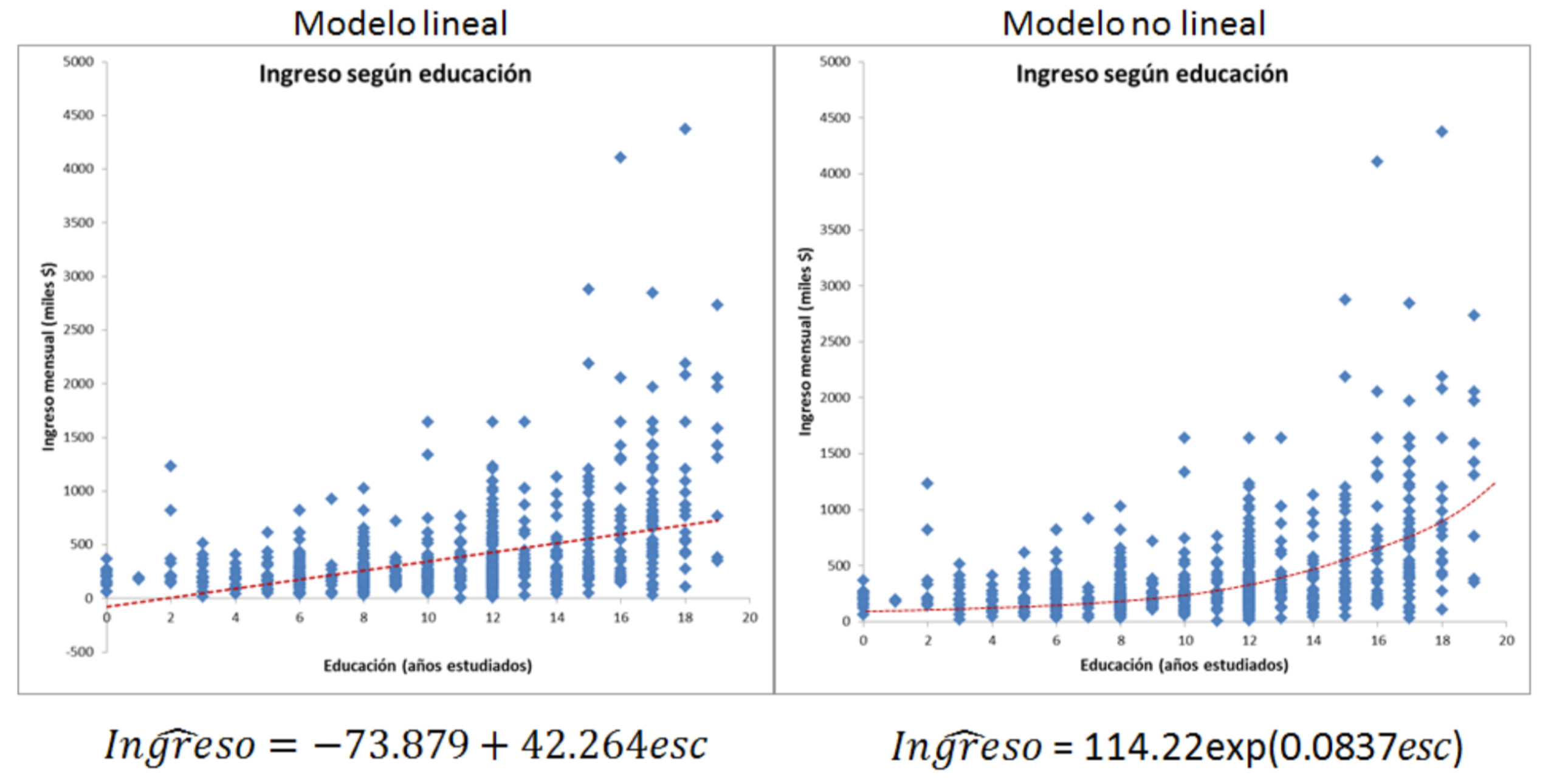
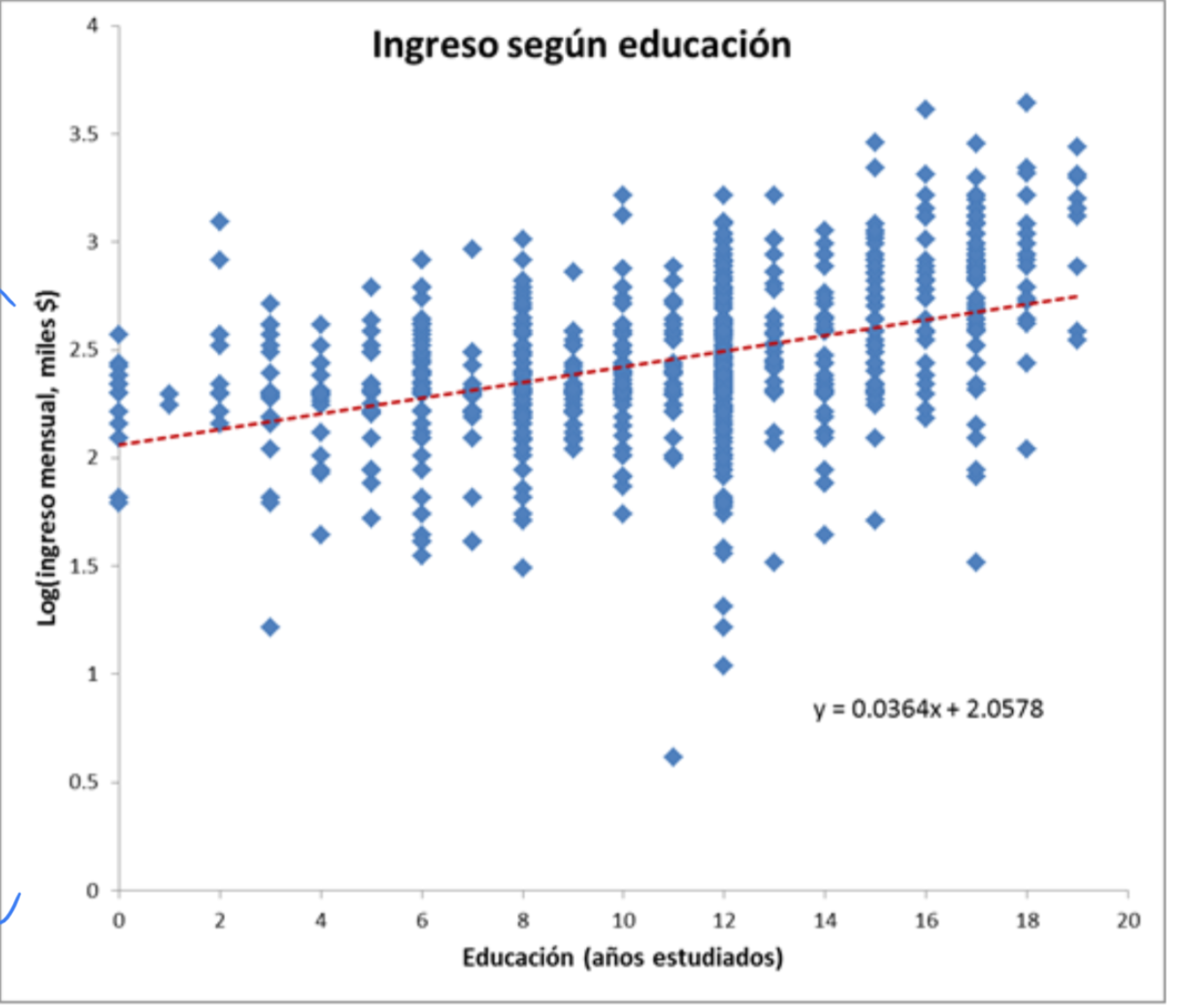
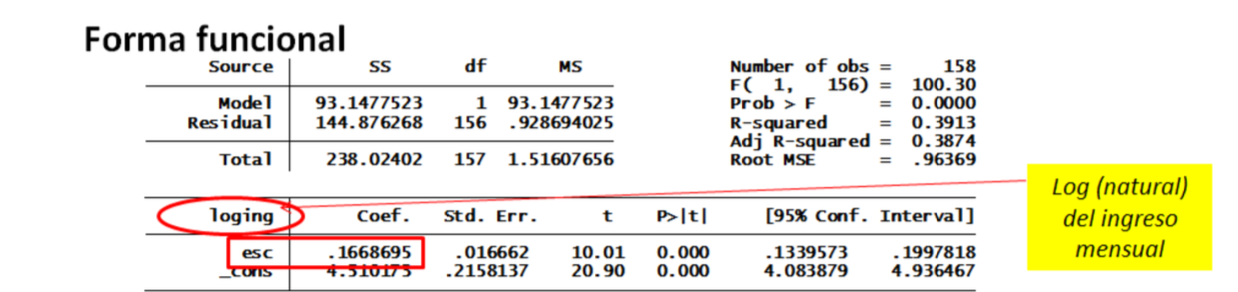
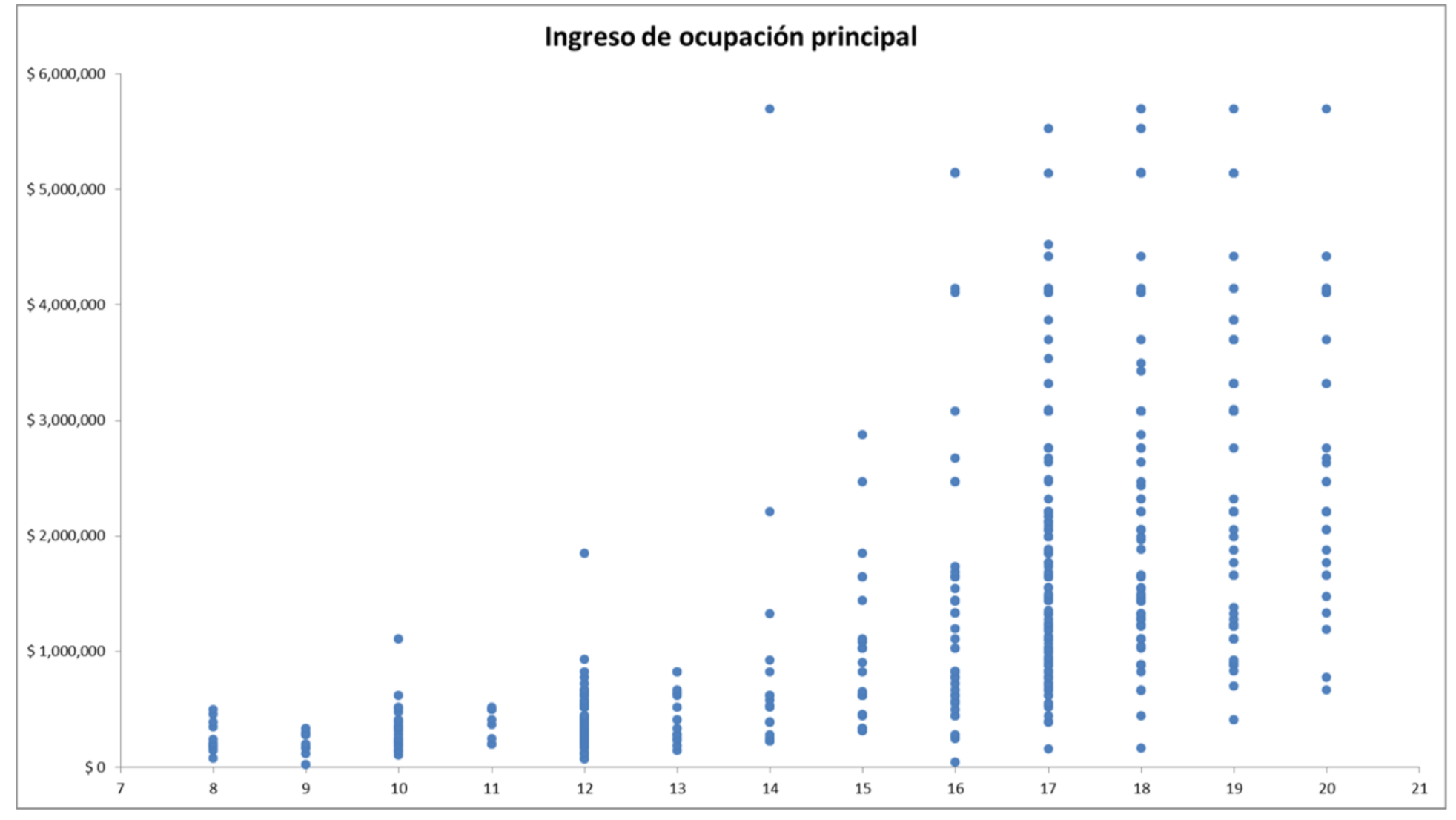
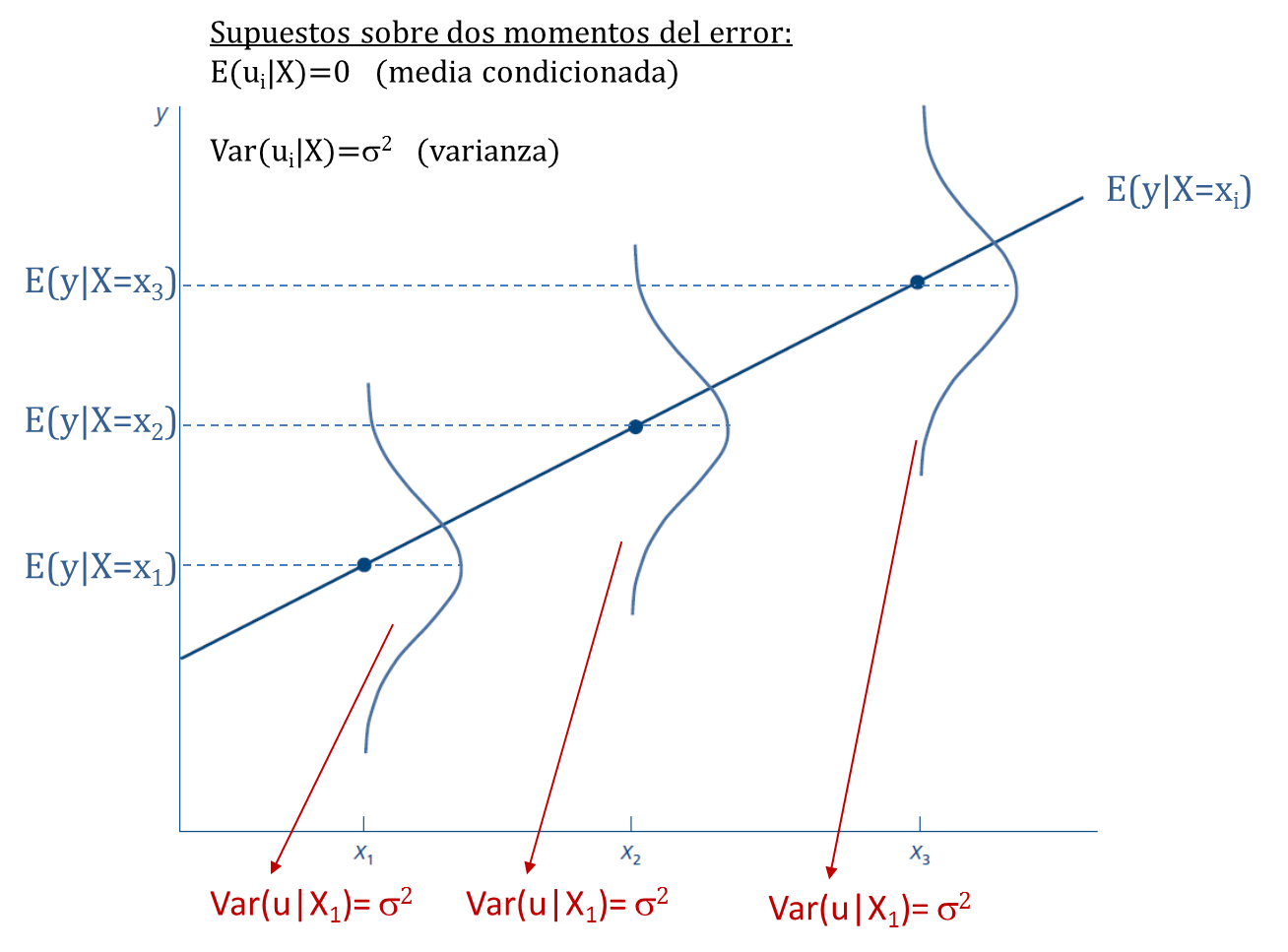
Especificación
\[
y_{i}=\hat{y}_{i}+\hat{u}_{i}
\]
\[
\begin{array}{lr}
y_{i}&= \hat{\beta}_{0}+\hat{\beta}_{1}x_{1i}+\hat{\beta}_{2}x_{2i}+\dots+\hat{\beta}_{k}x_{ki}+\hat{u}_{i}\\
\hat{u}_{i}&=y_{i}- \hat{\beta}_{0} - \hat{\beta}_{1}x_{1i} - \hat{\beta}_{2}x_{2i} - \dots+\hat{\beta}_{k}x_{ki}\\
\end{array}
\]
\[
\sum_{i=1}^{2}\hat{u}_{i}^{2}
\]
- Lo podemos expresar como:
\[
\min SRC= \hat{u}'\hat{u} = (y-X\hat{\beta})'(y-X\hat{\beta})
\]
- Obtengamos los estimadores de MCO en el modelo múltiple:
\[
SRC = \hat{u}'\hat{u}= (y-X\hat{\beta})'(y-X\hat{\beta})=y'y-y'X\hat{\beta}+(X\hat{\beta})'y+(X\hat{\beta})'X\hat{\beta}
\]
- Sacamos las derivadas y obtenemos los estimadores:
\[
\hat{\beta}=(X'X)^{-1}X'y
\]
Claro, puedo ayudarte con los pasos intermedios para obtener los estimadores de MCO en el modelo múltiple. A continuación, desglosaré estos pasos:
Dado el modelo de regresión lineal múltiple:
\[
y = \beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2}+\dots+\beta_{k}x_{k}+u
\]
Queremos encontrar los estimadores de Mínimos Cuadrados Ordinarios (MCO) para los coeficientes \(\beta_{0}, \beta_{1}, \beta_{2}, \ldots, \beta_{k}\). Estos estimadores minimizan la suma de los cuadrados de los residuos (SRC).
Primero, expresamos el SRC en términos de los residuos \(\hat{u}\) y los valores observados \(y\):
\[
SRC = \hat{u}'\hat{u}
\]
Luego, sustituimos los residuos \(\hat{u}\) con la diferencia entre los valores observados \(y\) y los valores ajustados \(\hat{y}\):
\[
SRC = (y - \hat{y})'(y - \hat{y})
\]
Ahora, expandimos esta expresión utilizando propiedades de matrices y transposición:
\[
SRC = (y - X\hat{\beta})'(y - X\hat{\beta})
\]
Continuamos expandiendo la expresión y simplificándola:
\[
SRC = (y'y - y'X\hat{\beta} - (\hat{\beta}'X'y) + (\hat{\beta}'X'X\hat{\beta}))
\]
Detalle matemático:
Dado el modelo de regresión lineal múltiple:
\[
y = \beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2}+\dots+\beta_{k}x_{k}+u
\]
Queremos encontrar los estimadores de Mínimos Cuadrados Ordinarios (MCO) para los coeficientes \(\beta_{0}, \beta_{1}, \beta_{2}, \ldots, \beta_{k}\).
Estos estimadores minimizan la suma de los cuadrados de los residuos (SRC).
Primero, expresamos el SRC en términos de los residuos \(\widehat{u}\) y los valores observados \(y\):
\[
SRC = \widehat{u}'\widehat{u}
\]
Luego, sustituimos los residuos \(\widehat{u}\) con la diferencia entre los valores observados \(y\) y los valores ajustados \(\widehat{y}\):
\[
SRC = (y - \widehat{y})'(y - \widehat{y})
\]
Ahora, expandimos esta expresión utilizando propiedades de matrices y transposición:
\[
SRC = (y - X\widehat{\beta})'(y - X\widehat{\beta})
\]
Continuamos expandiendo la expresión y simplificándola:
\[
SRC = (y'y - y'X\widehat{\beta} - (\widehat{\beta}'X'y) + (\widehat{\beta}'X'X\widehat{\beta}))
\]
Ahora, tomamos las derivadas parciales de SRC con respecto al vecor de coeficientes \(\beta\). Si no estuvieramos trabajando en forma matricial, tendriamos que hacerlo respecto a \(\beta_{0}, \beta_{1}, \beta_{2}, \ldots, \beta_{k}\) y los igualamos a cero para encontrar los estimadores de MCO.
En forma matricial es más sencillo de desarrollar:
\[
\partial SRC = -2y'X + 2\widehat{\beta}'X'X = 0
\]
Resolvemos para \(\widehat{\beta}\):
\[
2\widehat{\beta}'X'X = 2y'X
\]
\[
\widehat{\beta}'X'X = y'X
\]
\[
\widehat{\beta}' = y'X(X'X)^{-1}
\]
\[
\widehat{\beta} = (X'X)^{-1}X'y
\]
Esta fórmula nos da los estimadores de MCO para todos los coeficientes del modelo de regresión lineal múltiple.
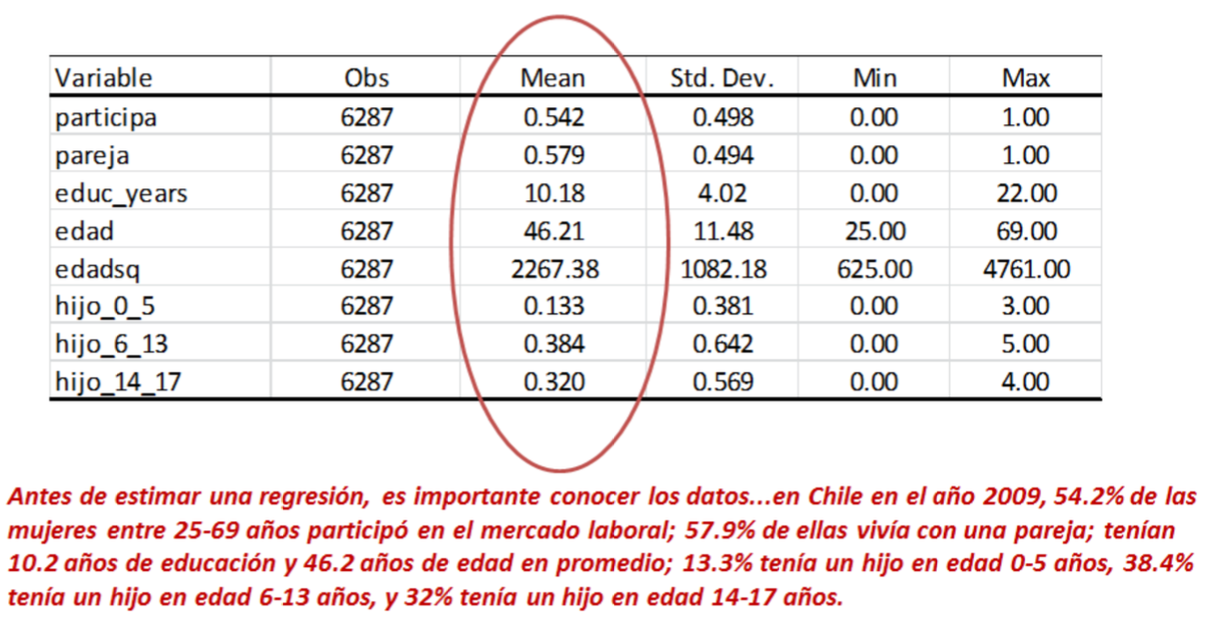
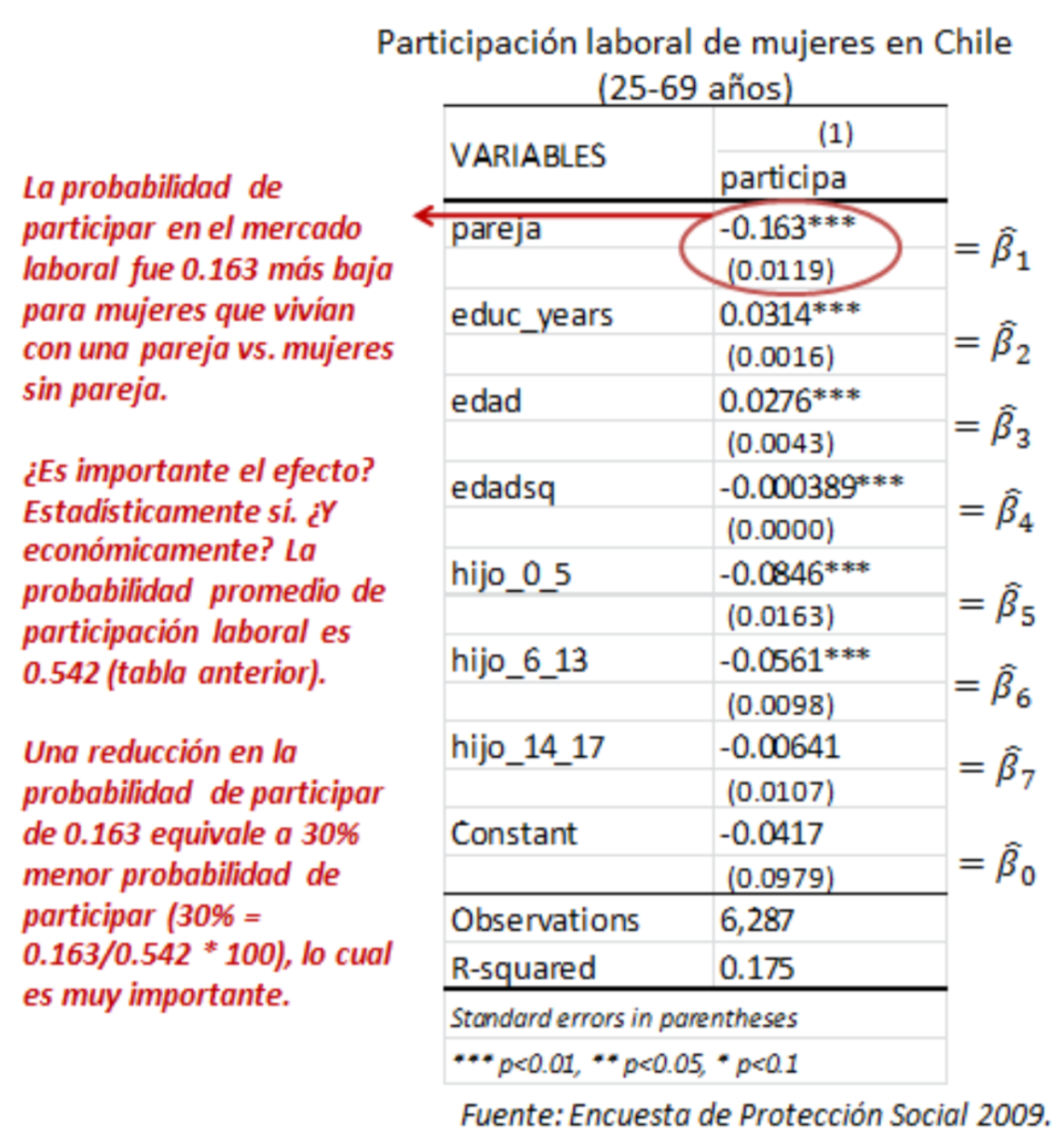
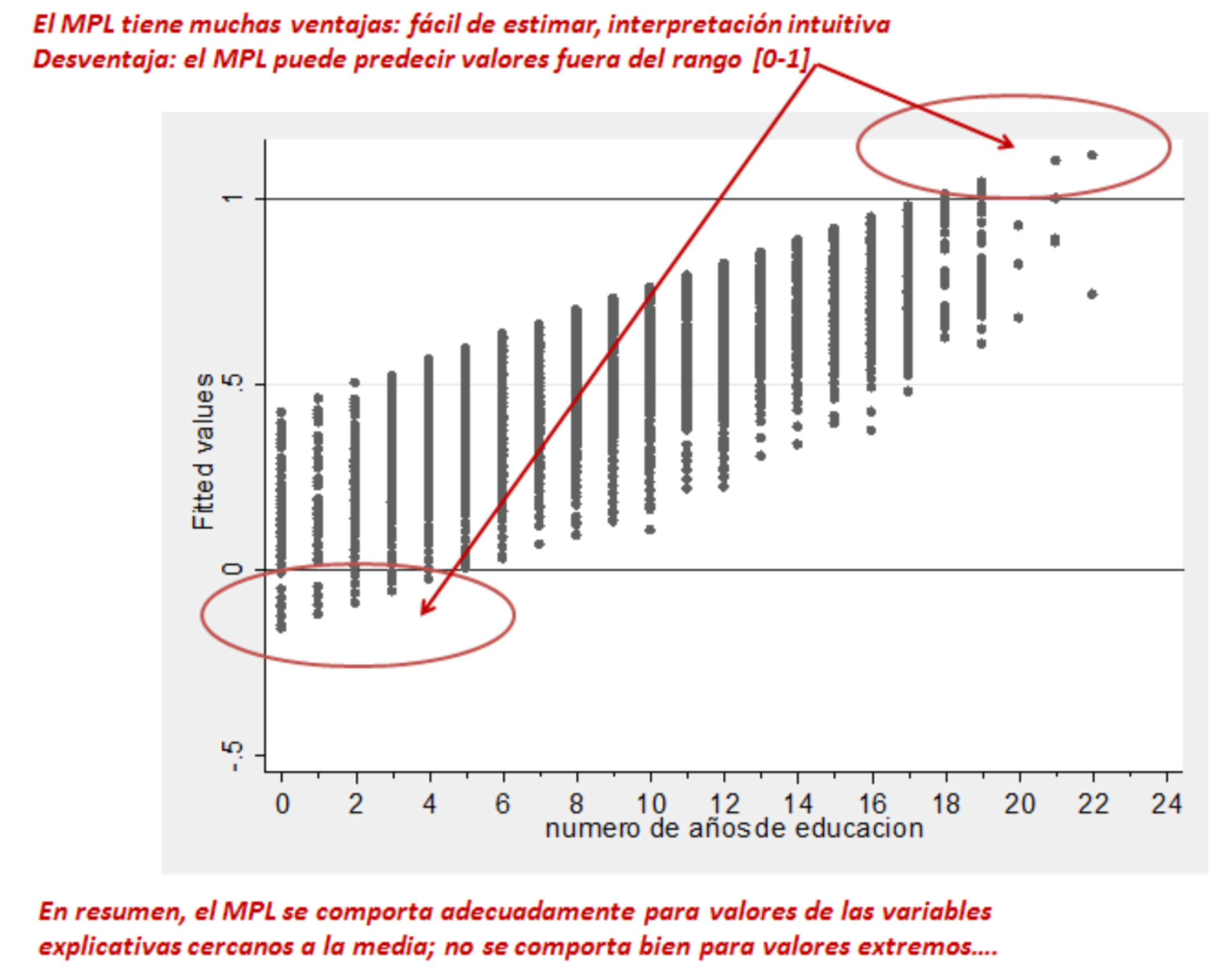
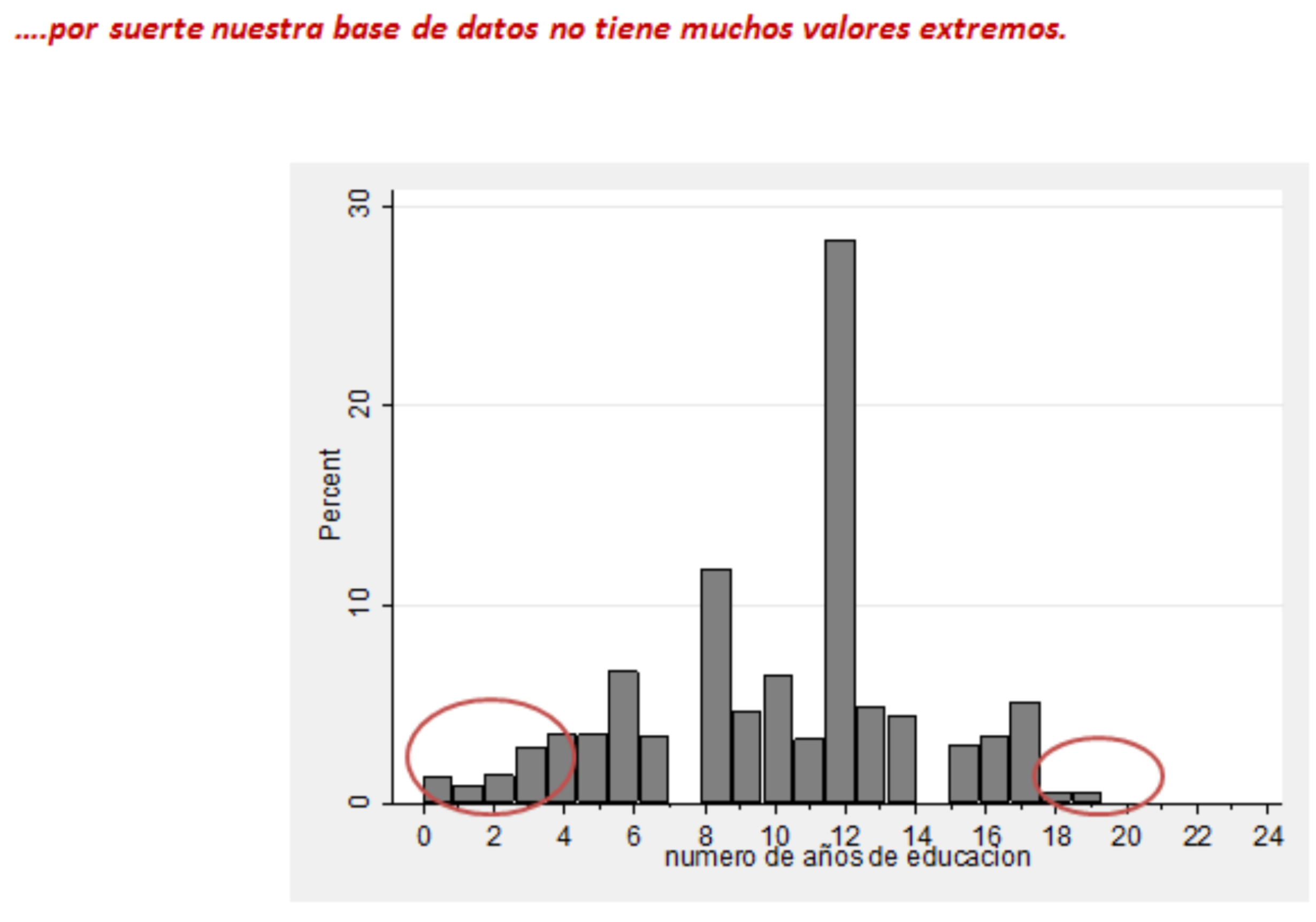
Ejemplo de Regresión Lineal Múltiple