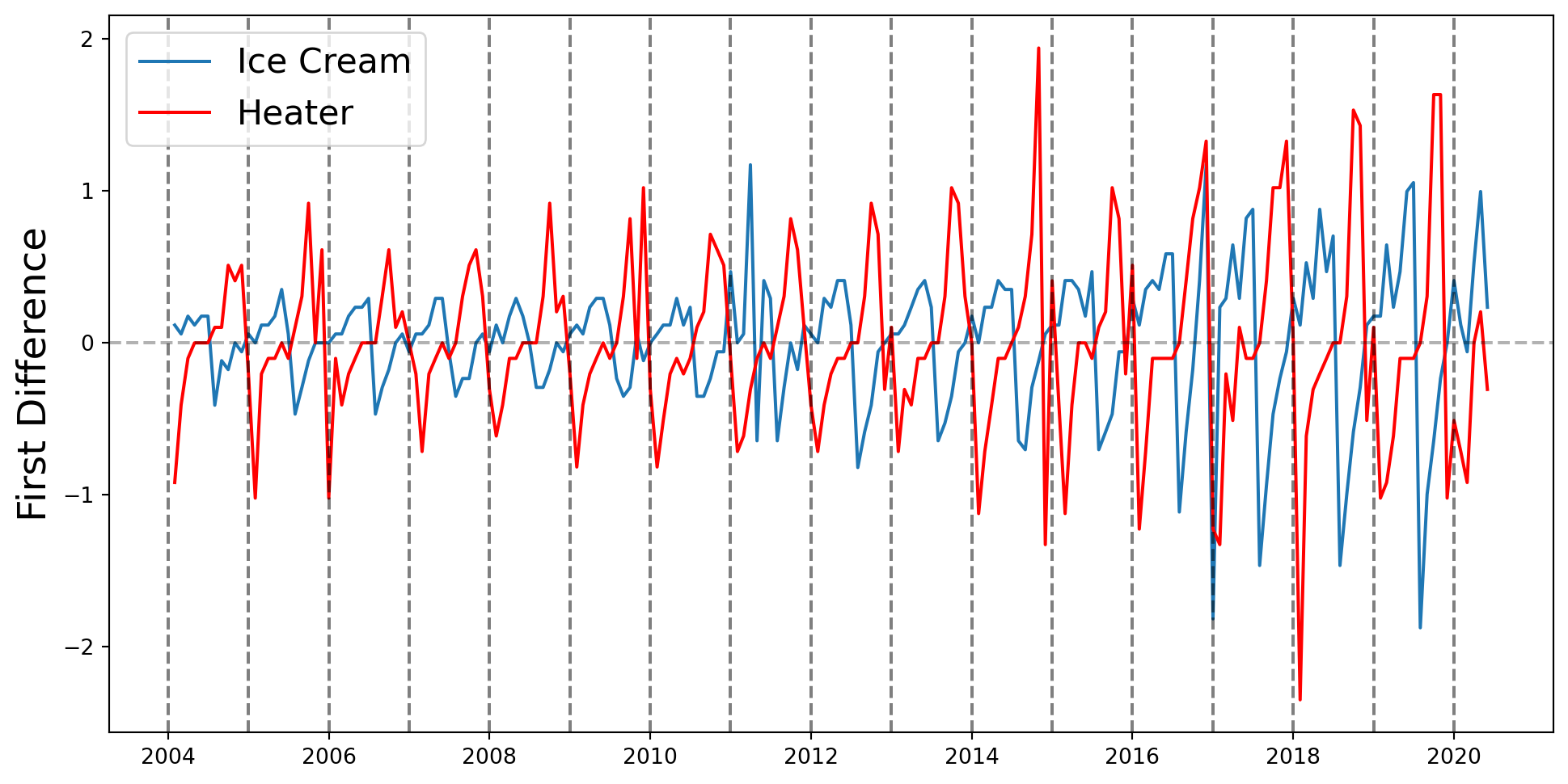
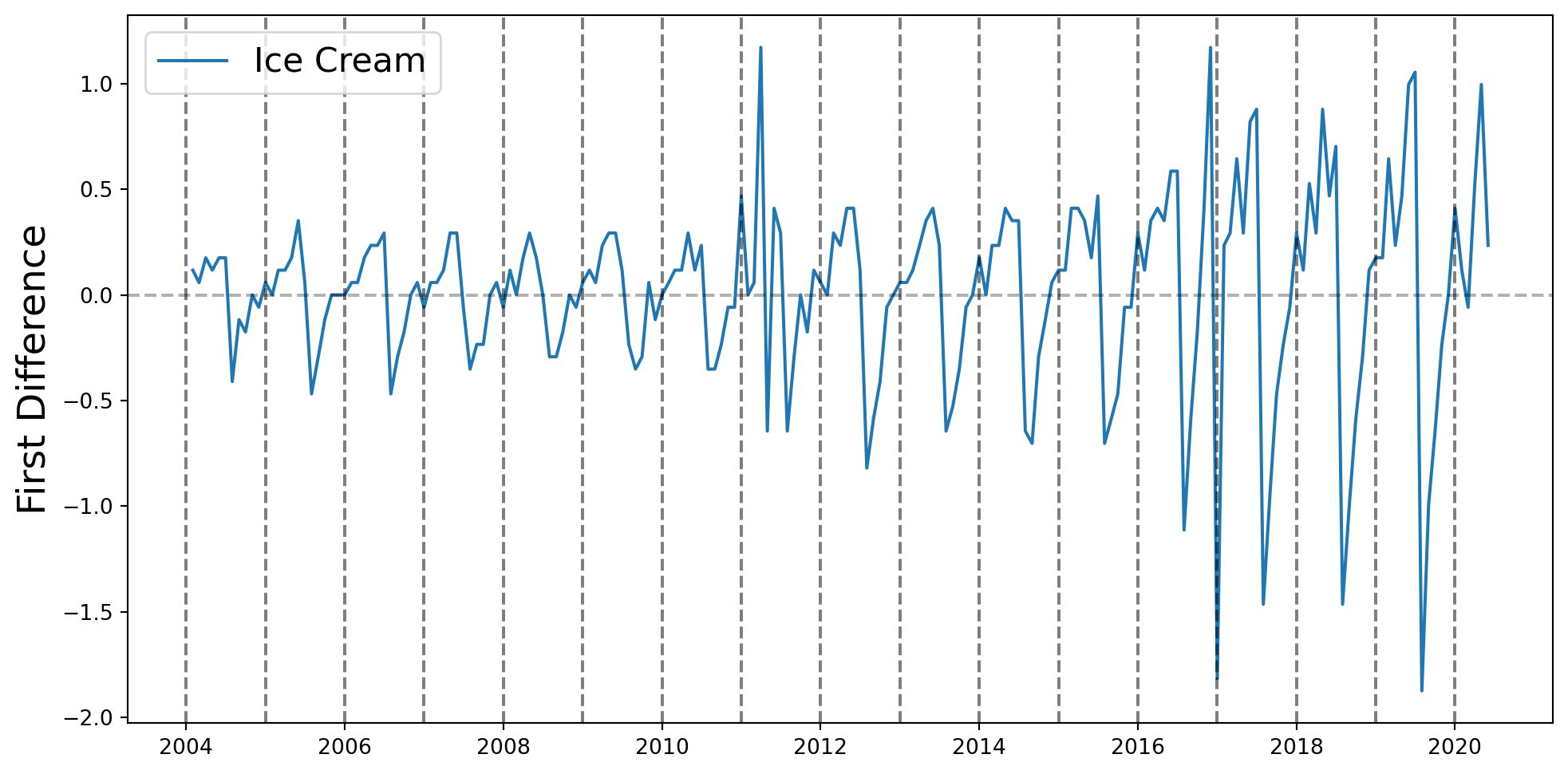
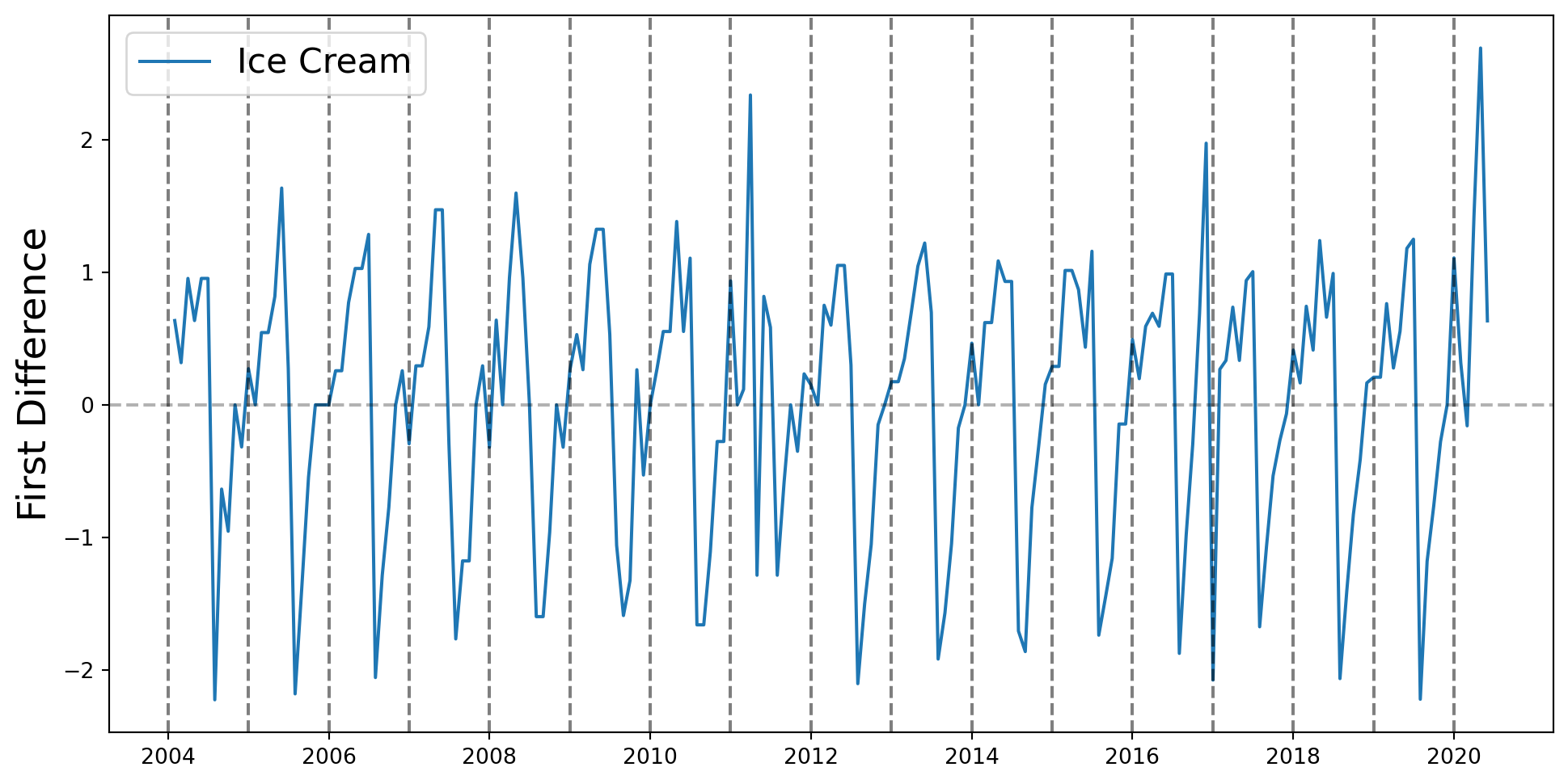
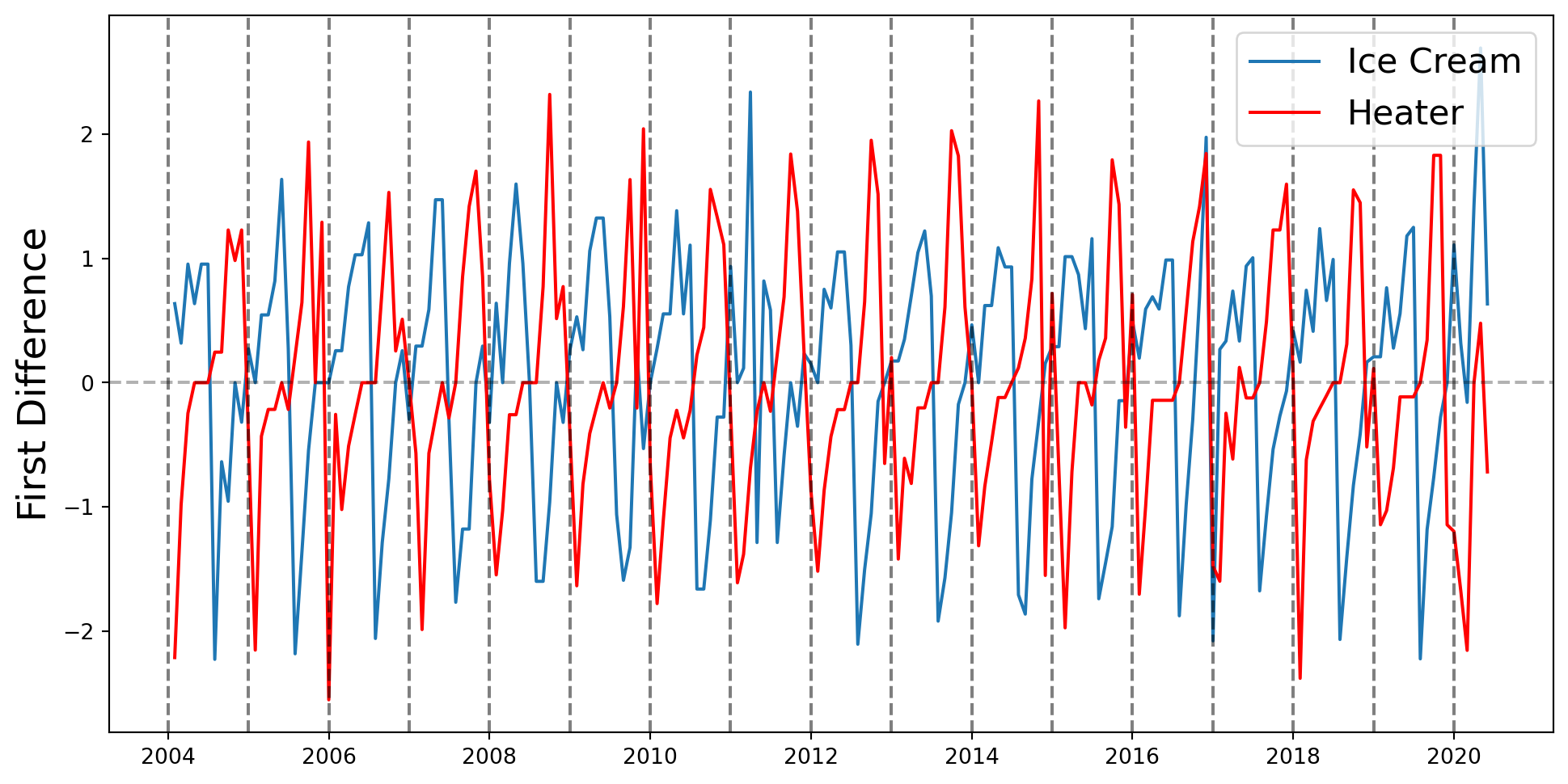
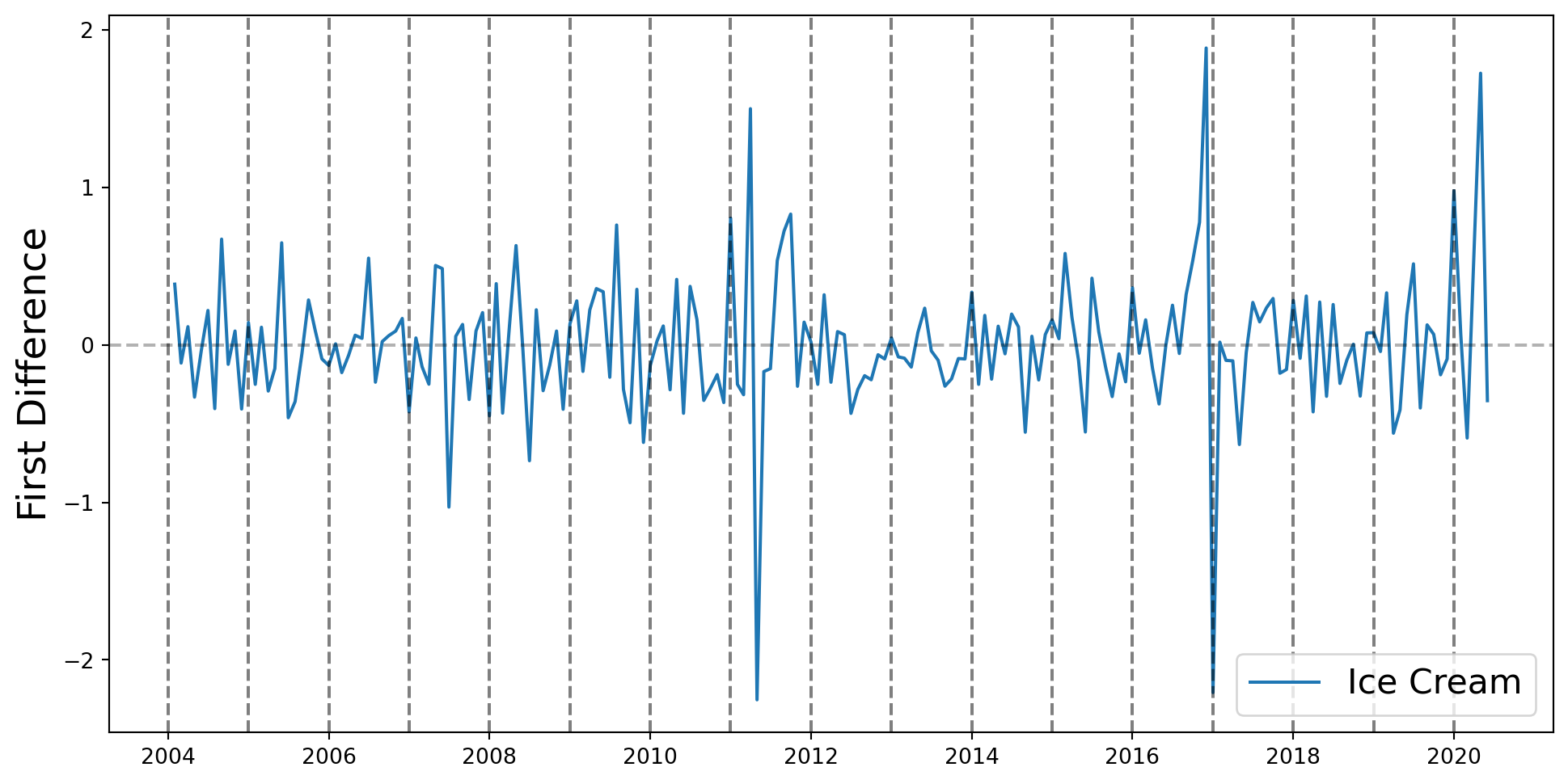
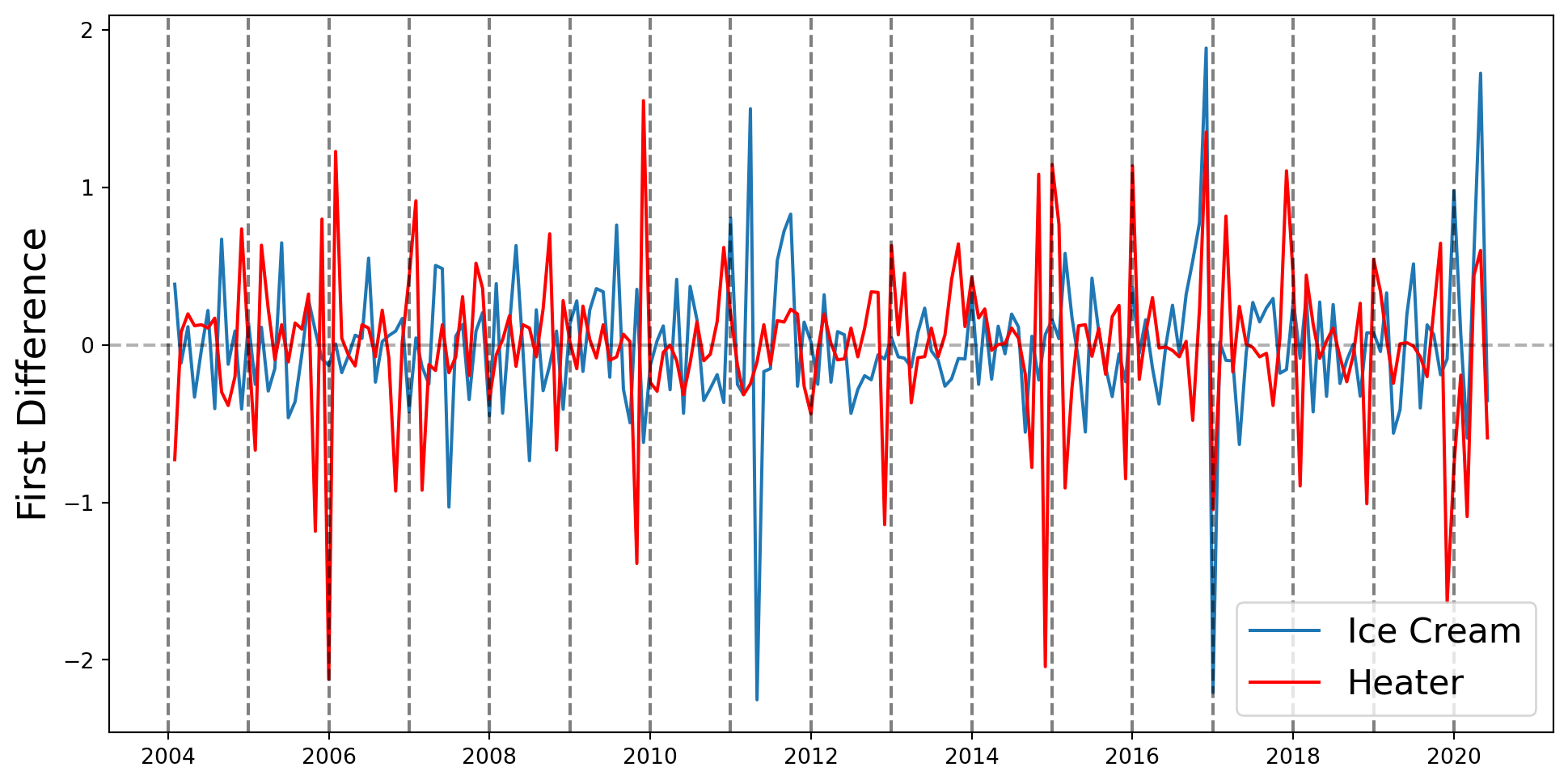
Se incluyen efectos temporales, que se piensan que tienen que ver con tendencias, inercia o estacionalidades
Un modelo con inercia en la inflación (por conceptos): \[ inflación_{t}=\beta_{0}+\beta_{1}desempleo_{t}+\beta_{2} inflación_{t-1} +u_{t}\]
Hay modelos conocidos:
Ejemplo: ARIMA de primer órden \[ \Delta inflacion_t = \phi \cdot \Delta inflacion_{t-1} + \varepsilon_t\]
Supuestos no cumplidos y opciones
Para poder interpretar causalmente los coeficientes en un modelo de regresión lineal multiple en series de tiempo necesitamos que se cumplan los siguientes supuestos de Gauss Markov (adaptados de ST):
Modelo lineal en parámetros: \(y_{t}=\beta_{0}+\beta_{1}x_{1t}+\dots+\beta_{1}x_{kt}+u_{t}\)
Media condicionada nula o exogeneidad (que ahora es estricta): \(E[u_{t}|X_{js}]=0 \quad \forall s\)
No hay correlación serial: \(Cov[u_{t}, u_{s}|X_{js}]=\sigma \quad \forall s\ne t\)
Vemos que hay dos elementos diferentes a corte transversal: (por que no hay Muestreo Aletorio) - cambia la exogeneidad a uno más estricto - y aparece un nuevo supuesto, correlación serial.
Supuestos no cumplidos y opciones
Cada uno de estos supuestos tiene diferentes implicancias:
1-3 es que el estimador de MCO \(\hat{\beta}\) es insesgado.
4-5 que tiene minima varianza de los estimadores lineales (eficiente)
En total, 1-5 -> Los estimadores de MCO son los mejores estimadores lineales insesgados (MELI)
Resumen de correlación serial:
Los datos de series temporales, generalmente están relacionadas con sus valores pasados.
Razones: inercia, reacciones rezagadas, entre otras.
Cuando una variable depende de sus propios valores en el pasado se denomina autocorrelacion
Si los valores de una variable X en el presente están correlacionados con valores pasados de otra variable, Y, se conoce como correlación serial
A veces se usan los términos como sinónimos.
Podemos identificar la correlación serial de tres maneras:
Graficamente en los residuos
Estadísticamente mediante la prueba de WHite o de Breaush y Pagan.
¿Y si la serie es estacionaria?
Cuando la serie es estacionaria, podemos reemplazar el supuesto de exogeneidad extrica de vuelta por el de exogeneidad debil.
Podemos seguir trabajando como de construmbre
Así que un primer paso, es ver si la serie es estacionaria.
¿Y si la serie no es estacionaria?
Cuando tenermos patrones de dependencia intertemporal, estos supuestos ya no se cunplen.
Muy comun en ST:
Efecto rezagado (variable independiente rezagada)
Retroalimentación entre variables
Auto-dependencia, la variable depende de si misma en el pasado.
Objetivos diferentes de los modelos
Los modelos de regresión se pueden usar con dos objetivos principales: predicción y explicación.
En series de tiempo, como no hay muestreo aleatorio, nos enfocaremos en la predicciónn.
Un modelo de regresión puede ser útil para la predicción, aún cuando ninguno de sus coeficientes tenga interpretación causal.
Desde el punto de vista de la predicción, lo que es importante es que el modelo entregue una predicción lo más precisa posible.
La idea base es aprovechar las peculiaridades de las series temporales: la dependencia temporal y tendencias, para identificar patrones en la data que enriquezcan la predicción aun cuando no tengan valor explicativo. Estos elementos los incluiremos DENTRO de la regresión, para que represente de mejor manera el fenómeno a predecir.
Modelos explicativos en series temporales:
Los modelos que se centran en la explicación: Se basen en modelos teoricos estructurales que se corroboran en la data
Se usan otras aproximaciones empíricas como Causalidad de Granger
un concepto estadístico que evalúa si una serie temporal puede predecir otra serie temporal.
Ayuda a determinar si un conjunto de datos precedentes es útil para predecir un conjunto de datos posterior.
Un Concepto relacionado es la cointegración:
La cointegración identifica relaciones estadísticas a largo plazo entre series temporales, lo que puede ser relevante al evaluar la causalidad de Granger.
A pesar de tendencias o patrones a largo plazo, existe una combinación lineal que es estacionaria.
Volveremos a esta clase de modelos, al final de la sesión.
Modelando las series temporales:
Modelando series de Tiempo
Para modelar, entonces este tipo de datos recurriremos a una familia de modelos que se llaman auto-regresivos.
Esto quiere decir, que incluye rezagos como regresores para poder considerar la interdependencia temporal de los datos en el modelamiento.
Empezaremos con el caso más simple:
las Medias Móviles (MA),
luego Auto-regresivos (AR)
Los combinaremos en ARIMA y SARIMA
Mencionaremos algunos otros modelos muy usados, que nacen de esta base.
MEDIAS MOVILES (MA)
Empezamos por definir un modelo de media movil o moving average
Este es un modelo autorregresivo de “memoria corta”.
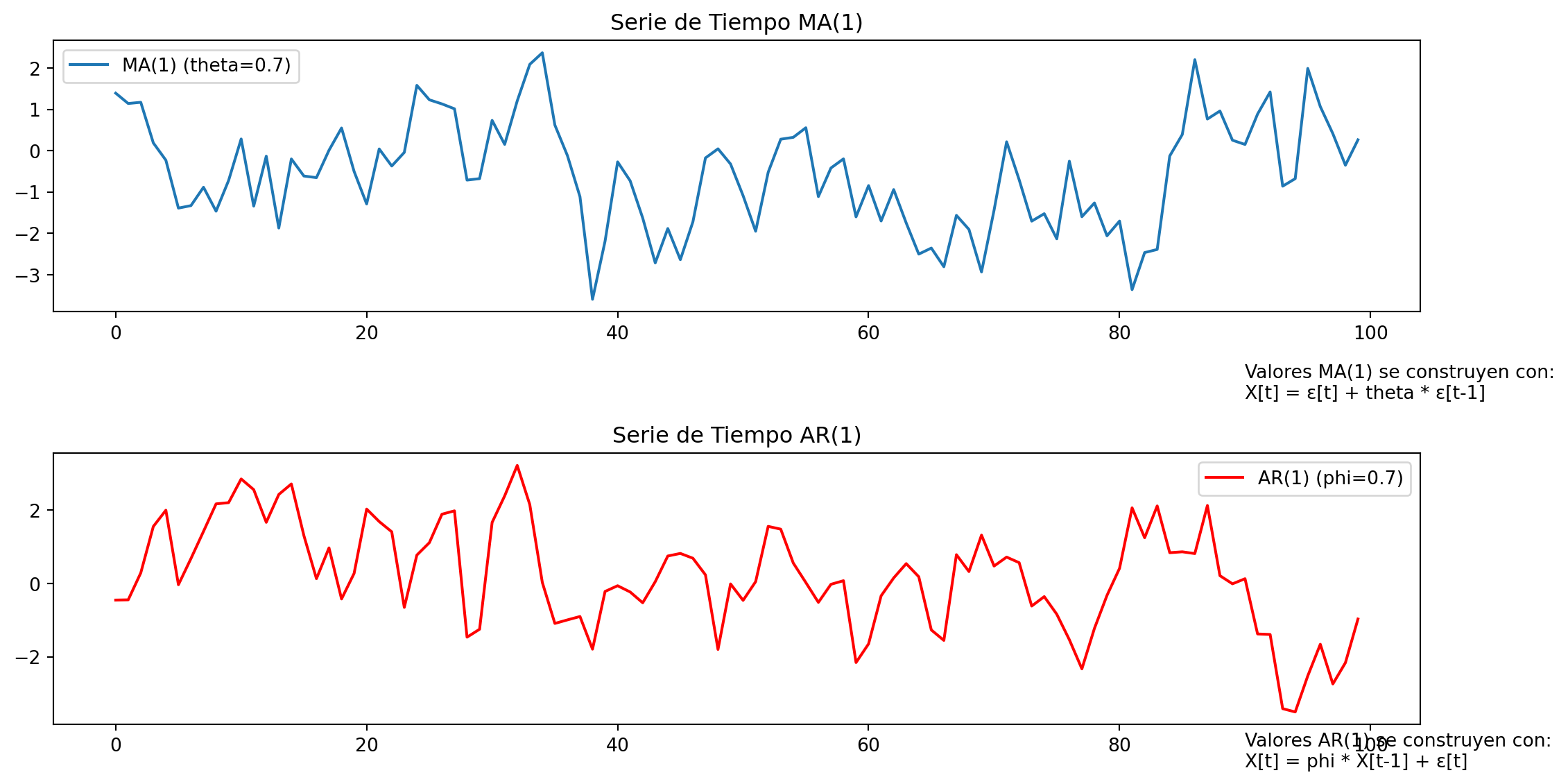
Matemáticamente, un modelo MA de primer orden o MA(1) es:
\[ x_t=\epsilon_t + \theta \epsilon_{t-1} \]
Decimos que es de primer orden, porque tiene 1 rezago estocástico.
Estos modelos lo que hacen es modelar la “memoria” temporal del proceso estocástico.
MA(1) : memoria “corta”, impacto del shock no persiste mucho
AR(1) : memoria “larga”, impacto del shock persiste (en teoría, persiste infinitamente)
import numpy as npimport matplotlib.pyplot as plt# Parámetros del modelo MA(1)theta =0.7sigma =1n =100# Longitud de la serie de tiempo# Simulación de la serie de tiempo MA(1)ma_series = [np.random.normal(scale=sigma)]for _ inrange(1, n): ma_series.append(np.random.normal(scale=sigma) + theta * ma_series[-1])# Parámetros del modelo AR(1)phi =0.7# Simulación de la serie de tiempo AR(1)ar_series = [np.random.normal(scale=sigma)]for _ inrange(1, n): ar_series.append(phi * ar_series[-1] + np.random.normal(scale=sigma))# Crear gráficosplt.figure(figsize=(12, 6))plt.subplot(2, 1, 1)plt.plot(ma_series, label=f'MA(1) (theta={theta})')plt.title('Serie de Tiempo MA(1)')plt.legend()plt.text(90, -6, 'Valores MA(1) se construyen con:\nX[t] = ε[t] + theta * ε[t-1]')plt.subplot(2, 1, 2)plt.plot(ar_series, label=f'AR(1) (phi={phi})', color='red')plt.title('Serie de Tiempo AR(1)')plt.legend()plt.text(90, -5, 'Valores AR(1) se construyen con:\nX[t] = phi * X[t-1] + ε[t]')plt.tight_layout()plt.show()
AR vs AM
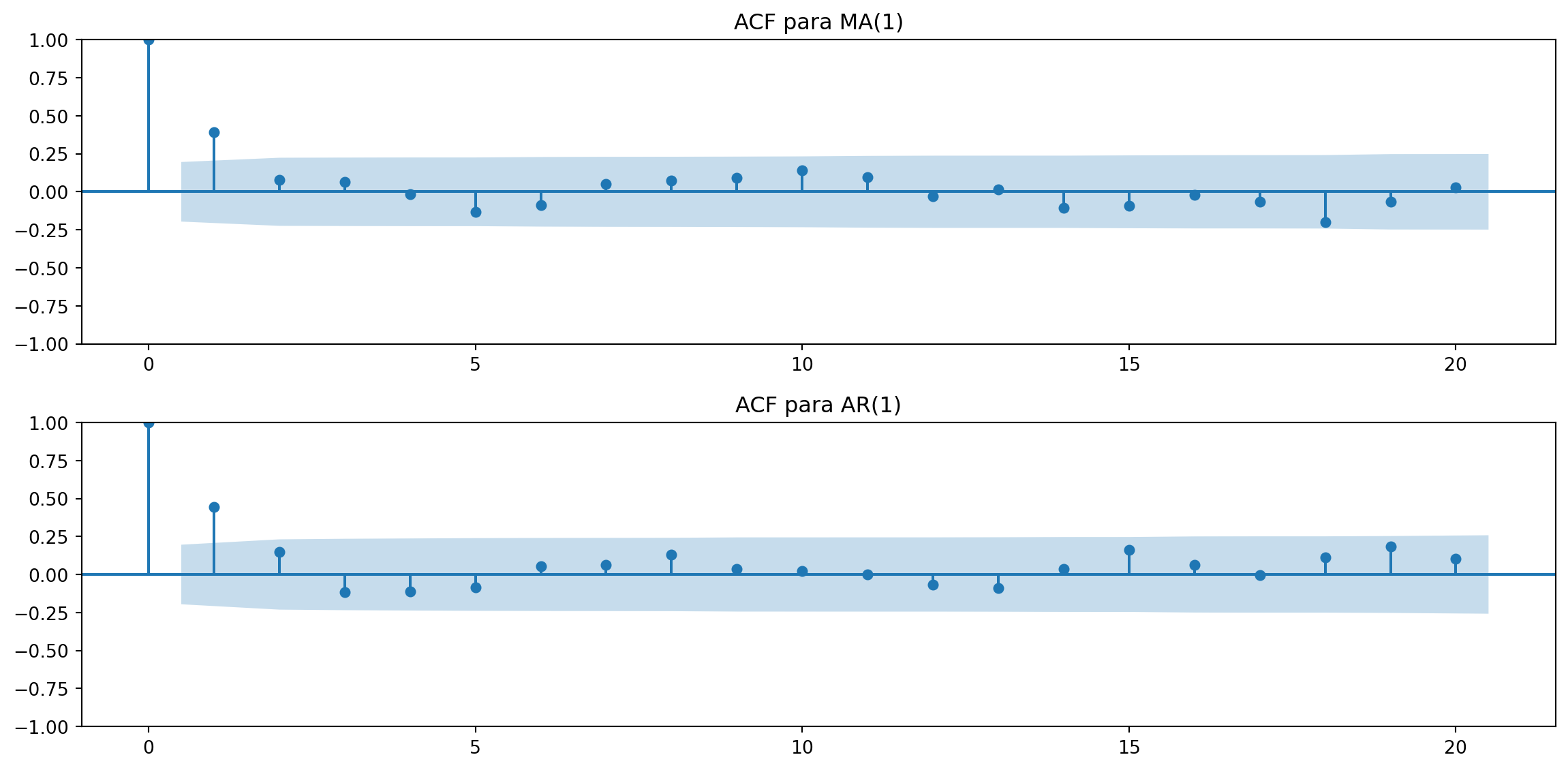
Podemos enr en el grafico de AUTO CORRELACION PARCIAL como se correlacionan los valores de la serie.
import numpy as npimport matplotlib.pyplot as pltfrom statsmodels.graphics.tsaplots import plot_acf# Parámetros del modelo MA(1)theta_ma =0.5sigma_ma =1n =100# Simulación de la serie de tiempo MA(1)ma_series = [np.random.normal(scale=sigma_ma)]for _ inrange(1, n): ma_series.append(np.random.normal(scale=sigma_ma) + theta_ma * ma_series[-1])# Parámetros del modelo AR(1)rho_ar =0.5sigma_ar =1# Simulación de la serie de tiempo AR(1)ar_series = [np.random.normal(scale=sigma_ar)]for _ inrange(1, n): ar_series.append(rho_ar * ar_series[-1] + np.random.normal(scale=sigma_ar))# Graficar la ACF para MA(1)plt.figure(figsize=(12, 6))plt.subplot(2, 1, 1)plot_acf(np.array(ma_series), ax=plt.gca(), title="ACF para MA(1)")# Graficar la ACF para AR(1)plt.subplot(2, 1, 2)plot_acf(np.array(ar_series), ax=plt.gca(), title="ACF para AR(1)")plt.tight_layout()plt.show()
ARIMA y SARIMA
ARIMA que significa Autoregressive Integrated Moving-Average, es un modelamiento de serie de tiempo que combina modelos auto regresivos (AR) y medias moviles (MA), con la opcion de incluir raices unitarias.
Estos modelos tienen 3 parámetros:
p, que son cuantos autorregresores tiene el modelo AR,
q que indica cuantos parametros tiene la media movil y
Finalmente, la combinación de ambos modelamientos es \[ x_t=\epsilon_t + \phi x_{t-1} + \theta \epsilon_{t-1} \]
Si el modelo de los datos es estacionario, entonces no es necesario diferenciar y se usa d=0. Si no lo es, requerimos diferenciar con d>1.
Adicionalmente existe la clase SARIMA, o Seasonal-ARIMA que le agrega coeficientes que controlan por la estacionalidad.
ARIMA
Definimos unas funciones auxiliares, para diferenciar e integrar:
def differentiate(values, d=1):# First value is required so that we can recover the original values with np.cumsum x = np.concatenate([[values[0]], values[1:]-values[:-1]])if d ==1:return xelse: return differentiate(x, d -1)
def integrate(values, d=1): x = np.cumsum(values)if d ==1:return xelse:return integrate(x, d-1)
class ARIMA(LinearRegression):def__init__(self, q, d, p):""" An ARIMA model. :param q: (int) Order of the MA model. :param p: (int) Order of the AR model. :param d: (int) Number of times the data needs to be differenced. """super().__init__(True)self.p = pself.d = dself.q = qself.ar =Noneself.resid =Nonedef prepare_features(self, x):ifself.d >0: x = differentiate(x, self.d) ar_features =None ma_features =None# Determine the features and the epsilon terms for the MA processifself.q >0:ifself.ar isNone:self.ar = ARIMA(0, 0, self.p)self.ar.fit_predict(x) eps =self.ar.resid eps[0] =0# prepend with zeros as there are no residuals_t-k in the first X_t ma_features = rolling(np.r_[np.zeros(self.q), eps], self.q)# Determine the features for the AR processifself.p >0:# prepend with zeros as there are no X_t-k in the first X_t ar_features = rolling(np.r_[np.zeros(self.p), x], self.p)if ar_features isnotNoneand ma_features isnotNone: n =min(len(ar_features), len(ma_features)) ar_features = ar_features[:n] ma_features = ma_features[:n] features = np.hstack((ar_features, ma_features))elif ma_features isnotNone: n =len(ma_features) features = ma_features[:n]else: n =len(ar_features) features = ar_features[:n]return features, x[:n]def fit(self, x): features, x =self.prepare_features(x)super().fit(features, x)return featuresdef fit_predict(self, x): """ Fit and transform input :param x: (array) with time series. """ features =self.fit(x)returnself.predict(x, prepared=(features))def predict(self, x, **kwargs):""" :param x: (array) :kwargs: prepared: (tpl) containing the features, eps and x """ features = kwargs.get('prepared', None)if features isNone: features, x =self.prepare_features(x) y =super().predict(features)self.resid = x - yreturnself.return_output(y)def return_output(self, x):ifself.d >0: x = integrate(x, self.d) return xdef forecast(self, x, n):""" Forecast the time series. :param x: (array) Current time steps. :param n: (int) Number of time steps in the future. """ features, x =self.prepare_features(x) y =super().predict(features)# Append n time steps as zeros. Because the epsilon terms are unknown y = np.r_[y, np.zeros(n)]for i inrange(n): feat = np.r_[y[-(self.p + n) + i: -n + i], np.zeros(self.q)] y[x.shape[0] + i] =super().predict(feat[None, :])returnself.return_output(y)
ARIMA
Tambien se puede importar directamente desde statsmodels donde debemos proveer p, d y q.
from statsmodels.tsa.arima.model import ARIMAimport statsmodels.api as sm
ARIMA
Estimemos el modelo con
p=1 (coeficientes AR),
d=1 (orden de diferenciacion),
q=1 (coeficientes MA).
Notar que d realiza la diferenciación y le saca la tendencia a la serie, segun los resultados del ADF.
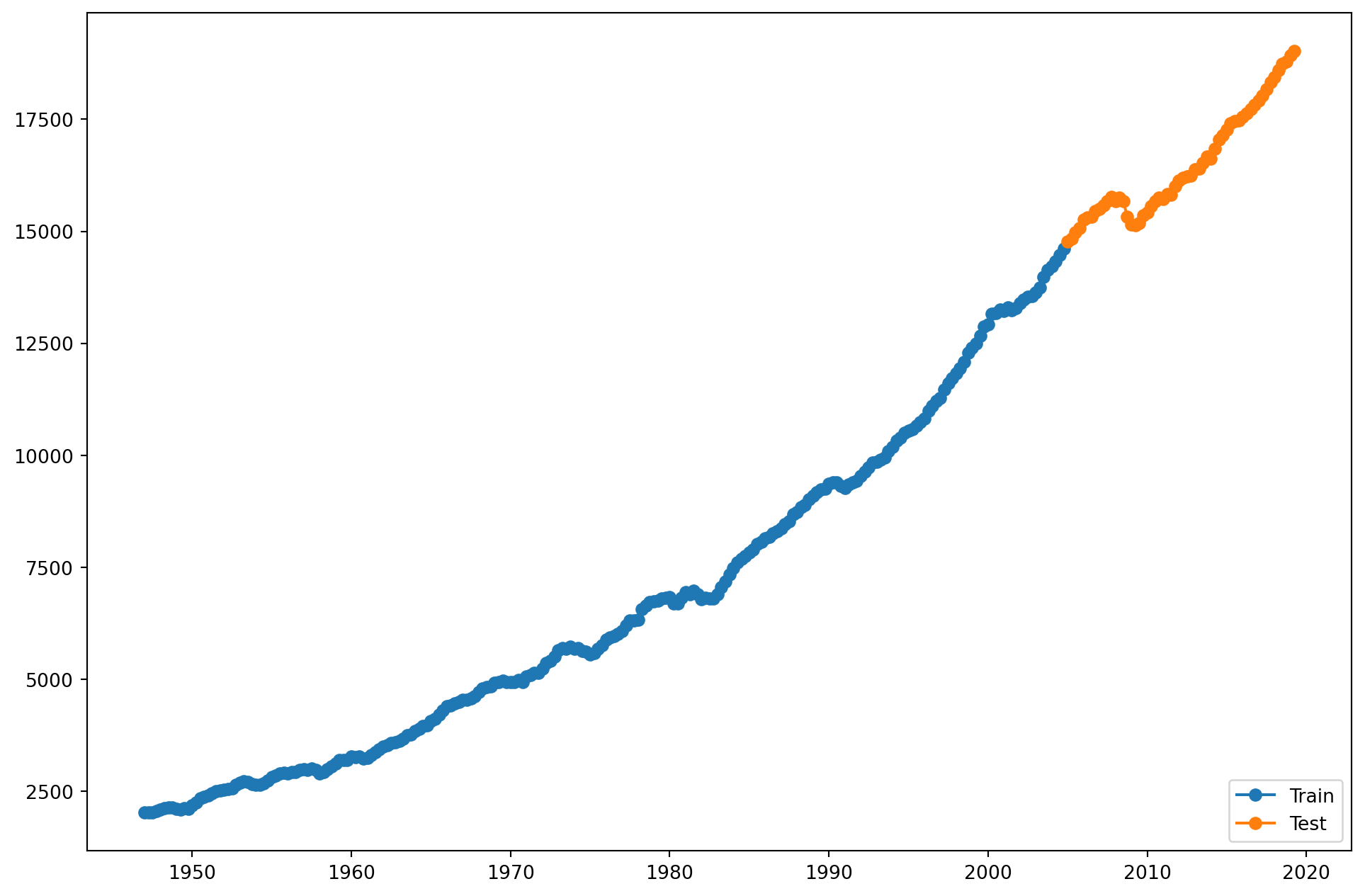
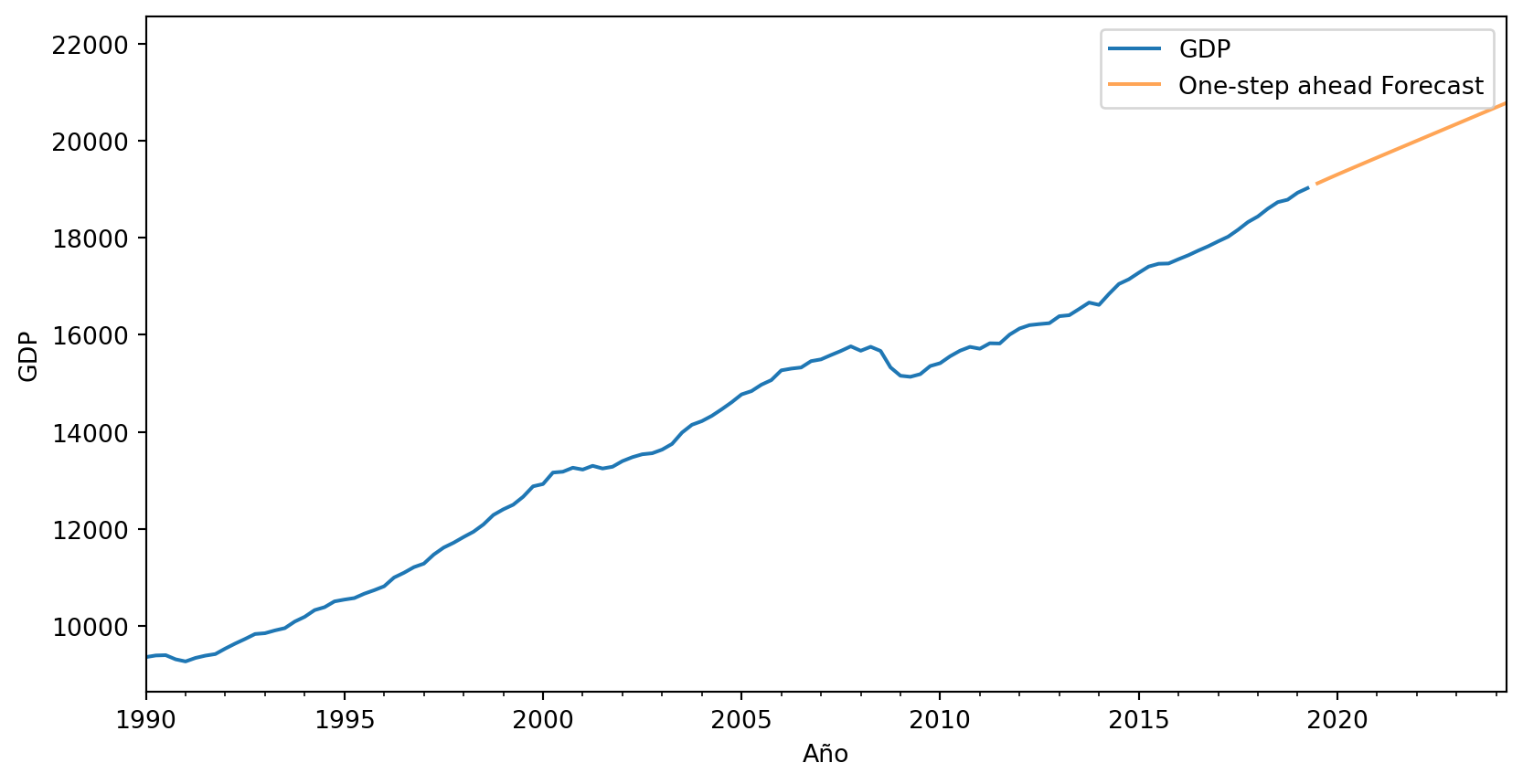
Pasemos a un ejemplo real, volvamos a la serie de GDP que trabajamos al principio:
#Importamos desde la carpetaGDP = pd.read_csv('data_sesion5/GDP.csv', parse_dates=['DATE'])GDP.set_index('DATE', inplace=True)
ARIMA
Ajustemos un modelo ARIMA de 1er orden, en la primera diferencia.
Si nos fijamos, ahora la predicción es mucho mejor. - - Podemos seguir refinando la elección de tiempo, especialmente al considerar la posibilidad de quiebres estructurales.
Predicciones fuera de muestra
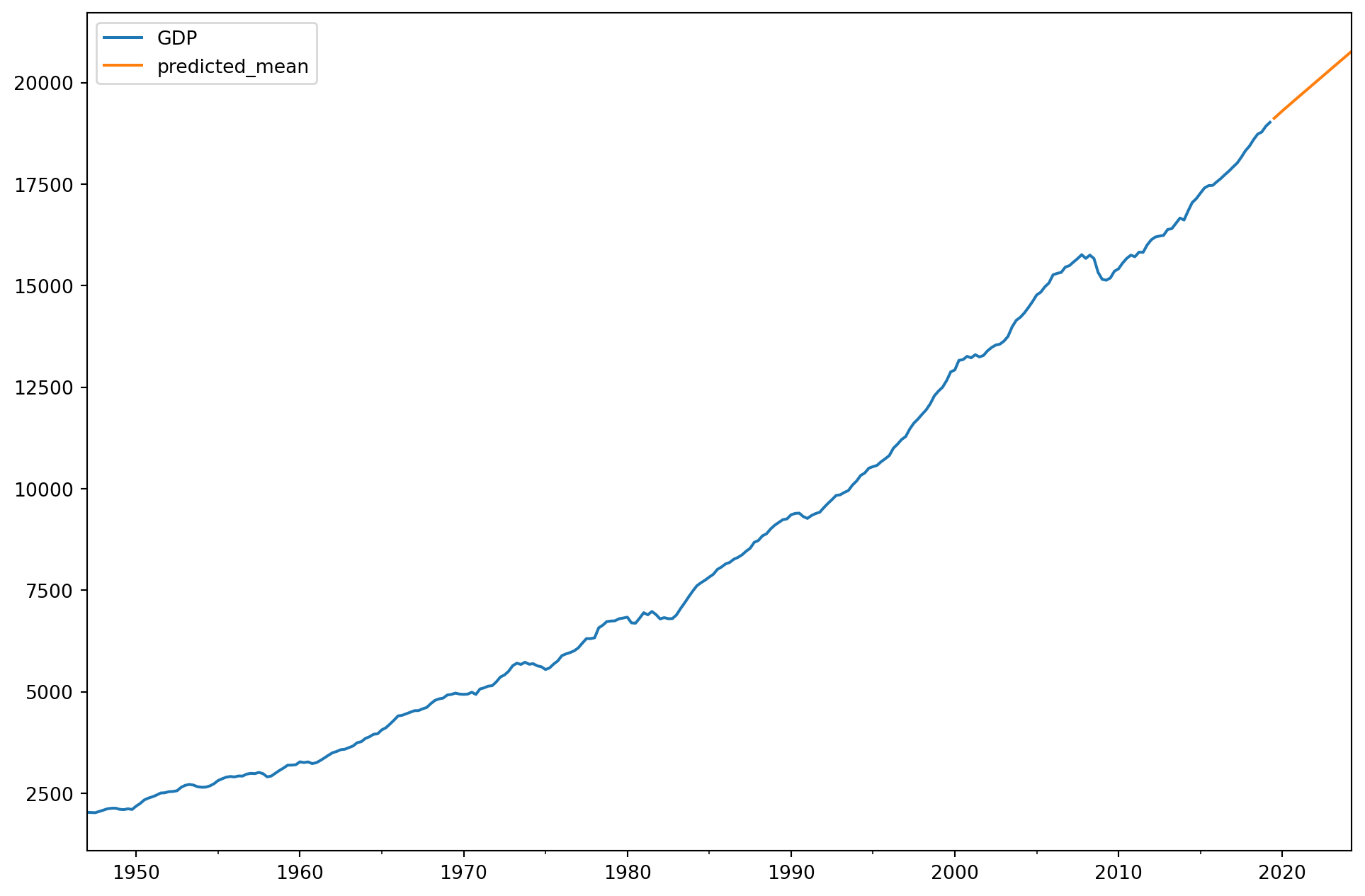
Los modelos ARIMA son muy buenos creando predicciones fuera de muestra en un paso, es decir, el siguiente periodo después de los datos.
model = ARIMA(GDP, order=(2,2,1))results = model.fit()print(results.summary())
Finalmente, vamos a agergarle estos a un nuevo dataframe que incluya la predicción.
from pandas.tseries.offsets import DateOffsetfuture_dates=[GDP.index[-1]+ DateOffset(years=x)for x inrange(-2,10)]future_datest_df=pd.DataFrame(index=future_dates[1:],columns=GDP.columns)future_datest_df
Es un modelo estadístico que se utiliza para modelar y predecir múltiples series de tiempo en conjunto. Es una extensión de los modelos autorregresivos (AR) que se aplican a múltiples variables simultáneamente.
Parámetros del modelo VAR: - p: Representa la cantidad de retardos (lags) utilizados en el modelo autorregresivo. Cada serie de tiempo se regresa en el tiempo hasta p períodos anteriores. - q: Indica la cantidad de términos de media móvil utilizados en el modelo. La media móvil considera las observaciones anteriores de los errores.
Donde (x_t) es una serie de tiempo en el tiempo (t), (_t) es el error en el tiempo (t), (_i) son los coeficientes autorregresivos y (_i) son los coeficientes de media móvil.
El modelo VAR considera múltiples series de tiempo simultáneamente.
Modelos VAR (Vector AutoRegression)
Estacionariedad y diferenciación en VAR: - Al igual que en ARIMA, la estacionariedad es un concepto importante en VAR. - Si las series de tiempo son estacionarias, no es necesario realizar diferenciación ((d=0)). - Sin embargo, si las series no son estacionarias, se requiere diferenciación ((d>0)) para convertirlas en series estacionarias antes de aplicar el modelo VAR.
Modelos VAR (Vector AutoRegression)
Ejemplo:
Supongamos que estamos interesados en modelar el comportamiento de dos series de tiempo:
el precio de una acción (S) y el volumen de transacciones (V).
Podríamos utilizar un modelo VAR(2) que representa la relación de cada serie con sus dos valores anteriores:
Para el precio de la acción (S):
Revsisaremos un ejemplo aplicado al final de la clase.
Granger Causality:
Intuicion: una ts puede ayudar a predecir otra ts
No es causalidad en sí, es una versión “fruna”, que si se cumple es consistente con una dirección causal, lo que puede ser bastante útil.
Tres pasos: 1. Mejor modelo AR para la serie 1 2. Se añaden términos de la serie 2 y sus lags y se prueban haciendo test-t para ver cada lag es por si mismo es significativo, o sea, útil para predecir la serie 1. Al final, vamos a tener algunos lags de la serie 2 en el modelo, se hace un F-test para ver si todos juntos mejoran el modelo. 3. Finalmente se concluye que si algún lag de la serie 2 pasa las pruebas, se dice que la serie 2 “Granger causes” la serie 1. Esto significa que encontramos que si conocemos información sobre los rezagos de la serie 2, vamos a poder predecir significativamente mejor la serie 1.
from statsmodels.tsa.stattools import grangercausalitytestsimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt
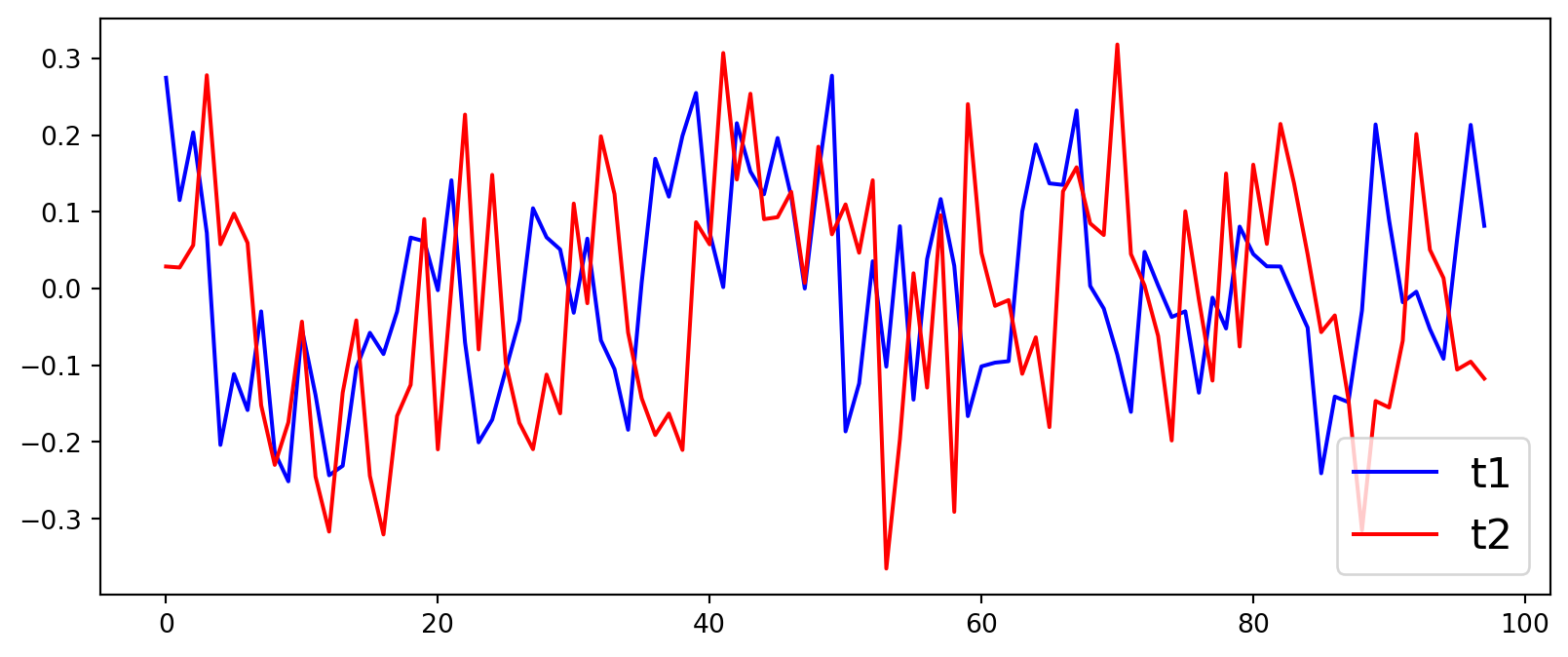
#Construyamos la serie de tiempo, solo un AR(1) simplet1 = [0.1*np.random.normal()]for _ inrange(100): t1.append(0.5*t1[-1] +0.1*np.random.normal())
# Construyamos la serie 2 que es granger caused por t1t2 = [item +0.1*np.random.normal() for item in t1]
Granger Causality
number of lags (no zero) 1
ssr based F test: F=6.5813 , p=0.0119 , df_denom=94, df_num=1
ssr based chi2 test: chi2=6.7913 , p=0.0092 , df=1
likelihood ratio test: chi2=6.5641 , p=0.0104 , df=1
parameter F test: F=6.5813 , p=0.0119 , df_denom=94, df_num=1
Granger Causality
number of lags (no zero) 2
ssr based F test: F=7.1223 , p=0.0013 , df_denom=91, df_num=2
ssr based chi2 test: chi2=15.0273 , p=0.0005 , df=2
likelihood ratio test: chi2=13.9611 , p=0.0009 , df=2
parameter F test: F=7.1223 , p=0.0013 , df_denom=91, df_num=2
Granger Causality
number of lags (no zero) 3
ssr based F test: F=48.7412 , p=0.0000 , df_denom=88, df_num=3
ssr based chi2 test: chi2=157.8549, p=0.0000 , df=3
likelihood ratio test: chi2=92.9992 , p=0.0000 , df=3
parameter F test: F=48.7412 , p=0.0000 , df_denom=88, df_num=3
No hay evidencia de Granger causality para lags 1 y 2, pero si para lag=3!!!
Resumen general Series de tiempo
Hemos visto varios elementos de estacionareidad y autocorrelación, reunamoslo en un análisis compacto.
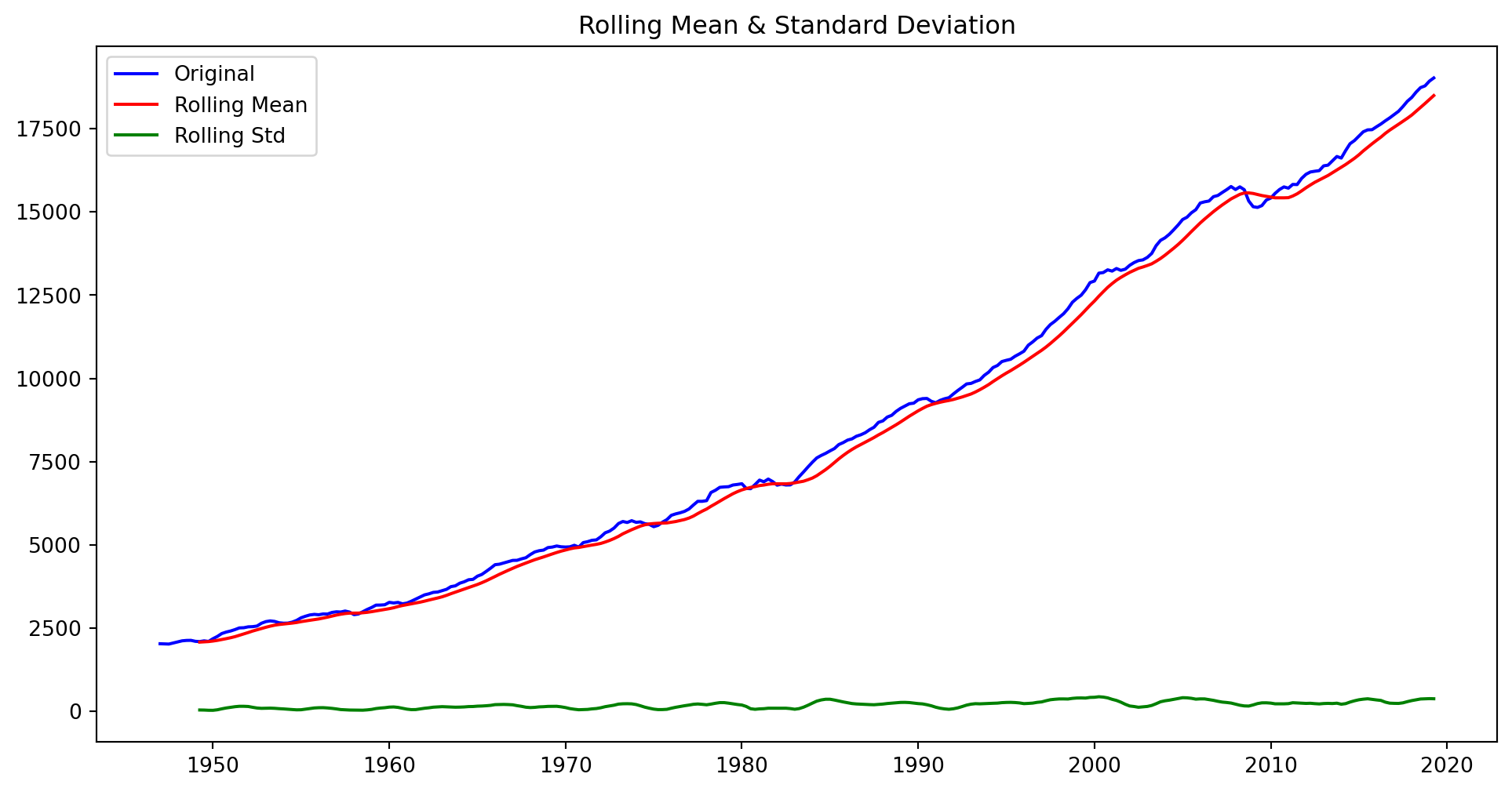
Chequeamos la estacionareidad usando media y varianza movil y el test de Dickey-Fuller aumentado.
Para esto creamos una función, que depende de una ventana para los análisis (w) y con esta, revisamos la serie de tiempo (ts)
from statsmodels import tsafrom statsmodels.tsa.stattools import adfullerdef stationarity_check(ts, w):# Calculate rolling statistics roll_mean = ts.rolling(window=w, center=False).mean() roll_std = ts.rolling(window=w, center=False).std()# Perform the Dickey Fuller test dftest = adfuller(ts) # Plot rolling statistics: fig = plt.figure(figsize=(12,6)) orig = plt.plot(ts, color='blue',label='Original') mean = plt.plot(roll_mean, color='red', label='Rolling Mean') std = plt.plot(roll_std, color='green', label ='Rolling Std') plt.legend(loc='best') plt.title('Rolling Mean & Standard Deviation') plt.show(block=False)# Print Dickey-Fuller test resultsprint('\nResults of Dickey-Fuller Test: \n') dfoutput = pd.Series(dftest[0:4], index=['Test Statistic', 'p-value', '#Lags Used', 'Number of Observations Used'])for key, value in dftest[4].items(): dfoutput['Critical Value (%s)'%key] = valueprint(dfoutput)
#ejemplo con GPD y w=10stationarity_check(GDP, w=10)
Results of Dickey-Fuller Test:
Test Statistic 2.962229
p-value 1.000000
#Lags Used 12.000000
Number of Observations Used 277.000000
Critical Value (1%) -3.454180
Critical Value (5%) -2.872031
Critical Value (10%) -2.572360
dtype: float64
Claramente la serie NO es estacionaria. Ahora necesitamos sacarle las tendencias para proceder
Aplicamos una descomposición con seasonal_dceomposition() desde statsmodels.tsa.seasonal para visualizar las tendencias, la estacionalidad y residuos.
Realizamos una diferenciación para eliminar las tendencias.
GDP['1 diff']= GDP['GDP']-GDP['GDP'].shift(1)GDP
GDP
1 diff
DATE
1947-01-01
2033.061
NaN
1947-04-01
2027.639
-5.422
1947-07-01
2023.452
-4.187
1947-10-01
2055.103
31.651
1948-01-01
2086.017
30.914
...
...
...
2018-04-01
18598.135
159.881
2018-07-01
18732.720
134.585
2018-10-01
18783.548
50.828
2019-01-01
18927.281
143.733
2019-04-01
19021.860
94.579
290 rows × 2 columns
A=pd.DataFrame(GDP['1 diff'])A=A.dropna() # ya que al diferenciar se pierden observaciones
Chequeamos si la serie diferenciada elimina la tendencia. Sino, volvemos a diferenciar.
stationarity_check(A, 10)
Results of Dickey-Fuller Test:
Test Statistic -4.109942
p-value 0.000933
#Lags Used 11.000000
Number of Observations Used 277.000000
Critical Value (1%) -3.454180
Critical Value (5%) -2.872031
Critical Value (10%) -2.572360
dtype: float64
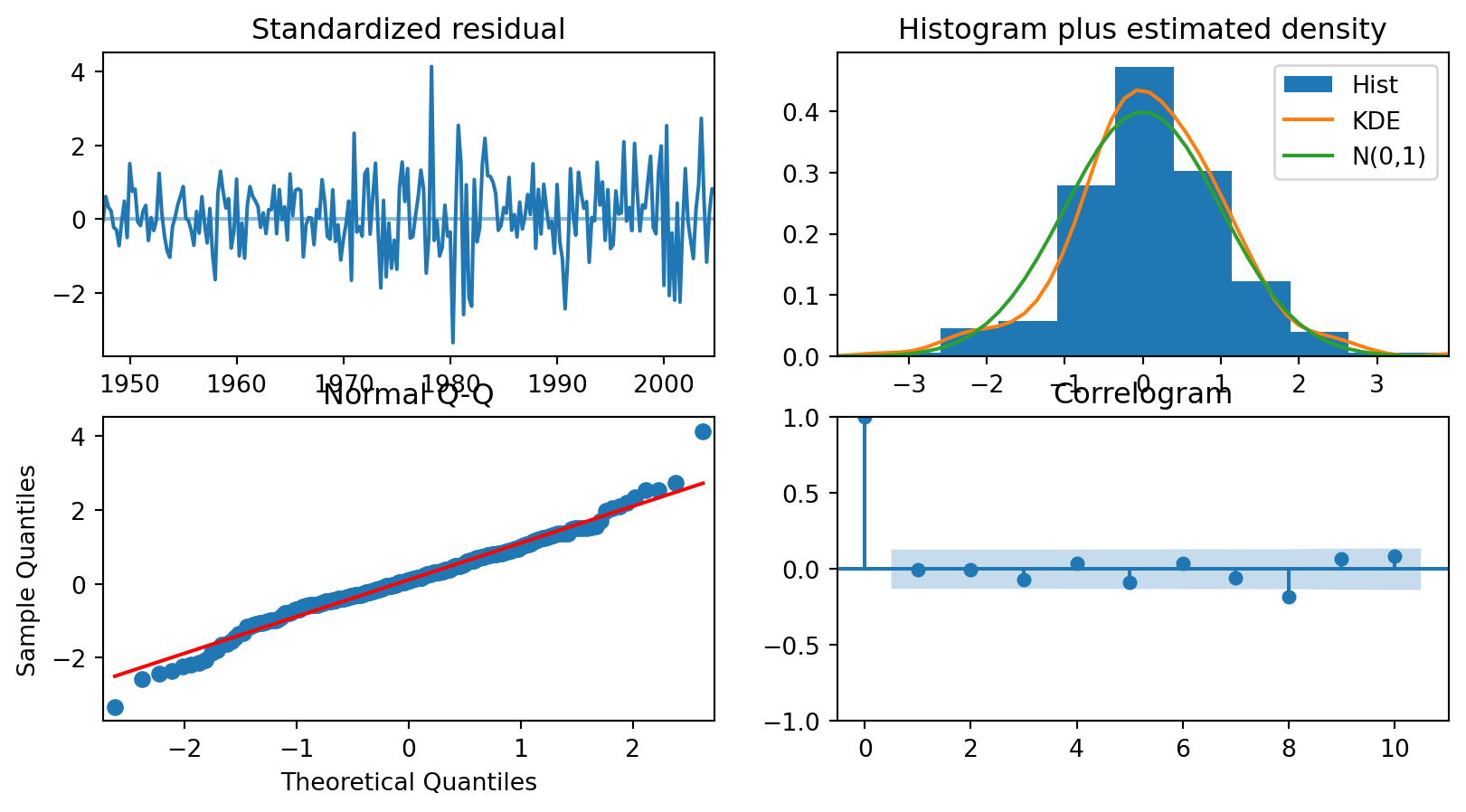
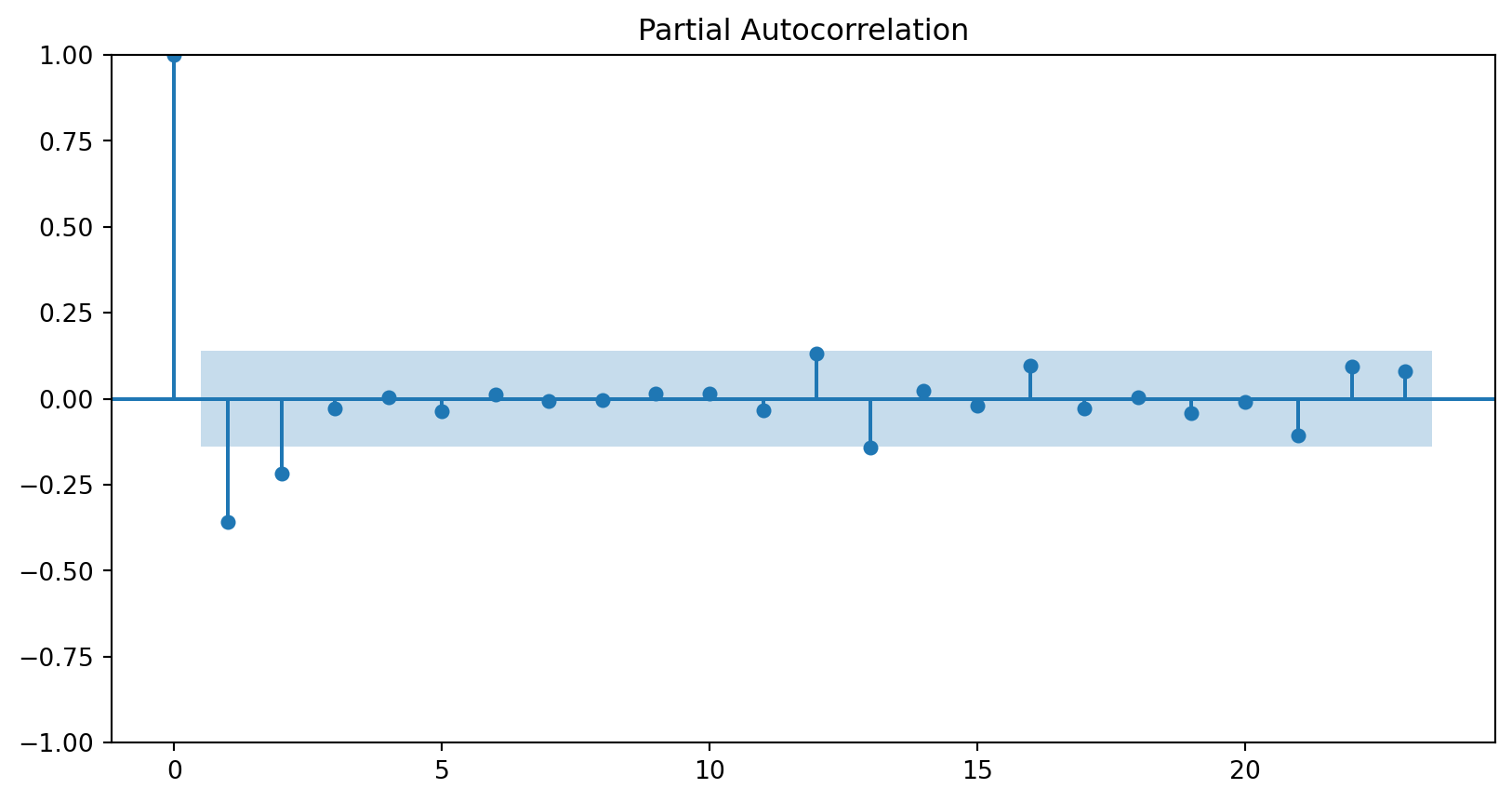
Graficamos la autocorrelacion total y parcial, para proveer informacion sobre posibles (p,d,q) para modelar.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf